
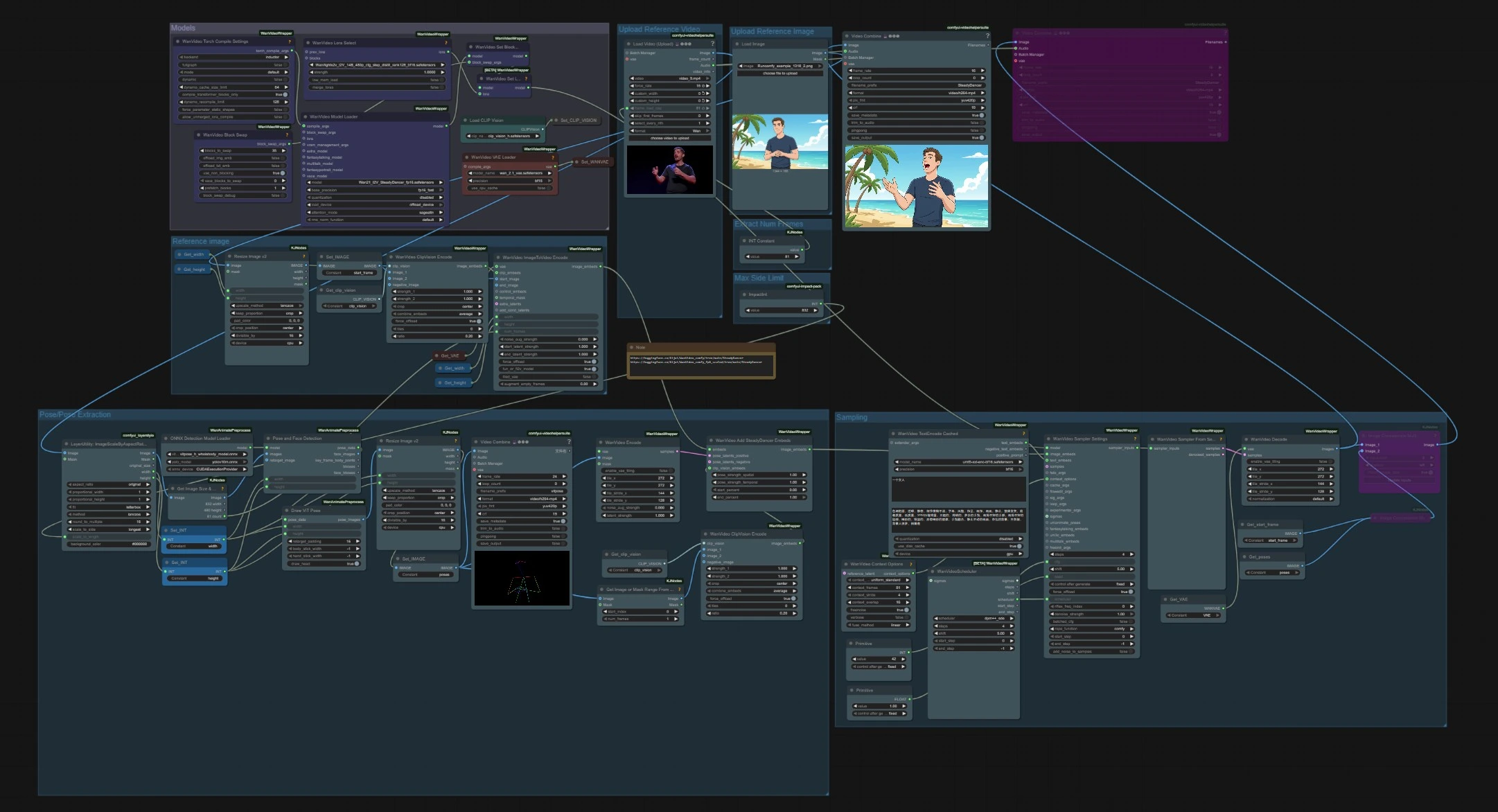
Рабочий процесс анимации поз SteadyDancer из изображений в видео#
Этот рабочий процесс ComfyUI превращает одно референсное изображение в последовательное видео, управляемое движением отдельного источника поз. Он построен на парадигме изображений в видео SteadyDancer, поэтому первый кадр сохраняет идентичность и внешний вид вашего входного изображения, а остальная часть последовательности следует за целевым движением. График согласует позу и внешний вид через специфические для SteadyDancer встраивания и конвейер поз, производя плавное, реалистичное движение всего тела с сильной временной согласованностью.
SteadyDancer идеально подходит для анимации человека, генерации танцев и оживления персонажей или портретов. Предоставьте одно неподвижное изображение и клип движения, и рабочий процесс ComfyUI обработает извлечение поз, встраивание, выборку и декодирование, чтобы предоставить готовое к распространению видео.
Ключевые модели в рабочем процессе SteadyDancer ComfyUI#
- SteadyDancer. Исследовательская модель для сохранения идентичности изображения в видео с механизмом согласования условий и синергетической модуляцией позы. Используется здесь как основной метод I2V. GitHub
- Wan 2.1 I2V SteadyDancer weights. Контрольные точки, портированные для ComfyUI, которые реализуют SteadyDancer на стеке Wan 2.1. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) и Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. Видео VAE, используемый для латентного кодирования и декодирования в конвейере. Включен в порт WanVideo на Hugging Face выше.
- OpenCLIP CLIP ViT‑H/14. Кодировщик изображений, который извлекает надежные встраивания внешнего вида из референсного изображения. Hugging Face
- ViTPose‑H WholeBody (ONNX). Высококачественная модель ключевых точек для тела, рук и лица, используемая для вывода последовательности движущихся поз. GitHub
- YOLOv10 (ONNX). Детектор, который улучшает локализацию человека перед оценкой поз на разнообразных видео. GitHub
- umT5‑XXL кодировщик. Опциональный текстовый кодировщик для стиля или руководства сценой вместе с референсным изображением. Hugging Face
Как использовать рабочий процесс SteadyDancer ComfyUI#
Рабочий процесс имеет два независимых входа, которые соединяются на этапе выборки: референсное изображение для идентичности и управляющее видео для движения. Модели загружаются один раз, поза извлекается из управляющего клипа, и встраивания SteadyDancer смешивают позу и внешний вид перед генерацией и декодированием.
Модели#
Эта группа загружает основные веса, используемые на протяжении всего графа. WanVideoModelLoader (#22) выбирает контрольную точку Wan 2.1 I2V SteadyDancer и управляет настройками внимания и точности. WanVideoVAELoader (#38) предоставляет видео VAE, а CLIPVisionLoader (#59) готовит основу видения CLIP ViT‑H. Узел выбора LoRA и параметры BlockSwap доступны для продвинутых пользователей, которые хотят изменить поведение памяти или подключить дополнительные веса.
Загрузить референсное видео#
Импортируйте источник движения, используя VHS_LoadVideo (#75). Узел читает кадры и аудио, позволяя вам установить целевую частоту кадров или ограничить количество кадров. Клип может быть любым движением человека, таким как танец или спортивное движение. Поток видео затем переходит к масштабированию соотношения сторон и извлечению поз.
Извлечь количество кадров#
Простая константа контролирует, сколько кадров загружается из управляющего видео. Это ограничивает как извлечение поз, так и длину генерируемого вывода SteadyDancer. Увеличьте его для более длинных последовательностей или уменьшите, чтобы быстрее выполнять итерации.
Ограничение максимальной стороны#
LayerUtility: ImageScaleByAspectRatio V2 (#146) масштабирует кадры, сохраняя соотношение сторон, чтобы они соответствовали шагу модели и бюджету памяти. Установите ограничение на длинную сторону, подходящее для вашего GPU и желаемого уровня детализации. Масштабированные кадры используются downstream узлами обнаружения и в качестве ссылки для размера вывода.
Извлечение поз#
Обнаружение людей и оценка поз выполняются на масштабированных кадрах. PoseAndFaceDetection (#89) использует YOLOv10 и ViTPose‑H для надежного нахождения людей и ключевых точек. DrawViTPose (#88) визуализирует чистое представление движения в виде палочек, а ImageResizeKJv2 (#77) изменяет размер полученных изображений поз, чтобы они соответствовали холсту генерации. WanVideoEncode (#72) преобразует изображения поз в латенты, чтобы SteadyDancer мог модулировать движение, не мешая сигналу внешнего вида.
Загрузить референсное изображение#
Загрузите изображение идентичности, которое вы хотите анимировать с помощью SteadyDancer. Изображение должно четко показывать объект, который вы хотите переместить. Используйте позу и угол камеры, которые в целом соответствуют управляющему видео, для наиболее точной передачи. Кадр передается в группу референсных изображений для встраивания.
Референсное изображение#
Неподвижное изображение изменяется с помощью ImageResizeKJv2 (#68) и регистрируется как начальный кадр с помощью Set_IMAGE (#96). WanVideoClipVisionEncode (#65) извлекает встраивания CLIP ViT‑H, которые сохраняют идентичность, одежду и грубую компоновку. WanVideoImageToVideoEncode (#63) упаковывает ширину, высоту и количество кадров с начальным кадром для подготовки условия I2V SteadyDancer.
Выборка#
Здесь внешний вид и движение встречаются для генерации видео. WanVideoAddSteadyDancerEmbeds (#71) получает условие изображения от WanVideoImageToVideoEncode и дополняет его латентами поз и ссылкой CLIP-vision, позволяя согласованию условий SteadyDancer. Контекстные окна и перекрытия устанавливаются в WanVideoContextOptions (#87) для временной согласованности. Опционально, WanVideoTextEncodeCached (#92) добавляет текстовое руководство umT5 для стиля. WanVideoSamplerSettings (#119) и WanVideoSamplerFromSettings (#129) выполняют фактические шаги удаления шума на модели Wan 2.1, после чего WanVideoDecode (#28) преобразует латенты обратно в RGB кадры. Финальные видео сохраняются с помощью VHS_VideoCombine (#141, #83).
Ключевые узлы в рабочем процессе SteadyDancer ComfyUI#
WanVideoAddSteadyDancerEmbeds (#71)#
Этот узел является сердцем графа SteadyDancer. Он соединяет условие изображения с латентами поз и подсказками CLIP-vision, так что первый кадр фиксирует идентичность, а движение разворачивается естественно. Настройте pose_strength_spatial, чтобы контролировать, насколько плотно конечности следуют за обнаруженным скелетом, и pose_strength_temporal, чтобы регулировать плавность движения во времени. Используйте start_percent и end_percent, чтобы ограничить, где применяется контроль позы в последовательности для более естественных вступлений и завершений.
PoseAndFaceDetection (#89)#
Запускает обнаружение YOLOv10 и оценку ключевых точек ViTPose‑H на управляющем видео. Если позы пропускают небольшие конечности или лица, увеличьте разрешение входа upstream или выберите кадры с меньшими перекрытиями и более чистым освещением. Когда присутствуют несколько людей, держите целевой объект самым крупным в кадре, чтобы детектор и головка позы оставались стабильными.
VHS_LoadVideo (#75)#
Контролирует, какую часть источника движения вы используете. Увеличьте ограничение кадров для более длительных выходов или уменьшите его, чтобы быстро создавать прототипы. Вход force_rate выравнивает пространение поз с частотой генерации и может помочь уменьшить заикание, когда FPS оригинального клипа необычен.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
Держит кадры в пределах выбранного ограничения по длинной стороне, сохраняя соотношение сторон и распределяя их до делимого размера. Соответствуйте масштабу здесь с холстом генерации, чтобы SteadyDancer не нужно было агрессивно увеличивать или обрезать. Если вы видите мягкие результаты или артефакты на краях, приблизьте длинную сторону к родному масштабу тренировки модели для более чистого декодирования.
WanVideoSamplerSettings (#119)#
Определяет план удаления шума для сэмплера Wan 2.1. scheduler и steps устанавливают общее качество в сравнении со скоростью, в то время как cfg балансирует приверженность изображению плюс подсказка против разнообразия. seed блокирует воспроизводимость, а denoise_strength можно уменьшить, когда вы хотите еще ближе к внешнему виду референсного изображения.
WanVideoModelLoader (#22)#
Загружает контрольную точку Wan 2.1 I2V SteadyDancer и управляет точностью, реализацией внимания и размещением устройств. Оставьте эти настройки как сконфигурированы для стабильности. Продвинутые пользователи могут подключить I2V LoRA для изменения поведения движения или снижения вычислительных затрат при экспериментах.
Дополнительные возможности#
- Выберите четкое, хорошо освещенное референсное изображение. Виды анфас или слегка под углом, которые напоминают камеру управляющего видео, делают сохранение идентичности SteadyDancer более надежным.
- Предпочитайте клипы движения с одним заметным объектом и минимальным перекрытием. Загруженные фоны или быстрые смены кадров снижают стабильность поз.
- Если руки и ноги дрожат, слегка увеличьте временную силу поз в
WanVideoAddSteadyDancerEmbedsили увеличьте FPS видео, чтобы уплотнить позы. - Для более длинных сцен обрабатывайте в сегментах с перекрывающимся контекстом и сшивайте выводы. Это сохраняет разумное использование памяти и поддерживает временную непрерывность.
- Используйте встроенные мозаики предварительного просмотра, чтобы сравнить сгенерированные кадры с начальным кадром и последовательностью поз, пока вы настраиваете параметры.
Этот рабочий процесс SteadyDancer предоставляет вам практический, полный путь от одного неподвижного изображения до верного, управляемого позой видео с сохранением идентичности с самого первого кадра.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы искренне благодарим MCG-NJU за SteadyDancer за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
