
Фантастический портрет: Анимация портрета, насыщенная выражениями, в ComfyUI#
Этот рабочий процесс превращает одно неподвижное изображение в высококачественную анимацию Фантастического портрета. Он интегрирует модель FantasyPortrait из Fantasy-AMAP с трансформерами диффузии, усиленными выражением, и оборачивает её в конвейер Wan Video 2.1 для преобразования изображений в видео, чтобы вы могли создавать кадры с сохранением идентичности и насыщенные эмоциями с минимальными настройками. Он разработан для создателей, которые хотят получить кинематографическое движение Фантастического портрета из одной фотографии с четкими настройками композиции, длительности и стиля.
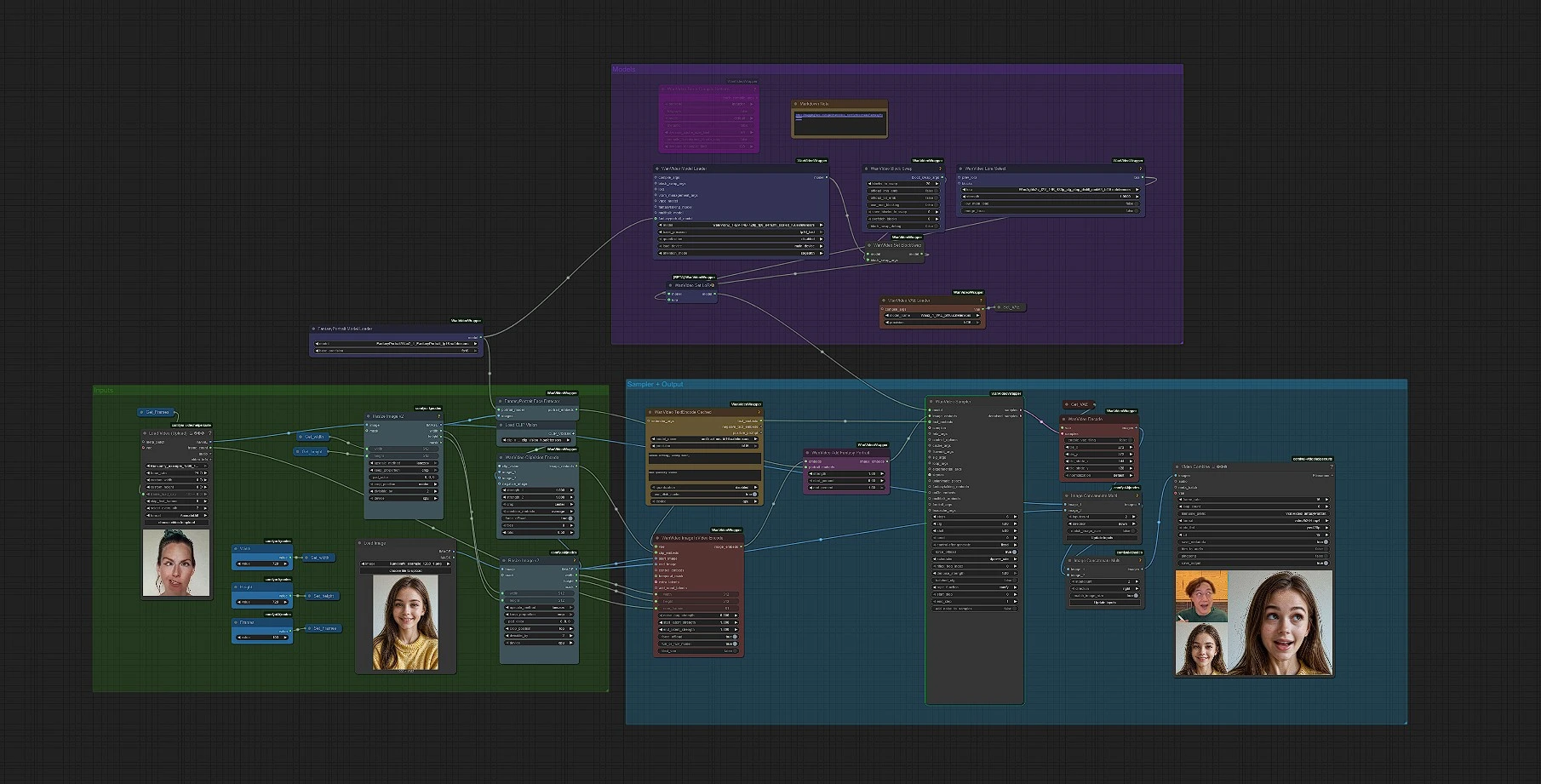
Конвейер полностью автоматизирован: загрузите портрет, выберите разрешение и количество кадров, при необходимости добавьте запрос и LoRA, затем рендерите в MP4. Внутри граф обнаруживает лицо, кодирует изображение и текстовые подсказки, объединяет в себя встраивания идентичности Фантастического портрета в кондиционер I2V Wan, образует видео и декодирует кадры перед сохранением финального клипа.
Основные модели в рабочем процессе ComfyUI Fantasy Portrait#
FantasyPortrait (Fantasy-AMAP)
Основной модуль идентичности и выражения. Обеспечивает встраивания, усиленные выражением, которые сохраняют черты субъекта, позволяя при этом детализированное движение лица. GitHub | Paper (arXiv)
WanVideo 2.1 I2V (14B, 720p)
Основной механизм диффузии видео, используемый для формирования анимации из портрета и текстовой/изображенной кондиции. Квантованные, готовые к использованию веса доступны через модельный пакет Kijai. Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL encoder
Высокопроизводительный текстовый энкодер, используемый для управления подсказками в видеосемплере. Пример веса: umt5-xxl-enc-bf16.safetensors в Kijai/WanVideo_comfy
Wan 2.1 VAE
Оптимизированный для видео VAE для кодирования/декодирования латентов. Пример веса: Wan2_1_VAE_bf16.safetensors в Kijai/WanVideo_comfy
Как использовать рабочий процесс ComfyUI Fantasy Portrait#
Рабочий процесс выполняется слева направо от входных данных до финального видео. В основном вам нужно настроить три вещи в начале: изображение, размеры и длительность. Затем вы можете уточнить с помощью короткой подсказки или LoRA, если хотите.
1) Ввод изображения и изменение размера#
Загрузите одно изображение в LoadImage, затем оно будет изменено для обработки. Два этапа изменения размера обеспечивают соответствие изображения вашему выбранному width и height, сохраняя при этом композицию. Используйте элементы управления Width, Height и Frames, чтобы определить размер вывода (по умолчанию 720 × 720) и длину анимации. Это сохраняет композицию вашего Фантастического портрета постоянной на протяжении всего конвейера.
2) Обнаружение лиц и встраивания Фантастического портрета#
FantasyPortraitModelLoader загружает веса FantasyPortrait, а FantasyPortraitFaceDetector извлекает встраивания портрета, учитывающие идентичность и выражение, из вашего изображения. Основная идея заключается в том, чтобы отделить, кто является субъектом, от того, как они выражаются, чтобы финальная анимация сохраняла идентичность, позволяя при этом выразительное движение. Вам не нужно ничего настраивать здесь, если вы не меняете модели.
3) Условие изображения и текста#
Для управления изображением CLIPVisionLoader с WanVideoClipVisionEncode производит мощные визуальные характеристики из портрета. Для управления текстом WanVideoTextEncodeCached использует энкодер UMT5-XXL, чтобы преобразовать ваши положительные и отрицательные подсказки в встраивания видео-условий. Короткая, простая подсказка, такая как "естественный студийный крупный план, мягкая улыбка", часто достаточно для чистого вида Фантастического портрета.
4) Кодирование I2V с контролем длительности#
VHS_LoadVideo используется в качестве удобного счетчика кадров. Вы можете оставить клип-заполнитель или загрузить эталон с вашей предпочтительной длительностью; его количество кадров питает WanVideoImageToVideoEncode, который преобразует ваше стартовое изображение плюс встраивания изображения/текста в условие I2V. Если вы предпочитаете фиксированную длину, просто установите Frames напрямую и игнорируйте загрузчик ссылок.
5) Слияние Фантастического портрета#
WanVideoAddFantasyPortrait объединяет условие I2V с встраиваниями портрета из шага 2. Это то, что придает финальной анимации Фантастического портрета сильное сохранение идентичности и выразительную детальность. Никакие дополнительные входные данные не требуются после загрузки вашего изображения.
6) Настройка LoRA и модели#
WanVideoModelLoader загружает Wan 2.1, затем WanVideoLoraSelect при необходимости применяет легкий I2V LoRA из пакета Kijai, чтобы изменить движение или эстетику без повторного обучения. Это хорошее место для экспериментов, если вы хотите немного более стилизованный Фантастический портрет, сохраняя при этом идентичность.
7) Семплирование видео и декодирование#
WanVideoSampler генерирует латентные кадры, используя объединенное условие. Держите подсказки простыми, увеличивайте шаги умеренно, если вам нужно больше деталей, и избегайте чрезмерного ограничения длинными отрицательными подсказками. WanVideoDecode преобразует латенты обратно в изображения, и рабочий процесс объединяет предварительные просмотры перед тем, как VHS_VideoCombine записывает MP4 (по умолчанию 16 fps, yuv420p). Префикс имени выходного файла установлен для удобства.
Ключевые узлы в рабочем процессе ComfyUI Fantasy Portrait#
FantasyPortraitModelLoader (#138)#
Загружает веса FantasyPortrait. Меняйте здесь, если тестируете более новую версию Fantasy-AMAP. Настройка не требуется, но держите точность согласованной с вашей моделью Wan и VAE.
FantasyPortraitFaceDetector (#142)#
Извлекает встраивания портрета из измененного изображения. Хорошие результаты получаются из хорошо освещенных, фронтально направленных фотографий с минимальной окклюзией. Если движение выглядит неправильно, проверьте входное кадрирование и попробуйте более чистый исходник.
WanVideoImageToVideoEncode (#151)#
Создает условие I2V Wan из характеристик изображения CLIP, вашего стартового изображения и длительности. Настраивайте width, height и num_frames, чтобы контролировать отпечаток рендера и длину. Длинные последовательности требуют больше VRAM и времени.
WanVideoAddFantasyPortrait (#150)#
Объединяет идентичность/выражения Фантастического портрета в кондиционер I2V. Используйте это, чтобы сохранить субъекта узнаваемым на всех кадрах, позволяя при этом детализированные изменения выражений. Обычно параметры не требуют настройки.
WanVideoSampler (#149)#
Генерирует латенты видео. Если хотите более четкие детали, увеличивайте шаги умеренно. Если движение отклоняется, уменьшите сложность подсказки или попробуйте другую LoRA. Держите руководство связным, а не многословным.
WanVideoTextEncodeCached (#155)#
Кодирует положительные/отрицательные подсказки с помощью UMT5-XXL. Используйте короткие, описательные фразы. Слишком сильные отрицательные подсказки (например, тяжелые "плохое качество" стеки) могут подавлять выражение.
Советы#
- Начните с квадратного 720 × 720 и 4-6 секунд для быстрой итерации, затем увеличивайте по мере необходимости.
- Используйте чистый, фронтально освещенный портрет с видимыми глазами. Избегайте сильных окклюзий, солнечных очков или экстремальных углов.
- Держите подсказки Фантастического портрета краткими. Описывайте освещение и настроение, а не идентичность.
- Попробуйте легкую LoRA из пакета Kijai, если хотите немного изменить ощущение движения, не теряя идентичности.
Благодарности#
Этот рабочий процесс использует модель Фантастического портрета от команды Fantasy-AMAP, интегрируя Expression-Augmented Diffusion Transformers в ComfyUI для полностью автоматизированного, высококачественного конвейера анимации портретов. Особая благодарность kijai за создание и интеграцию узла Wan Video Wrapper, сделавшего возможным бесшовное выполнение анимации портретов в рамках преобразования изображений в видео. Мы также выражаем признательность широкой сообществу ComfyUI за их постоянный вклад в открытые творческие инструменты.
Ссылки: