
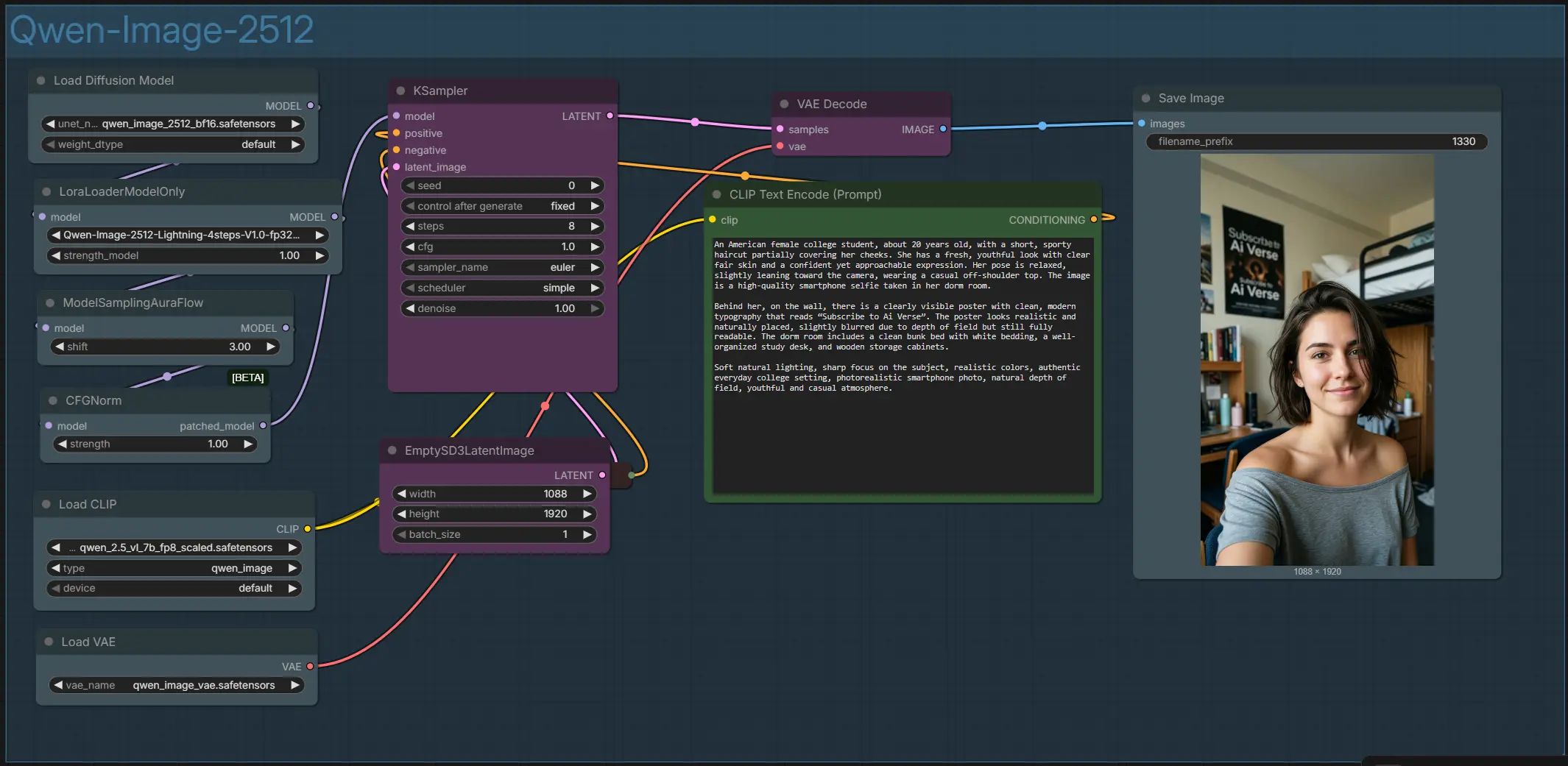






Рабочий процесс Qwen Image 2512 ComfyUI для портретов и сцен с точным текстом#
Этот рабочий процесс преобразует ваш запрос в высококачественное изображение с использованием Qwen Image 2512. Он разработан для создателей, которым нужна сильная привязка текста к изображению, реалистичные люди и надежное двуязычное рендеринг текста внутри сцены. График предварительно настроен с VAE и текстовым кодировщиком Qwen, а также с опциональным Lightning LoRA для генерации за несколько шагов, так что вы можете перейти от запроса к результату с минимальной настройкой.
Используйте его для концепт-арта, иллюстраций, вывесок, плакатов и повседневных фотостилей. Qwen Image 2512 обеспечивает стабильную композицию и четкую типографику, что делает его надежным выбором для запросов, которые смешивают людей, окружение и читаемый текст.
Основные модели в рабочем процессе Comfyui Qwen Image 2512#
- Основная модель Qwen-Image 2512 (bfloat16). Основная диффузионная модель, которая синтезирует изображение из условий. Готовые для Comfy веса предоставляются в пакете Comfy-Org. Файлы модели
- Текстовый кодировщик Qwen2.5-VL 7B. Кодирует ваш запрос в векторы условий, которые управляют макетом, стилем и рендерингом текста Qwen Image 2512. Файлы текстового кодировщика
- Qwen Image VAE. Декодирует латентное изображение, созданное семплером, обратно в RGB изображение с точной цветопередачей и детализацией. Файл VAE
- Qwen-Image-2512-Lightning-4steps-V1.0 LoRA (опционально). Сообщество LoRA, настроенное для генерации за несколько шагов, чтобы ускорить рендеринг с незначительными уступками в качестве. LoRA карта
- Для информации о семействе моделей и подходе к обучению см. технический отчет Qwen-Image. Статья
Как использовать рабочий процесс Comfyui Qwen Image 2512#
Общий поток: ваш запрос кодируется, создается латентный холст с выбранным разрешением, стек моделей применяет базовую модель и опциональную LoRA, семплер итеративно улучшает латентное изображение, и VAE декодирует финальное изображение для сохранения.
- Обзор группы Qwen-Image-2512
- Весь график организован в одной группе под названием "Qwen-Image-2512." Он соединяет текстовый кодировщик, стек моделей и LoRA, вспомогательные средства семплинга и декодирование VAE. Вы контролируете внешний вид с помощью положительных и отрицательных запросов, размера холста и нескольких настроек семплера. Выходное изображение — это высококачественное портретное изображение, сохраненное в вашей папке вывода ComfyUI.
- Запросы с
CLIPTextEncode(#52) и опциональными негативамиCLIPTextEncode(#32)- Введите ваше основное описание в
CLIPTextEncode(#52). Напишите сцену, объекты и любой текст, который вы хотите отобразить; Qwen Image 2512 особенно силен в вывесках, плакатах, макетах UI и двуязычных подписях. ИспользуйтеCLIPTextEncode(#32) для опциональных негативов, чтобы избежать артефактов или нежелательных стилей. Держите текстовые фрагменты в кавычках, если вам нужно точное формулирование.
- Введите ваше основное описание в
- Холст и соотношение сторон с
EmptySD3LatentImage(#57)- Выберите желаемую ширину и высоту, чтобы задать композицию. Портретные форматы хорошо подходят для людей и селфи, в то время как квадратные и ландшафтные соотношения подходят для продуктов и макетов сцен. Большие холсты дают более детализированные изображения за счет памяти и времени; начните скромно, затем увеличивайте, когда вам понравится кадрирование. Согласованность улучшается, когда вы сохраняете одно и то же соотношение сторон на протяжении всех итераций.
- Стек моделей и LoRA с
UNETLoader(#100) иLoraLoaderModelOnly(#101)- Основной генератор — это Qwen Image 2512, загруженный с помощью
UNETLoader(#100). Если вы хотите более быстрый рендеринг, включите Lightning LoRA вLoraLoaderModelOnly(#101), чтобы переключиться на рабочий процесс за несколько шагов. Этот стек задает возможности модели по реалистичности, макету и привязке текста к изображению перед началом семплинга.
- Основной генератор — это Qwen Image 2512, загруженный с помощью
- Вспомогательные средства семплинга с
ModelSamplingAuraFlow(#43) иCFGNorm(#55)- Эти две ноды подготавливают модель для стабильного, сбалансированного по контрасту семплинга.
ModelSamplingAuraFlow(#43) настраивает расписание, чтобы сохранить детали четкими, не перегружая текстуры.CFGNorm(#55) нормализует руководство, чтобы поддерживать консистентность цвета и экспозиции, следуя вашему запросу.
- Эти две ноды подготавливают модель для стабильного, сбалансированного по контрасту семплинга.
- Удаление шума и доработка с
KSampler(#54)- Это основная стадия, которая итеративно улучшает латентное изображение от шума до когерентного. Вы задаете seed для повторяемости, выбираете семплер и планировщик, а также решаете, сколько шагов выполнять. С включенным Lightning вы можете стремиться к малому количеству шагов; с одной базовой моделью используйте больше шагов для максимальной точности.
- Декодирование и сохранение с
VAEDecode(#45) иSaveImage(#117)- После семплинга VAE аккуратно восстанавливает RGB из латентного изображения, а
SaveImageзаписывает финальный PNG. Если цвета или контрастность выглядят неправильно, пересмотрите руководство или формулировку запроса, а не постобработку; Qwen Image 2512 хорошо реагирует на описательные подсказки освещения и материала.
- После семплинга VAE аккуратно восстанавливает RGB из латентного изображения, а
Основные ноды в рабочем процессе Comfyui Qwen Image 2512#
UNETLoader(#100)- Загружает базовую модель Qwen-Image-2512, которая определяет общие возможности и пространство стиля. Используйте сборку bf16 для максимального качества, если ваш GPU позволяет. Переключайтесь на вариант fp8 или сжатый только если вам нужно вписаться в память или увеличить пропускную способность.
LoraLoaderModelOnly(#101)- Применяет Qwen-Image-2512-Lightning-4steps-V1.0 LoRA поверх базовой модели. Повышайте или понижайте
strength_model, чтобы смешивать настройку скорости с базовой точностью, или установите его в 0, чтобы отключить. Когда эта LoRA активна, уменьшитеstepsвKSamplerдо нескольких итераций, чтобы реализовать ускорение.
- Применяет Qwen-Image-2512-Lightning-4steps-V1.0 LoRA поверх базовой модели. Повышайте или понижайте
ModelSamplingAuraFlow(#43)- Патчирует поведение семплинга модели для расписания в стиле потока, которое часто дает более четкие края и меньше размазываний. Если результаты выглядят чрезмерно резкими или недостаточно детализированными, слегка подвиньте параметр
shiftи пересэмплируйте. Держите другие переменные стабильными, пока тестируете, чтобы изолировать эффект.
- Патчирует поведение семплинга модели для расписания в стиле потока, которое часто дает более четкие края и меньше размазываний. Если результаты выглядят чрезмерно резкими или недостаточно детализированными, слегка подвиньте параметр
CFGNorm(#55)- Нормализует руководство без классификатора, чтобы предотвратить выцветание или чрезмерную насыщенность выходных данных. Используйте
strength, чтобы решить, насколько уверенно должна действовать нормализация. Если точность текста падает, когда вы увеличиваете CFG, увеличьте силу нормализации вместо того, чтобы увеличивать CFG.
- Нормализует руководство без классификатора, чтобы предотвратить выцветание или чрезмерную насыщенность выходных данных. Используйте
EmptySD3LatentImage(#57)- Задает размер латентного холста, определяющий кадрирование и соотношение сторон. Для людей портретные соотношения уменьшают искажения и помогают с пропорциями тела; для плакатов квадратные или ландшафтные соотношения подчеркивают макет и текстовые блоки. Увеличивайте разрешение только после того, как вы довольны композицией.
CLIPTextEncode(#52) иCLIPTextEncode(#32)- Положительный кодировщик (#52) превращает ваше описание в условия, включая явные текстовые строки для рендеринга в сцене. Отрицательный кодировщик (#32) подавляет нежелательные черты, такие как артефакты, лишние пальцы или шумные фоны. Держите запросы краткими и фактическими для лучшего выравнивания.
KSampler(#54)- Управляет seed, семплером, планировщиком, шагами, CFG и силой удаления шума. С Qwen Image 2512 умеренные значения CFG обычно сохраняют сильную привязку текста модели; если буквы деформируются, уменьшите CFG перед изменением семплера. Для быстрых черновиков включите Lightning и попробуйте очень мало шагов, затем увеличьте шаги для финальных рендеров, если нужно.
VAELoader(#34) иVAEDecode(#45)- Загружает и применяет VAE Qwen для восстановления точной цветопередачи и мелких деталей. Держите VAE в паре с базовой моделью, чтобы избежать смещения цвета. Если вы переключаете базовые веса, также переключитесь на соответствующую сборку VAE.
Опциональные дополнения#
- Запросы для текста в изображении
- Поместите точные слова в прямые кавычки и добавьте краткие подсказки по типографике, такие как "чистая современная типографика" или "жирный шрифт без засечек." Включите подсказки по размещению, такие как "плакат на стене" или "вывеска на витрине," чтобы указать, где должен появиться текст.
- Быстрая итерация с Lightning
- Включите Lightning LoRA и используйте несколько шагов для предварительных просмотров. После того как кадрирование и формулировка корректны, отключите или уменьшите силу LoRA и увеличьте шаги для восстановления максимальной точности.
- Выбор соотношения сторон
- Придерживайтесь согласованных соотношений во всех вариациях. Используйте портретное для людей, квадратное для продуктов или логотипов, а ландшафтное для окружения или слайдов. Если вы увеличиваете масштаб позже, сохраняйте то же соотношение, чтобы сохранить композицию.
- Дисциплина в руководстве
- Qwen Image 2512 обычно предпочитает умеренный CFG. Если точность текста снижается, уменьшите CFG или увеличьте силу
CFGNormвместо того, чтобы добавлять больше руководства.
- Qwen Image 2512 обычно предпочитает умеренный CFG. Если точность текста снижается, уменьшите CFG или увеличьте силу
- Воспроизводимость
- Зафиксируйте seed, когда вам нравится результат, чтобы вы могли безопасно повторять. Изменяйте один элемент управления за раз, чтобы понять его влияние, прежде чем двигаться дальше.
Признания#
Этот рабочий процесс реализует и развивает следующие работы и ресурсы. Мы искренне благодарим Comfy-Org за Qwen Image 2512 Model Files за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведенным ниже.
Ресурсы#
- Comfy-Org/Qwen Image 2512 Model Files
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- Документы / Заметки о выпуске: Qwen Image 2512 Model Files
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.