
LTX-2 ComfyUI: текст, изображение, глубина и поза в видео в реальном времени с синхронизированным звуком#
Этот универсальный рабочий процесс LTX-2 ComfyUI позволяет генерировать и итеративно улучшать короткие видео со звуком за считанные секунды. Он поставляется с маршрутами для "text to video" (T2V), "image to video" (I2V), "depth to video", "pose to video" и "canny to video", так что вы можете начать с подсказки, неподвижного изображения или структурированного руководства и сохранить тот же творческий цикл.
Основан на низколатентной аудиовизуальной pipeline LTX-2 и параллелизме последовательностей на нескольких GPU, график акцентирует внимание на быстрой обратной связи. Опишите движение, камеру, внешний вид и звук один раз, затем отрегулируйте ширину, высоту, количество кадров или управляйте LoRA, чтобы уточнить результат без переподключения чего-либо.
Примечание: Примечание о совместимости рабочего процесса LTX-2 — LTX-2 включает 5 рабочих процессов: Text-to-Video и Image-to-Video работают на всех типах машин, в то время как Depth to Video, Canny to Video и Pose to Video требуют 2X-Large машины или больше; запуск этих ControlNet рабочих процессов на меньших машинах может привести к ошибкам.
Основные модели в рабочем процессе LTX-2 ComfyUI#
- Контрольная точка LTX-2 19B (dev FP8). Основная аудиовизуальная генеративная модель, которая производит видеокадры и синхронизированный звук из мультимодального кондиционирования. Lightricks/LTX-2
- Контрольная точка LTX-2 19B Distilled. Легкий, быстрый вариант, полезный для быстрых черновиков или управляемых canny запусков. Lightricks/LTX-2
- Кодировщик текста Gemma 3 12B IT. Основная текстовая основа понимания, используемая кодировщиками подсказок рабочего процесса. Comfy-Org/ltx-2 split files
- LTX-2 Spatial Upscaler x2. Латентный апскейлер, который удваивает пространственные детали в середине графика для более чистых выходных данных. Lightricks/LTX-2
- LTX-2 Audio VAE. Кодирует и декодирует аудиолатенты, чтобы звук можно было генерировать и смешивать вместе с видео. Включен в выпуск LTX-2 выше.
- Lotus Depth D v1‑1. Depth UNet, используемый для получения надежных карт глубины из изображений перед генерацией видео с управлением глубиной. Comfy‑Org/lotus
- SD VAE (MSE, EMA pruned). VAE, используемый в ветке предварительной обработки глубины. stabilityai/sd-vae-ft-mse-original
- Управляющие LoRA для LTX‑2. Дополнительные, подключаемые LoRA для управления движением и структурой:
Как использовать рабочий процесс LTX-2 ComfyUI#
График содержит пять маршрутов, которые вы можете запускать независимо. Все маршруты используют один и тот же путь экспорта и используют одну и ту же логику от подсказки к кондиционированию, так что, изучив один, остальные кажутся знакомыми.
T2V: генерация видео и аудио из подсказки#
Путь T2V начинается с CLIP Text Encode (Prompt) (#3) и необязательной негативной в CLIP Text Encode (Prompt) (#4). LTXVConditioning (#22) связывает ваш текст и выбранную частоту кадров с моделью. EmptyLTXVLatentVideo (#43) и LTX LTXV Empty Latent Audio (#26) создают видеолатенты и аудиолатенты, которые объединяются LTX LTXV Concat AV Latent (#28). Цикл удаления шума проходит через LTXVScheduler (#9) и SamplerCustomAdvanced (#41), после чего VAE Decode (#12) и LTX LTXV Audio VAE Decode (#14) производят кадры и аудио. Video Combine 🎥🅥🅗🅢 (#15) сохраняет H.264 MP4 с синхронизированным звуком.
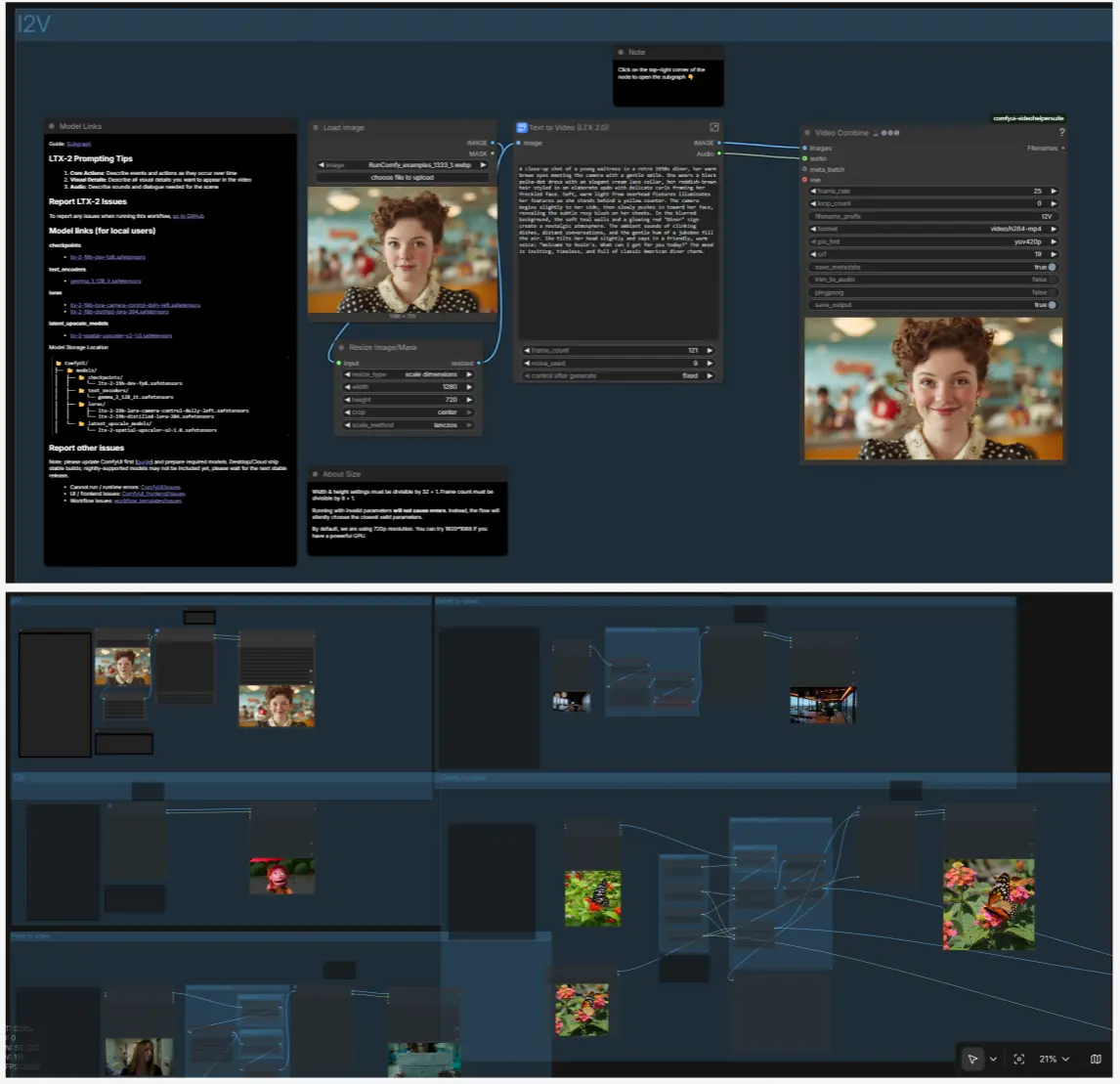
I2V: анимация неподвижного изображения#
Загрузите неподвижное изображение с помощью LoadImage (#98) и измените размер с помощью ResizeImageMaskNode (#99). Внутри подграфа T2V, LTX LTXV Img To Video Inplace вводит первый кадр в латентную последовательность, чтобы движение строилось из вашего неподвижного изображения, а не из чистого шума. Сосредоточьте свою текстовую подсказку на движении, камере и атмосфере; содержимое исходит из изображения.
Глубина в видео: движение с учетом структуры из карт глубины#
Используйте предварительный процессор "Image to Depth Map (Lotus)" для преобразования входного изображения в изображение глубины, декодированное VAEDecode и при необходимости инвертированное для правильной полярности. Маршрут "Depth to Video (LTX 2.0)" затем передает руководство по глубине через LTX LTXV Add Guide, чтобы модель уважала глобальную структуру сцены при анимации. Путь повторно использует те же этапы планировщика, сэмплера и апскейлера и заканчивается декодированием в плитки изображений и смешанным аудио для экспорта.
Поза в видео: управление движением из позы человека#
Импортируйте клип с помощью VHS_LoadVideo (#198); DWPreprocessor (#158) надежно оценивает позу человека на протяжении кадров. Подграф "Pose to Video (LTX 2.0)" объединяет вашу подсказку, кондиционирование позы и необязательный Pose Control LoRA, чтобы сохранить согласованность конечностей, ориентации и ритма, позволяя стилю и фону течь из текста. Используйте это для танцев, простых трюков или съемок "говори в камеру", где важно время тела.
Канни в видео: анимация с верностью краям и режимом дистиллированной скорости#
Передайте кадры в Canny (#169), чтобы получить стабильную карту краев. Ветвь "Canny to Video (LTX 2.0)" принимает края плюс необязательный Canny Control LoRA для высокой точности силуэтов, в то время как "Canny to Video (LTX 2.0 Distilled)" предлагает более быстрый дистиллированный контрольный пункт для быстрых итераций. Оба варианта позволяют по желанию ввести первый кадр и выбрать силу изображения, затем экспортировать через CreateVideo или VHS_VideoCombine.
Настройки видео и экспорт#
Установите ширину и высоту через Width (#175) и height (#173), общее количество кадров с помощью Frame Count (#176) и переключите Enable First Frame (#177), если хотите зафиксировать исходный эталон. Используйте узлы VHS_VideoCombine в конце каждого маршрута для управления crf, frame_rate, pix_fmt и сохранения метаданных. Предусмотрен специальный SaveVideo (#180) для дистиллированного маршрута канни, когда вы предпочитаете прямой ВЫВОД ВИДЕО.
Производительность и много-GPU#
График применяет LTXVSequenceParallelMultiGPUPatcher (#44) с включенной torch_compile для разделения последовательностей по GPU для снижения задержки. KSamplerSelect (#8) позволяет выбрать между сэмплерами, включая стили Эйлера и оценки градиента; меньшее количество кадров и меньше шагов сокращают время обработки, чтобы вы могли быстро итеративно улучшать и масштабировать, когда будете удовлетворены.
Основные узлы в рабочем процессе LTX-2 ComfyUI#
LTX Multimodal Guider(#17). Координирует, как текстовое кондиционирование управляет ветвями видео и аудио. Настройтеcfgиmodalityв связанныхLTX Guider Parameters(#18 для VIDEO, #19 для AUDIO), чтобы сбалансировать точность и креативность; увеличьтеcfgдля более строгого соблюдения подсказок и увеличьтеmodality_scale, чтобы подчеркнуть определенную ветвь.LTXVScheduler(#9). Создает расписание сигм, адаптированное к латентному пространству LTX-2. Используйтеsteps, чтобы обменивать скорость на качество; при прототипировании меньше шагов сокращают задержку, затем увеличивайте шаги для финальных рендеров.SamplerCustomAdvanced(#41). Деноизер, связывающийRandomNoise, выбранный сэмплер изKSamplerSelect(#8), сигмы планировщика и AV латент. Переключайте сэмплеры для различных текстур движения и поведения сходимости.LTX LTXV Img To Video Inplace(см. ветви I2V, например, #107). Вводит изображение в видеолатент, чтобы первый кадр закреплял содержимое, в то время как модель синтезирует движение. Настройтеstrength, чтобы определить, насколько строго сохраняется первый кадр.LTX LTXV Add Guide(в управляемых маршрутах, например, глубина/поза/канни). Добавляет структурное руководство (изображение, поза или края) непосредственно в латентное пространство. Используйтеstrength, чтобы сбалансировать точность руководства и творческую свободу и включите первый кадр только тогда, когда хотите временное закрепление.Video Combine 🎥🅥🅗🅢(#15 и его аналоги). Упаковывает декодированные кадры и сгенерированное аудио в MP4. Для предварительных просмотров увеличьтеcrf(больше сжатия); для финалов уменьшитеcrfи подтвердите, чтоframe_rateсоответствует тому, что вы установили в кондиционировании.LTXVSequenceParallelMultiGPUPatcher(#44). Включает последовательное параллельное выполнение с оптимизациями компиляции. Оставьте его включенным для лучшей пропускной способности; отключайте только при отладке размещения устройств.
Дополнительные возможности#
- Советы по подсказкам для LTX-2 ComfyUI
- Описывайте основные действия во времени, а не только статическое появление.
- Указывайте важные визуальные детали, которые вы должны видеть в видео.
- Напишите саундтрек: атмосферу, фоли, музыку и любые диалоги.
- Правила размера и частоты кадров
- Используйте ширину и высоту, которые являются кратными 32 (например, 1280×720).
- Используйте количество кадров, которые являются кратными 8 (121 в этом шаблоне — хорошая длина).
- Держите частоту кадров постоянной, где она появляется; график включает как плавающие, так и целочисленные поля, и они должны совпадать.
- Руководство LoRA
- Камера, глубина, поза и канни LoRA интегрированы; начните с силы 1 для движения камеры, затем добавьте вторую LoRA только при необходимости. Просмотрите официальную коллекцию на Lightricks/LTX‑2.
- Более быстрые итерации
- Уменьшите количество кадров, сократите шаги в
LTXVSchedulerи попробуйте дистиллированный контрольный пункт для маршрута канни. Когда движение работает, увеличьте разрешение и шаги для финалов.
- Уменьшите количество кадров, сократите шаги в
- Воспроизводимость
- Зафиксируйте
noise_seedв узлах случайного шума, чтобы получать повторяемые результаты, пока вы настраиваете подсказки, размеры и LoRA.
- Зафиксируйте
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы выражаем искреннюю благодарность компании Lightricks за мультимодальную модель генерации видео LTX-2 и исследовательскую кодовую базу LTX-Video, а также компании Comfy Org за партнерские узлы/интеграцию LTX-2 в ComfyUI, за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Comfy Org/LTX-2 теперь доступен в ComfyUI!
- GitHub: Lightricks/LTX-Video
- Hugging Face: Lightricks/LTX-Video-ICLoRA-detailer-13b-0.9.8
- arXiv: 2501.00103
- Документы / Примечания к выпуску: LTX-2 теперь доступен в ComfyUI!
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
