
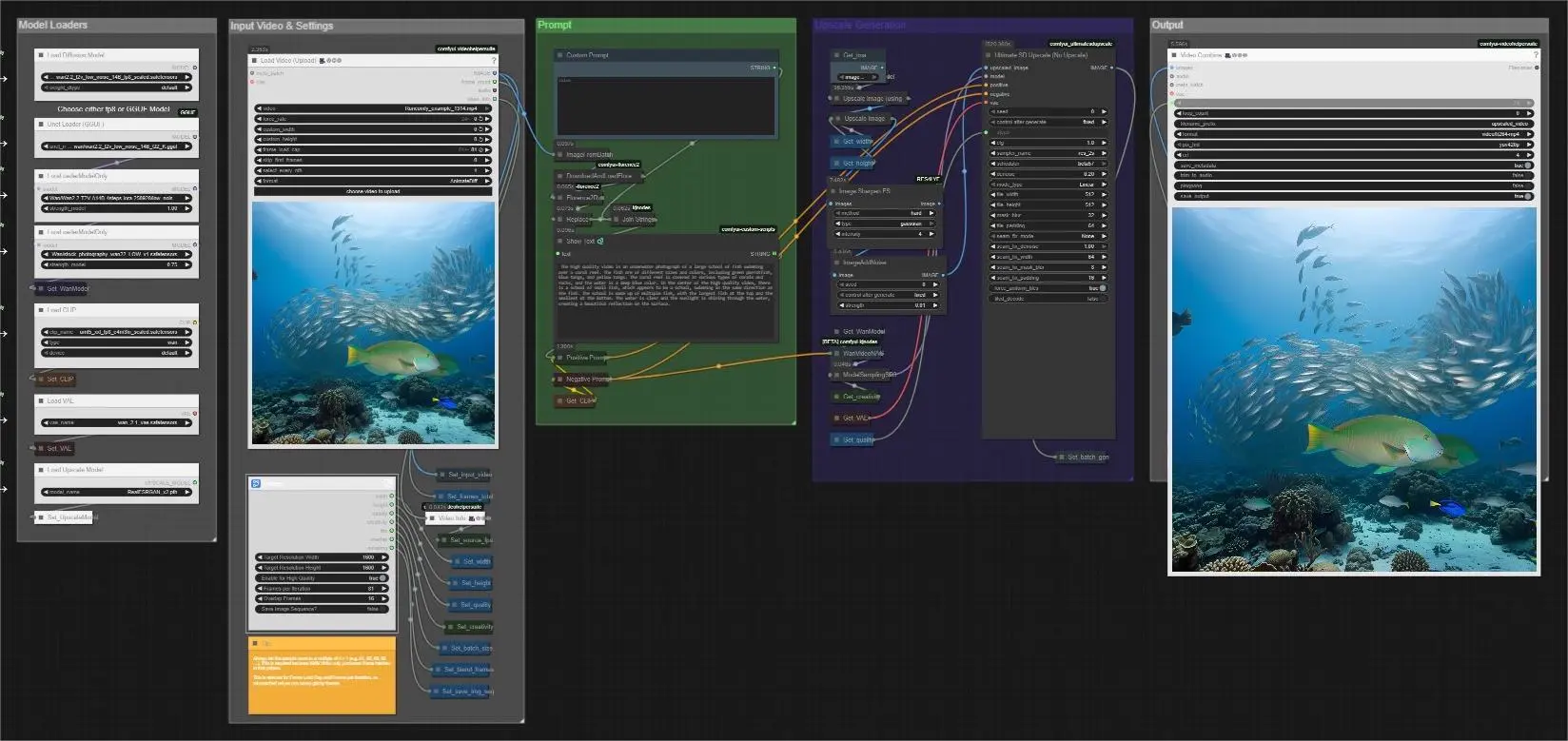
Простой видеоувеличитель для видеоматериалов#
Простой видеоувеличитель для видеоматериалов - это упрощенный конвейер ComfyUI от Mickmumpitz, который улучшает четкость, текстуру и воспринимаемое разрешение существующих видео с минимальными настройками. Он сочетает в себе быструю суперразрешение, дружелюбное к деталям резкость и уточнение Wan 2.x для восстановления тонкой структуры при сохранении естественности движения. Независимо от того, модернизируете ли вы архивные записи, улучшаете ли вы клипы, созданные ИИ, или подготавливаете мастер-копии, рабочий процесс Простой видеоувеличитель для видеоматериалов подчеркивает согласованность между кадрами, плавные переходы между партиями и надежный выход.
Рабочий процесс принимает одно входное видео, автоматически считывает его частоту кадров, генерирует или принимает направляющую подсказку и обрабатывает кадры в смешиваемых партиях, чтобы длинные последовательности оставались бесшовными. Вы можете выбрать легкую модель GGUF для систем с низким VRAM или FP8 UNet для максимальной точности, затем управлять уточнением с помощью простого контроля креативности. Конечные результаты сохраняются как увеличенное видео, с дополнительным путем последовательности изображений для крупных проектов.
Основные модели в рабочем процессе ComfyUI Простой видеоувеличитель для видеоматериалов#
- Wan 2.2 T2V Low Noise 14B UNet (FP8 или GGUF). Основной генеративный каркас, используемый для уточнения на основе диффузии, который улучшает детали, уважая исходные кадры. Hugging Face: Comfy-Org/Wan_2.2_ComfyUI_Repackaged и Hugging Face: bullerwins/Wan2.2-T2V-A14B-GGUF
- Wan 2.1 VAE. Декодер, который сохраняет текстуру и тон при переходе между латентным и пиксельным пространством во время уточнения. Hugging Face: Comfy-Org/Wan_2.1_ComfyUI_repackaged
- UMT5-XXL текстовый энкодер (FP8). Текстовый каркас, используемый для кондиционирования подсказок, который согласует инструкции с моделью WAN. Включен в репакетированные ресурсы Wan 2.1. Hugging Face: Comfy-Org/Wan_2.1_ComfyUI_repackaged
- RealESRGAN x2. Классическая модель суперразрешения, которая чисто увеличивает размер кадра перед восстановлением деталей на основе диффузии. GitHub: xinntao/Real-ESRGAN
- Microsoft Florence-2 Large. Модель визуально-языковая, используемая здесь для автоматического создания подписи к представительным кадрам, предоставляющая высококачественную подсказку, когда вы не хотите писать её. Hugging Face: microsoft/Florence-2-large
- Дополнительные LoRA надстройки для WAN 2.2. Легкие адаптеры, которые могут направить уточнение в сторону определенных видов без подавления видеоматериала. Например, "Lightning" low-noise 4-step LoRA. Hugging Face: lightx2v/Wan2.2-Lightning
Как использовать рабочий процесс ComfyUI Простой видеоувеличитель для видеоматериалов#
Конвейер следует четкому пути от входа к выходу и организует элементы управления в группы, чтобы вы всегда знали, где настроить качество, скорость и поведение памяти.
Загрузчики моделей#
Эта группа инициализирует основной стек моделей и позволяет вам выбрать либо FP8 safetensors UNet, либо GGUF-квантованный UNet для Wan 2.2. Используйте путь GGUF, когда VRAM ограничен, или FP8 UNet, когда вы хотите наивысшую точность. Wan 2.1 VAE и UMT5-XXL текстовый энкодер загружаются здесь, чтобы подсказки могли направлять следующий шаг диффузии. Если вы планируете использовать LoRA, загрузите его в этой группе перед запуском.
Входное видео и настройки#
Вставьте свой исходный клип с помощью VHS_LoadVideo (#130). Рабочий процесс считывает исходную частоту кадров через VHS_VideoInfo (#298), чтобы финальный рендер соответствовал движению. Установите целевую ширину и высоту, выберите, включать ли режим высокого качества, и настройте контроль креативности, чтобы решить, насколько строго уточнение должно следовать вашему входу. Для длинных клипов установите количество кадров на итерацию и значение перекрытия, чтобы партии плавно смешивались, и включите опцию сохранения последовательности изображений, когда вы хотите максимальную стабильность или работаете в очень высоком разрешении.
Подсказка#
Вы можете напечатать пользовательскую подсказку или позволить рабочему процессу создать её для вас. Один кадр выбирается и подписывается Florence2Run (#147), затем слегка переписывается StringReplace (#408) и объединяется с любым пользовательским текстом через JoinStrings (#339). Объединенная подсказка показывается ShowText|pysssss (#135) и передается в Positive Prompt (#3), в то время как Negative Prompt (#4) содержит термины для уменьшения артефактов. Это делает подсказки согласованными и простыми в управлении, особенно для пакетных заданий.
Генерация увеличения#
Кадры предварительно увеличиваются с помощью ImageUpscaleWithModel (#303) используя RealESRGAN, затем точно изменяются в размерах с помощью ImageScale (#454) до вашего целевого разрешения. Image Sharpen FS (#452) восстанавливает резкость краев, когда это необходимо, и ImageAddNoise (#421) добавляет небольшой контролируемый шум, который помогает диффузии восстанавливать реалистичную микротекстуру. Модель WAN подготавливается с помощью WanVideoNAG (#115) и ModelSamplingSD3 (#419), затем UltimateSDUpscaleNoUpscale (#126) выполняет уточнение с направлением по подсказке, сохраняя глобальную структуру и непрерывность движения.
Создатель пакетов + Смешение сгенерированных пакетов#
Длинные видео автоматически разбиваются на смешиваемые пакеты. Этот подграф вычисляет количество итераций, показывает его в "Number of Iterations," и собирает каждый пакет изображений с учетом вашей настройки перекрытия. На границах между пакетами ImageBatchJoinWithTransition (#244) смешивает кадры, чтобы шов был незаметен. Используйте больше перекрытий, когда разрезы очевидны, и уменьшайте их, чтобы ускорить процесс, когда сцены стабильны.
Выходное смешение сохраненной последовательности изображений#
Когда включена "Save Image Sequence," каждая итерация записывает свои кадры на диск, что полезно для очень высоких разрешений или ограниченной памяти. Рабочий процесс затем перезагружает эти кадры с помощью VHS_LoadImagesPath (#396), при необходимости снова смешивает концы пакетов и собирает их в непрерывную последовательность. Этот путь предоставляет надежный маршрут восстановления, если вы остановите и возобновите обработку.
Выход#
Финальные кадры собираются в видео с помощью VHS_VideoCombine (#128) с использованием исходной частоты кадров, захваченной ранее, чтобы движение оставалось плавным и соответствовало оригиналу. Вы также можете создать промежуточный предварительный просмотр или записать второй финал из сохраненного пути последовательности с помощью VHS_VideoCombine (#393). Имена файлов и подпапки автоматически увеличиваются, чтобы каждый запуск был аккуратным.
Основные узлы в рабочем процессе ComfyUI Простой видеоувеличитель для видеоматериалов#
VHS_LoadVideo (#130)#
Загружает входной клип и отображает изображения, количество кадров и blob video_info. Если вы планируете обрабатывать только часть, ограничьте загрузку кадров в узле и согласуйте "Frames per Iteration" соответственно. Синхронизация настроек загрузчика и пакета предотвращает заикания или разрывы, когда пакеты соединяются.
ImageUpscaleWithModel (#303)#
Применяет RealESRGAN для быстрого увеличения размера без артефактов перед диффузией. Используйте его, чтобы достичь или приблизиться к вашему целевому разрешению перед уточнением, чтобы проход WAN мог сосредоточиться на текстуре и мелких деталях, а не на крупномасштабном изменении размера. Если ваш источник уже соответствует целевому размеру, вы все равно можете сохранить этот этап для устранения шума и усиления структуры.
UltimateSDUpscaleNoUpscale (#126)#
Выполняет уточнение диффузии WAN по плиткам с исправлением швов и дополнительной декодировкой по плиткам для сохранения глобальной структуры. Основные элементы управления здесь - это шаги семплера, сила устранения шума и параметры, связанные с швами; более высокие шаги и устранение шума дают более уверенный вид, в то время как более низкие настройки ближе к вашим оригинальным кадрам. Когда вы включаете высокое качество в группе настроек, этот узел автоматически регулирует глубину шагов.
WanVideoNAG (#115) и ModelSamplingSD3 (#419)#
Эта пара подключает модель WAN к семплеру и открывает сдвиг креативности. Низкая креативность сохраняет выход близким к входу с мягким улучшением, в то время как более высокие значения добавляют больше генеративной текстуры и могут изобретать детали. Для документальных фильмов, интервью или архивной работы предпочитайте консервативные значения; для синтетических или ИИ-происходящих клипов можете немного продвинуться дальше.
ImageBatchJoinWithTransition (#244)#
Смешивает конец одного пакета с началом следующего, чтобы скрыть швы. Увеличьте количество кадров перехода, когда заметны скачки яркости или текстуры, и уменьшите его для более быстрых запусков, когда сцены однородны. Это основной рычаг, который сохраняет конвейер Простой видеоувеличитель для видеоматериалов бесшовным на длинных временных линиях.
VHS_VideoCombine (#128)#
Собирает финальное видео на захваченной выше частоте кадров. Если вы сохранили последовательности изображений, вы можете переключиться на альтернативный узел объединения, чтобы рендерить с диска без повторной обработки. Этот узел также используется для установки контейнера и формата пикселей при необходимости.
Дополнительные возможности#
- Выберите один путь WAN. Используйте FP8 UNet для наилучшего качества на мощных GPU, или GGUF UNet для систем с низким VRAM и ноутбуков.
- Сохраняйте движение естественным. Начните с низкой креативности для живого действия или документальных материалов, затем постепенно увеличивайте, если нужно больше восстановления текстуры.
- Планируйте пакеты заранее. На длинных клипах включите "Save Image Sequence," чтобы вы могли возобновить или повторно рендерить финал без повторного вычисления диффузии.
- Совпадение математических расчетов кадров. Установите количество кадров на итерацию так, чтобы оно соответствовало ограничению вашего загрузчика и перекрытию; инструменты пакетов Простой видеоувеличитель для видеоматериалов вычислят итерации и смешают края для вас.
- Используйте LoRA умеренно. Добавьте WAN 2.2 LoRA, когда вам нужен определенный вид, и уменьшите его вес, если он начинает подавлять оригинальный характер сцены.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы искренне благодарим Mickmumpitz за рабочий процесс Простой видеоувеличитель для видеоматериалов за их вклад и поддержку. Для получения авторитетной информации, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- YouTube/Простой видеоувеличитель для видеоматериалов
- Документация / Примечания к выпуску: YouTube @ Mickmumpitz
Примечание: использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
