
LTX 2.3 Dual Character Lip Sync LoRA: видео с синхронизацией губ двух персонажей из одного изображения и одной аудиодорожки#
Этот рабочий процесс ComfyUI превращает одно статичное изображение и записанный разговор двух персонажей в связное видео с сохранением идентичности и синхронизированной речью для обоих экранных персонажей. Основанный на видео-основе LTX‑2.3 и LTX 2.3 Dual Character Lip Sync LoRA, он сопоставляет фонемы и временные метки из вашего диалога с каждым лицом, сохраняя выражения, взгляд и согласованность сцены на протяжении всех кадров.
Разработан для интервью, кинематографических диалогов, подкастов с видео-хостами и взаимодействий с виртуальными персонажами, рабочий процесс сочетает текстовые подсказки для компоновки сцены с движением, управляемым аудио. Он включает этап начальной загрузки изображения для быстрой разработки внешнего вида, двухэтапное выборочное отслеживание LTX для временной стабильности и скрытую масштабировку для четких результатов. Конечный результат — MP4 с встроенным аудио.
Основные модели в рабочем процессе Comfyui LTX 2.3 Dual Character Lip Sync LoRA#
- Модель генерации видео LTX‑2.3. Обеспечивает мультимодальную диффузионную основу, которая синтезирует временно согласованное видео, обусловленное текстом, изображением и аудио. Lightricks/LTX-2.3
- Видео VAE и Аудио VAE LTX‑2.3. Кодируют и декодируют видео и аудио латенты, используемые моделью для поддержания эффективности и синхронизации генерации. Поставляется с выпуском LTX‑2.3. Lightricks/LTX-2.3
- Пространственная скрытая масштабировка LTX. Улучшает детализацию после базового прохода путём увеличения в скрытом пространстве для более чистых текстур и краёв. Варианты доступны вместе с активами LTX. Lightricks/LTX-2
- LTX 2.3 Dual Character Lip Sync LoRA. Вносит обучение, которое поощряет движение рта и временные метки для двух лиц в одном кадре, сохраняя идентичность лиц.
- Модель преобразования текста в изображение Z‑Image Turbo. Быстро создаёт высококачественное эталонное изображение, которое закрепляет идентичность, кадрирование и освещение перед синтезом видео. Comfy‑Org/z_image_turbo
Связанные пакеты узлов, используемые в этом рабочем процессе: ComfyUI‑KJNodes, ComfyUI‑VideoHelperSuite, rgthree‑comfy, и ComfyUI‑PromptRelay.
Как использовать рабочий процесс Comfyui LTX 2.3 Dual Character Lip Sync LoRA#
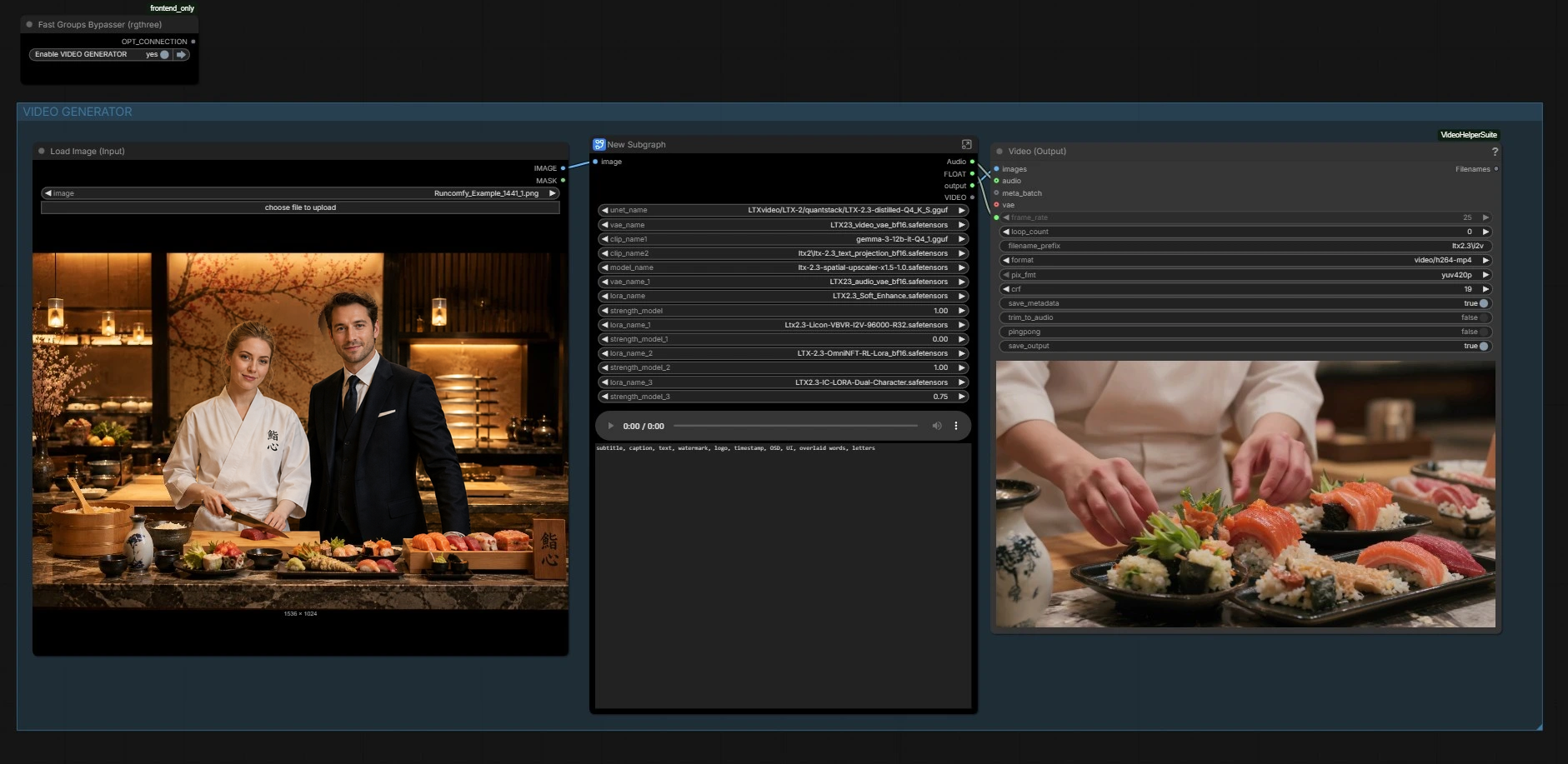
Рабочий процесс имеет две согласованные части: генератор изображений, который создаёт основной кадр, и генератор видео, который управляет движением и синхронизацией губ с аудио, сохраняя внешний вид. Используйте группы ниже в качестве вашего руководства.
ГЕНЕРАТОР ИЗОБРАЖЕНИЙ#
Эта секция создаёт основное статичное изображение. Используйте пресеты сцены в списке подсказок для быстрого проектирования композиций, затем уточните текст с описанием персонажей для обоих людей. Компактный стек диффузии изображений (“Z IMG TURBO” подграф) кодирует вашу подсказку и выбирает чистое эталонное изображение. Изображение декодируется и сохраняется для проверки, затем передаётся вперёд для закрепления идентичности и компоновки для видео.
Ключевые вводы, которые вы касаетесь здесь: описательная подсказка для сцены, гардероба и двух различных персонажей; избегайте терминологии объектива или рендеринга, которая противоречит реалистичности, если только этот вид не является намеренным.
Модели#
Здесь граф загружает основу LTX‑2.3, её видео и аудио VAE, текстовые кодировщики и скрытую масштабировку. Он также применяет LTX 2.3 Dual Character Lip Sync LoRA, а также дополнительные LoRA для стиля или улучшения, если вы их включаете. Здесь возможности базовой модели сочетаются с поведением синхронизации губ двух говорящих LoRA для управления движением рта без жертвования идентичности. Никаких действий не требуется, если вы не хотите заменить веса или настроить влияние LoRA.
ПОЛЬЗОВАТЕЛЬСКОЕ АУДИО#
Предоставьте здесь свой трек разговора. Аудиофайл загружается и кодируется в аудиолатент, который несёт временные и фонетические подсказки через конвейер. Если вы не предоставите аудио, рабочий процесс может генерировать движение, используя пустой аудиолатент, но LTX 2.3 Dual Character Lip Sync LoRA предназначен для работы с реальным диалогом. Используйте чистый микс двух говорящих с чётким чередованием для лучшего разделения движений рта.
Параметры видео#
Установите целевую продолжительность и частоту кадров. Эти значения сохраняются и используются на протяжении всего выборочного процесса, планирования, руководств по обрезке и финального рендеринга, чтобы губы, моргание и время кадра оставались выровненными. Держите длину вашего видео согласованной с предоставленным аудио, чтобы избежать лишнего начала или окончания.
ГЕНЕРАЦИЯ ЛАТЕНТ#
Ваше выбранное изображение предварительно обрабатывается, и его размеры обнаруживаются. Рабочий процесс создаёт видеолатент нужной длины, затем вставляет изображение на место, чтобы первый кадр соответствовал вашему дизайну. Применяется маска шума полного кадра для контроля того, насколько фон может изменяться по сравнению с лицами. Подготовленный аудиолатент затем сочетается с видеолатентом, чтобы обе модальности были готовы к кондиционированию.
Замечательные узлы: LTXVPreprocess масштабирует ваше изображение для LTX, EmptyLTXVLatentVideo строит временную шкалу, и LTXVImgToVideoInplaceKJ (#5881) закрепляет идентичность, создавая первый кадр из изображения.
Кондиционирование#
Текстовые подсказки кодируются и прикрепляются в качестве положительных и отрицательных условий. Используйте глобальное поле подсказок для описания постановки и намерения на естественном языке; вы можете включить краткий список кадров, если это полезно. Специальный отрицательный текстовый кодировщик подавляет субтитры, водяные знаки и интерфейсные элементы на кадре, чтобы лица оставались чистыми. Вспомогательные руководства по обрезке анализируют латент для размещения внимания на обоих лицах, улучшая отслеживание выражений каждого персонажа с активным LTX 2.3 Dual Character Lip Sync LoRA.
Представительные компоненты: PromptRelayEncode (#5903) объединяет ваше описание сцены с контекстом латент, и LTXVConditioning прикрепляет руководство с учётом частоты кадров для обеих модальностей.
1-е Семплирование#
Первый проход удаления шума генерирует временно согласованное базовое видео с заблокированными движениями губ. Лёгкий планировщик и семплер выбираются автоматически, с параметрами, маршрутизированными из сохранённых временных значений. Вариант модели, выходящий из LTX2_NAG, добавляет руководство с учётом шума для видео- и аудиоусловий, чтобы время речи оставалось закреплённым по мере формирования контента.
Основной путь семплера: SamplerCustom (#5891) с KSamplerSelect и базовым планировщиком; настраивайте только если у вас есть особые предпочтения по семплеру.
Этап #2 Масштабирование и доработка#
Второй этап улучшает резкость и микро-выражения. Скрытая масштабировка увеличивает пространственную детализацию, аудио- и видеолатенты повторно соединяются, и семплер доработки вносит тонкие коррекции, сохраняя установленное движение. Затем латенты разделяются и декодируются обратно в последовательность изображений и аудиоволну.
Важные блоки: LTXVLatentUpsampler (#5927) для ясности, SamplerCustomAdvanced (#5929) для прохода доработки, затем VAEDecode и LTXVAudioVAEDecode для возврата в пиксельное и аудиопространство.
Вывод#
Наконец, кадры и аудио упаковываются в MP4 для воспроизведения и проверки. Частота кадров, использованная для кондиционирования, повторно используется здесь, чтобы визуальный ритм и временные метки фонем соответствовали тому, что модель видела во время генерации. Вы также можете предварительно просмотреть аудио в середине графа, если вам нужно быстро проверить.
Путь вывода: CreateVideo (#5931) создаёт клип; вспомогательный путь VHS_VideoCombine (#5905) предоставляется для альтернативных экспортов с управлением метаданными.
Ключевые узлы в рабочем процессе Comfyui LTX 2.3 Dual Character Lip Sync LoRA#
LTXICLoRALoaderModelOnly(#5958) Загружает LTX 2.3 Dual Character Lip Sync LoRA в основу LTX‑2.3. Увеличьтеstrength_model, когда вам нужна более чёткая артикуляция рта и разделение говорящих; уменьшите, когда вы хотите, чтобы движение и стиль базовой модели доминировали, особенно если вы добавляете дополнительные LoRA для стиля.PromptRelayEncode(#5903) Центральное место для написания описания сцены и, при желании, краткого плана кадров. Оно объединяет глобальную подсказку с контекстом модели и текущим латентом, чтобы руководство оставалось согласованным на протяжении всей временной шкалы. Держите язык чётким и описывайте обоих персонажей отдельно, чтобы помочь в разделении идентичности и роли.LTXVImgToVideoInplaceKJ(#5881) Закрепляет первый кадр видеолатента непосредственно из вашего сгенерированного или загруженного изображения. Это закрепляет идентичность, гардероб и освещение, уменьшая отклонение с течением времени. Используйте средний или средне-широкий двухкадровый снимок с обоими лицами, не закрытыми, для наилучших результатов.LTXVAudioVAEEncode(#5851) Преобразует предоставленный трек диалога в аудиолатент, который модель может использовать для временных меток фонем. Подайте чистый микс без сильной компрессии; убедитесь, что время начала соответствует первому речевому фрагменту на экране, чтобы избежать сдвига движения губ.SamplerCustom(#5891) иSamplerCustomAdvanced(#5929) Два дополняющих друг друга этапа удаления шума. Держите семейства семплеров согласованными между этапами, чтобы сохранить непрерывность движения, и избегайте резких изменений в планировании шума, когда у вас уже есть желаемый вид.LTXVLatentUpsampler(#5927) Применяет скрытую масштабировку LTX перед доработкой, чтобы добавить чёткость без дестабилизации установленного движения. Выберите вариант масштабирования, подходящий для вашего целевого разрешения и реализма текстур.
Дополнительные возможности#
- Используйте WAV с двумя говорящими на 24 кГц с минимальным фоновым шумом; добавьте короткие естественные паузы между строками, чтобы помочь LTX 2.3 Dual Character Lip Sync LoRA разделить реплики.
- Создайте или предоставьте изображение, на котором оба субъекта видны, смотрят в сторону камеры, с одинаковым освещением на лицах.
- Сохраняйте отрицательную текстовую подсказку, исключающую “субтитры, подписи, логотип, временную метку”, чтобы избежать встраивания элементов интерфейса во время выборки.
- Начните с короткого клипа, чтобы проверить время, затем увеличьте продолжительность или повысьте разрешение, когда вам понравится поведение.
- Если вы добавляете LoRA для стиля, сбалансируйте их с LTX 2.3 Dual Character Lip Sync LoRA, чтобы артикуляция оставалась точной, а сцена сохраняла выбранный вами эстетический вид.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы искренне благодарим создателей “LTX 2.3 Dual Character Lip Sync LoRA Workflow Source” за рабочий процесс. Для получения авторитетных подробностей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- LTX 2.3 Dual Character Lip Sync LoRA Workflow Source/LTX 2.3 Dual Character Lip Sync LoRA Workflow Source
- Документы / Примечания к выпуску: YouTube video
Примечание: Использование упоминаемых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и кураторами.
