





Z-Image Finetuned Models: многостильная, высококачественная генерация изображений в ComfyUI#
Этот рабочий процесс собирает Z-Image-Turbo и вращающуюся подборку донастроенных моделей Z-Image в единую, готовую к производству графику ComfyUI. Он предназначен для сравнения стилей бок о бок, поддержания согласованного поведения подсказок и получения четких, согласованных результатов с минимальными шагами. Под капотом он сочетает в себе оптимизированную загрузку UNet, нормализацию CFG, совместимую с AuraFlow выборку и опциональную инъекцию LoRA, чтобы вы могли исследовать реализм, кинематографические портреты, темное фэнтези и образы, вдохновленные аниме, без необходимости перенастраивать ваш холст.
Z-Image Finetuned Models идеально подходит для художников, инженеров подсказок и исследователей моделей, которые хотят быстро оценить несколько контрольных точек и LoRA, оставаясь в одной согласованной линии. Введите одну подсказку, отрендерьте четыре вариации из разных донастроек Z-Image и быстро выберите стиль, который лучше всего соответствует вашему заданию.
Ключевые модели в рабочем процессе Comfyui Z-Image Finetuned Models#
- Tongyi-MAI Z-Image-Turbo. Диффузионный трансформер с одним потоком на 6B параметров, дистиллированный для фотореалистичной генерации текста в изображение с сильной приверженностью инструкциям и двуязычным рендерингом текста. Официальные веса и примечания по использованию находятся на карточке модели, а технический отчет и методы дистилляции подробно описаны на arXiv и в репозитории проекта. Model • Paper • Decoupled-DMD • DMDR • GitHub • Diffusers pipeline
- BEYOND REALITY Z-Image (коммунальная донастройка). Контрольная точка Z-Image с уклоном в фотореализм, которая подчеркивает глянцевые текстуры, четкие края и стилизованную отделку, подходящую для портретов и композиций, похожих на продукты. Model
- Z-Image-Turbo-Realism LoRA (пример LoRA, используемый в этом рабочем процессе в линии LoRA). Легкий адаптер, который продвигает ультрареалистичное рендеринг, сохраняя базовое выравнивание подсказок Z-Image-Turbo; загружается без замены вашей базовой модели. Model
- Семейство AuraFlow (референс, совместимый с выборкой). Рабочий процесс использует крючки выборки в стиле AuraFlow для стабильных генераций с небольшим количеством шагов; смотрите справочник по конвейеру для информации о планировщиках AuraFlow и их целях дизайна. Docs
Как использовать рабочий процесс Comfyui Z-Image Finetuned Models#
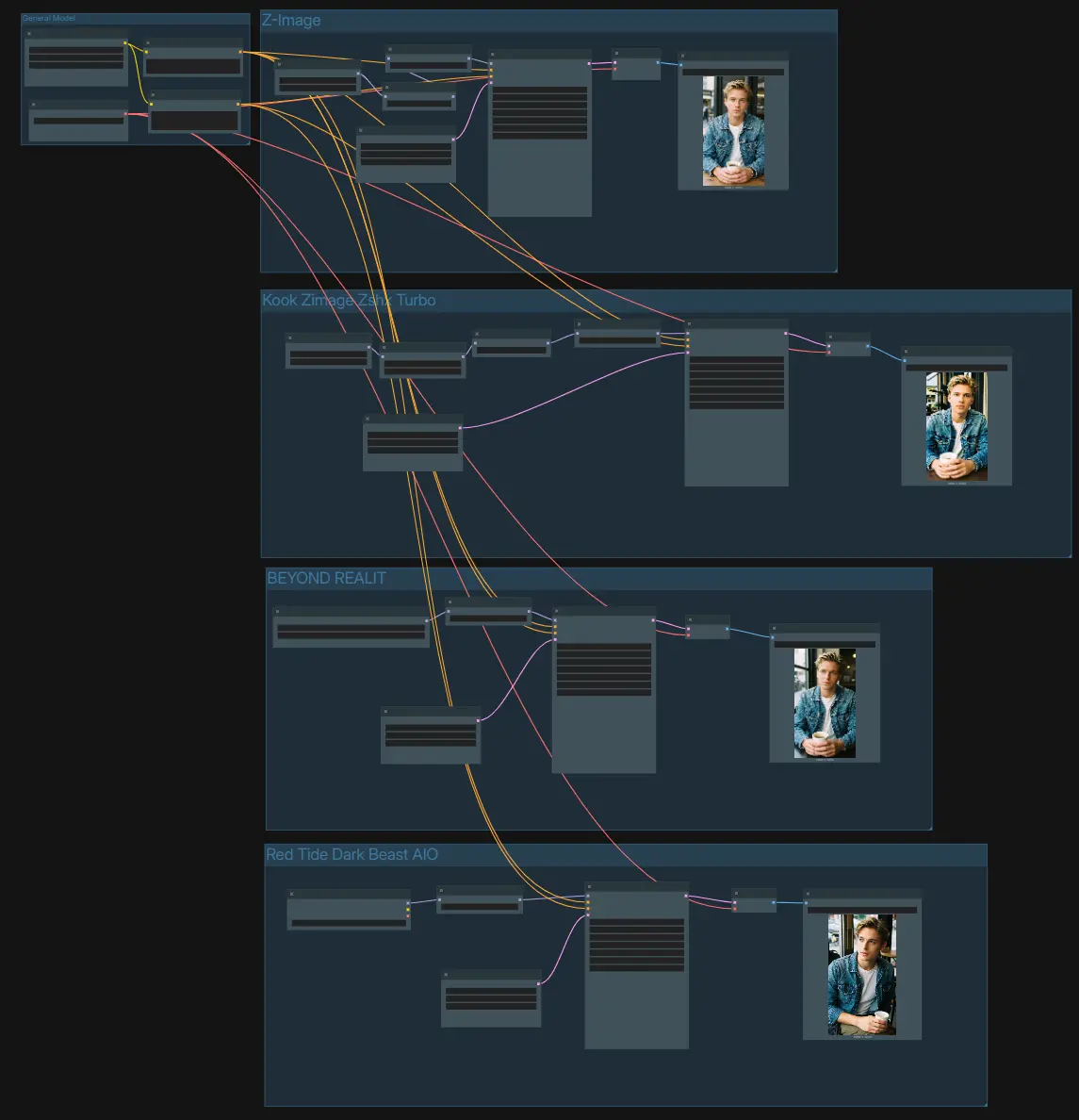
График организован в четыре независимые линии генерации, которые разделяют общий текстовый энкодер и VAE. Используйте одну подсказку, чтобы управлять всеми линиями, затем сравните результаты, сохраненные из каждой ветви.
- Общая модель
- Общая настройка загружает текстовый энкодер и VAE. Введите ваше описание в положительный
CLIPTextEncode(#75) и добавьте дополнительные ограничения в отрицательныйCLIPTextEncode(#74). Это сохраняет одинаковое условие через ветви, чтобы вы могли справедливо оценить, как каждая донастройка ведет себя.VAELoader(#21) предоставляет декодер, используемый всеми линиями для преобразования латентов обратно в изображения.
- Общая настройка загружает текстовый энкодер и VAE. Введите ваше описание в положительный
- Z-Image (Base Turbo)
- Эта линия запускает официальный Z-Image-Turbo UNet через
UNETLoader(#100) и патчирует его с помощьюModelSamplingAuraFlow(#76) для стабильности с небольшим количеством шагов.CFGNorm(#67) стандартизирует поведение руководства без классификатора, чтобы контраст и детали оставались предсказуемыми в разных подсказках.EmptyLatentImage(#19) определяет размер холста, затемKSampler(#78) генерирует латенты, которые декодируютсяVAEDecode(#79) и записываютсяSaveImage(#102). Используйте эту ветку в качестве базовой при оценке других моделей Z-Image Finetuned.
- Эта линия запускает официальный Z-Image-Turbo UNet через
- Z-Image-Turbo + Realism LoRA
- Эта линия инжектирует адаптер стиля с помощью
LoraLoaderModelOnly(#106) поверх базовойUNETLoader(#82).ModelSamplingAuraFlow(#84) иCFGNorm(#64) сохраняют выходные данные четкими, в то время как LoRA продвигает реализм без перегрузки предмета. Определите разрешение с помощьюEmptyLatentImage(#71), генерируйте с помощьюKSampler(#85), декодируйте черезVAEDecode(#86) и сохраняйте с помощьюSaveImage(#103). Если LoRA кажется слишком сильным, уменьшите его вес здесь, а не чрезмерно редактируйте вашу подсказку.
- Эта линия инжектирует адаптер стиля с помощью
- BEYOND REALITY донастройка
- Этот путь заменяет коммунальную контрольную точку с помощью
UNETLoader(#88), чтобы создать стилизованный, высококонтрастный вид.CFGNorm(#66) укрощает руководство, чтобы визуальный почерк оставался чистым, когда вы изменяете выборки или шаги. Установите ваш целевой размер вEmptyLatentImage(#72), отрендерьте с помощьюKSampler(#89), декодируйтеVAEDecode(#90), и сохраняйте черезSaveImage(#104). Используйте ту же подсказку, что и базовая линия, чтобы увидеть, как эта донастройка интерпретирует композицию и освещение.
- Этот путь заменяет коммунальную контрольную точку с помощью
- Red Tide Dark Beast AIO донастройка
- Контрольная точка, ориентированная на темное фэнтези, загружается с помощью
CheckpointLoaderSimple(#92), затем нормализуетсяCFGNorm(#65). Эта линия акцентирует внимание на мрачных цветовых палитрах и более тяжелом микроконтрасте, сохраняя хорошее соблюдение подсказок. Выберите вашу рамку вEmptyLatentImage(#73), генерируйте с помощьюKSampler(#93), декодируйте с помощьюVAEDecode(#94), и экспортируйте изSaveImage(#105). Это практичный способ тестировать более грубую эстетику в той же настройке Z-Image Finetuned Models.
- Контрольная точка, ориентированная на темное фэнтези, загружается с помощью
Ключевые узлы в рабочем процессе Comfyui Z-Image Finetuned Models#
ModelSamplingAuraFlow(#76, #84)- Цель: патчит модель для использования совместимого с AuraFlow пути выборки, который стабилен при очень низком количестве шагов. Контроль
shiftтонко регулирует траектории выборки; рассматривайте его как диск тонкой настройки, который взаимодействует с вашим выбором выборщика и бюджетом шагов. Для лучшей сравнимости между линиями сохраняйте тот же выборщик и регулируйте только одну переменную (например,shiftили вес LoRA) за тест. Справочник: фоновая информация и заметки по планированию AuraFlow. Docs
- Цель: патчит модель для использования совместимого с AuraFlow пути выборки, который стабилен при очень низком количестве шагов. Контроль
CFGNorm(#64, #65, #66, #67)- Цель: нормализует руководство без классификатора, чтобы контраст и детали не колебались резко, когда вы меняете модели, шаги или планировщики. Увеличьте его
strength, если блики теряются или текстуры кажутся несогласованными между линиями; уменьшите, если изображения начинают выглядеть чрезмерно сжатыми. Сохраняйте его похожим между ветками, когда хотите чистое A/B сравнение моделей Z-Image Finetuned.
- Цель: нормализует руководство без классификатора, чтобы контраст и детали не колебались резко, когда вы меняете модели, шаги или планировщики. Увеличьте его
LoraLoaderModelOnly(#106)- Цель: инжектирует адаптер LoRA непосредственно в загруженный UNet без изменения базовой контрольной точки. Параметр
strengthконтролирует стилистическое воздействие; более низкие значения сохраняют базовый реализм, в то время как более высокие значения навязывают вид LoRA. Если LoRA подавляет лица или типографику, сначала уменьшите его вес, затем уточните формулировку подсказок.
- Цель: инжектирует адаптер LoRA непосредственно в загруженный UNet без изменения базовой контрольной точки. Параметр
KSampler(#78, #85, #89, #93)- Цель: выполняет фактический диффузионный цикл. Выберите выборщик и планировщик, которые хорошо сочетаются с дистилляциями с небольшим количеством шагов; многие пользователи предпочитают выборщики в стиле Эйлера с равномерными или многошаговыми планировщиками для моделей класса Turbo. Сохраняйте семена фиксированными при сравнении линий и изменяйте только одну переменную за раз, чтобы понять, как каждая донастройка ведет себя.
Опциональные дополнения#
- Начните с одного описательного абзаца-подсказки и используйте его во всех линиях, чтобы оценить различия между моделями Z-Image Finetuned; изменяйте слова стиля только после того, как выберете любимую ветку.
- Для моделей класса Turbo очень низкий или даже нулевой CFG часто дает самые чистые результаты; используйте негативную подсказку только когда необходимо исключить конкретные элементы.
- Сохраняйте одинаковое разрешение, выборщик и семя при проведении A/B тестов; изменяйте вес LoRA или
shiftнебольшими шагами, чтобы изолировать причину и следствие. - Каждая ветка записывает свой собственный вывод; четыре узла
SaveImageимеют уникальные метки, чтобы вы могли быстро сравнивать и курировать.
Ссылки для дальнейшего чтения:
- Карточка модели Z-Image-Turbo: Tongyi-MAI/Z-Image-Turbo
- Технический отчет и методы: Z-Image • Decoupled-DMD • DMDR
- Репозиторий проекта: Tongyi-MAI/Z-Image
- Пример донастройки: Nurburgring/BEYOND_REALITY_Z_IMAGE
- Пример LoRA: Z-Image-Turbo-Realism-LoRA
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаем модели HuggingFace за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведенным ниже.
Ресурсы#
- Модели HuggingFace:
Примечание: использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.


