
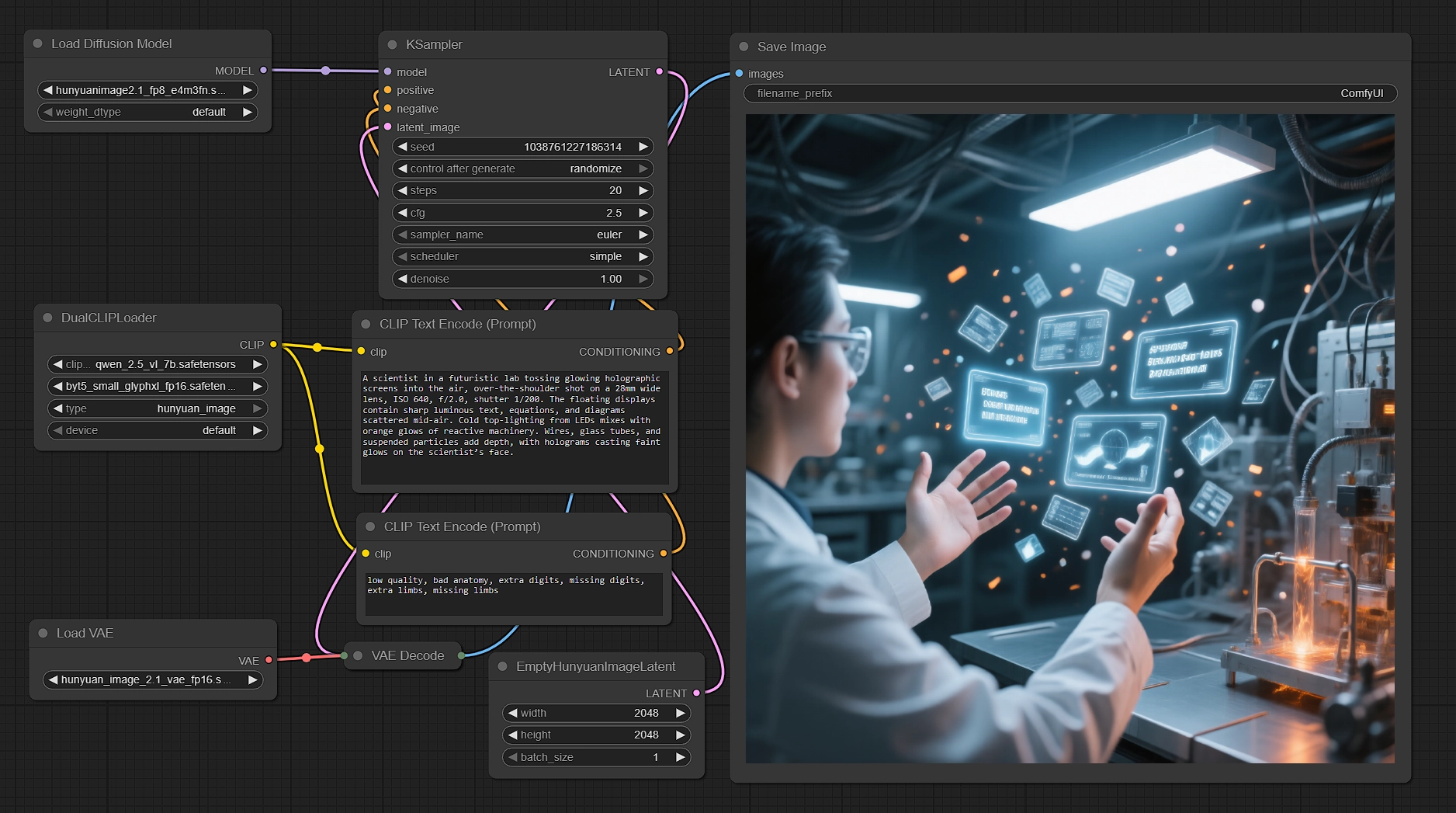










Генерация нативных 2K изображений с помощью Hunyuan Image 2.1 в ComfyUI#
Этот рабочий процесс превращает ваши подсказки в четкие, нативные 2048×2048 рендеры с использованием Hunyuan Image 2.1. Он сочетает диффузионный трансформер Tencent с двойными текстовыми энкодерами для улучшения семантического выравнивания и качества рендеринга текста, затем эффективно осуществляет выборку и декодирует через соответствующий высококомпрессионный VAE. Если вам нужны готовые к производству сцены, персонажи и чёткий текст в изображении на 2K, сохраняя при этом скорость и контроль, этот рабочий процесс ComfyUI Hunyuan Image 2.1 создан для вас.
Создатели, арт-директоры и технические художники могут вводить многоязычные подсказки, настраивать несколько параметров и стабильно получать четкие результаты. График поставляется с разумной негативной подсказкой, нативным 2K холстом и FP8 UNet, чтобы следить за использованием VRAM, демонстрируя, что Hunyuan Image 2.1 может предоставить из коробки.
Ключевые модели в рабочем процессе Comfyui Hunyuan Image 2.1#
- HunyuanImage‑2.1 от Tencent. Базовая текст-к-изображению модель с диффузионным трансформером, двойными текстовыми энкодерами, 32× VAE, постобучением RLHF и среднепоточечной дистилляцией для эффективной выборки. Ссылки: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Мультимодальный визуально-языковой энкодер, используемый здесь в качестве семантического текстового энкодера для улучшения понимания подсказок в сложных сценах и языках. Ссылка: Hugging Face
- ByT5 Small. Энкодер на уровне байтов без токенизации, который укрепляет обработку символов и глифов для рендеринга текста внутри изображений. Ссылки: Hugging Face · Paper
Как использовать рабочий процесс Comfyui Hunyuan Image 2.1#
График следует четкому пути от подсказки к пикселям: кодируйте текст с помощью двух энкодеров, готовьте нативный 2K латентный холст, образец с Hunyuan Image 2.1, декодируйте через соответствующий VAE и сохраняйте результат.
Кодирование текста с двойными энкодерами#
DualCLIPLoader(#33) загружает Qwen2.5‑VL‑7B и ByT5 Small, настроенные для Hunyuan Image 2.1. Эта двойная настройка позволяет модели анализировать семантику сцены, оставаясь устойчивой к глифам и многоязычному тексту.- Введите ваше основное описание в
CLIPTextEncode(#6). Вы можете писать на английском или китайском, смешивать подсказки камеры и освещения и включать инструкции по тексту в изображении. - Готовая к использованию негативная подсказка в
CLIPTextEncode(#7) подавляет общие артефакты. Вы можете адаптировать её к вашему стилю или оставить как есть для сбалансированных результатов.
Латентный холст на нативном 2K#
EmptyHunyuanImageLatent(#29) инициализирует холст на 2048×2048 с одной партией. Hunyuan Image 2.1 предназначен для 2K генерации, поэтому нативные 2K размеры рекомендуются для лучшего качества.- При необходимости отрегулируйте ширину и высоту, сохраняя соотношения сторон, поддерживаемые Hunyuan. Для альтернативных соотношений придерживайтесь дружественных к модели размеров, чтобы избежать артефактов.
Эффективная выборка с Hunyuan Image 2.1#
UNETLoader(#37) загружает FP8 контрольную точку для уменьшения VRAM, сохраняя при этом достоверность, затем подаетKSampler(#3) для удаления шума.- Используйте положительные и негативные условия от энкодеров для управления композицией и ясностью. Настраивайте seed для разнообразия, шаги для качества против скорости и руководство для соответствия подсказке.
- Рабочий процесс фокусируется на пути базовой модели. Hunyuan Image 2.1 также поддерживает этап уточнения; вы можете добавить его позже, если хотите дополнительную полировку.
Декодирование и сохранение#
VAELoader(#34) привносит VAE Hunyuan Image 2.1, аVAEDecode(#8) реконструирует финальное изображение из выборки латента с использованием 32× схемы сжатия модели.SaveImage(#9) записывает результат в выбранный вами каталог. Установите четкий префикс имени файла, если планируете итерацию по seed или подсказкам.
Ключевые узлы в рабочем процессе Comfyui Hunyuan Image 2.1#
DualCLIPLoader (#33)#
Этот узел загружает пару текстовых энкодеров, которые ожидает Hunyuan Image 2.1. Держите тип модели установленным для Hunyuan и выберите Qwen2.5‑VL‑7B и ByT5 Small, чтобы сочетать сильное понимание сцены с обработкой текста, учитывающей глифы. Если вы итеративно работаете над стилем, настраивайте положительную подсказку в тандеме с руководством, а не меняя энкодеры.
CLIPTextEncode (#6 и #7)#
Эти узлы превращают ваши положительные и негативные подсказки в условия. Сохраняйте положительную подсказку краткой сверху, затем добавляйте подсказки по линзам, освещению и стилю. Используйте негативную подсказку для подавления артефактов, таких как лишние конечности или шумный текст; обрежьте её, если она кажется слишком ограничивающей для вашей концепции.
EmptyHunyuanImageLatent (#29)#
Определяет рабочее разрешение и партию. По умолчанию 2048×2048 соответствует нативной 2K возможности Hunyuan Image 2.1. Для других соотношений сторон выбирайте ширину и высоту, дружественные к модели, и рассмотрите возможность небольшого увеличения шагов, если вы уходите далеко от квадрата.
KSampler (#3)#
Управляет процессом удаления шума с Hunyuan Image 2.1. Увеличивайте шаги, когда вам нужны более тонкие микродетали, уменьшайте для быстрых черновиков. Увеличьте руководство для более сильного соответствия подсказке, но следите за перенасыщением или жесткостью; уменьшите для более естественного разнообразия. Переключайте seed для исследования композиций без изменения вашей подсказки.
UNETLoader (#37)#
Загружает Hunyuan Image 2.1 UNet. Включенная FP8 контрольная точка сохраняет использование памяти умеренным для 2K вывода. Если у вас достаточно VRAM и вы хотите максимальную гибкость для агрессивных настроек, рассмотрите вариант с более высокой точностью той же модели из официальных выпусков.
VAELoader (#34) и VAEDecode (#8)#
Эти узлы должны соответствовать выпуску Hunyuan Image 2.1 для правильного декодирования. Высококомпрессионный VAE модели является ключом к быстрой 2K генерации; правильная пара VAE избегает сдвигов цвета и блочных текстур. Если вы меняете базовую модель, всегда обновляйте VAE соответственно.
Дополнительные элементы#
- Подсказки
- Hunyuan Image 2.1 хорошо реагирует на структурированные подсказки: объект, действие, окружение, камера, освещение, стиль. Для текста в изображении цитируйте точные слова, которые вы хотите, и сохраняйте их краткими.
- Скорость и память
- FP8 UNet уже эффективен. Если вам нужно сжать ещё больше, отключите большие партии и предпочитайте меньше шагов. В графике присутствуют необязательные узлы загрузчика GGUF, но по умолчанию они отключены; продвинутые пользователи могут заменить их при экспериментах с квантизированными контрольными точками.
- Соотношения сторон
- Придерживайтесь нативных 2K-дружественных размеров для лучших результатов. Если вы идёте в широкие или высокие форматы, убедитесь в чистоте рендера и рассмотрите небольшое увеличение шагов.
- Уточнение
- Hunyuan Image 2.1 поддерживает этап уточнения. Чтобы попробовать его, добавьте второй семплер после базового прохода с контрольной точкой уточнителя и лёгким удалением шума для сохранения структуры при увеличении микродеталей.
- Ссылки
- Детали модели Hunyuan Image 2.1 и загрузки: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small и статья: Hugging Face · Paper
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы искренне благодарим @Ai Verse и Hunyuan за их вклад и поддержку в Hunyuan Image 2.1 Demo. Для авторитетной информации, пожалуйста, обращайтесь к оригинальной документации и репозиториям, связанным ниже.
Ресурсы#
- Hunyuan/Hunyuan Image 2.1 Demo
- Документы / Примечания к выпуску: Hunyuan Image 2.1 Demo tutorial from @Ai Verse
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.

