
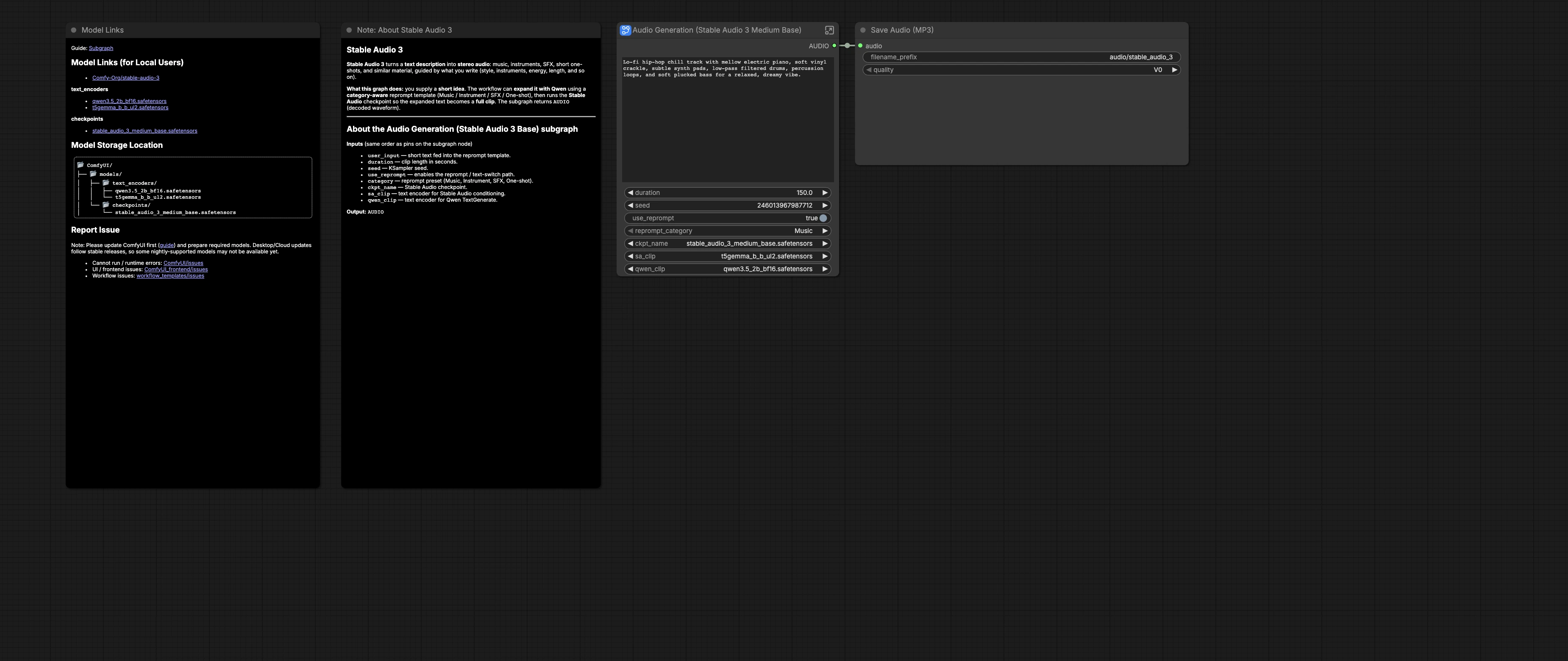
Stable Audio 3.0 Medium Base workflow para texto-para-áudio de longa duração no ComfyUI#
Este workflow Stable Audio 3.0 Medium Base transforma ideias de texto curtas em áudio estéreo mais longo e musical. É construído em torno do checkpoint stable_audio_3_medium_base com os codificadores de texto T5-Gemma e Qwen3.5 para entregar esboços de música orientados por prompts, camas ambientes, SFX e one-shots com configurações reprodutíveis no ComfyUI.
O gráfico inclui um sistema opcional de reprompt consciente de categoria que pode expandir sua ideia breve em um prompt denso e pronto para produção antes da síntese. Você escolhe a categoria, duração e semente, então o pipeline condiciona o Stable Audio 3 e renderiza o áudio que é salvo como um MP3. O workflow segue o modelo oficial e os ativos fornecidos pela Comfy-Org para Stable Audio 3.0 Medium Base. Veja o modelo de referência e os modelos em Comfy-Org/workflow_templates e Comfy-Org/stable-audio-3.
Modelos-chave no workflow Comfyui Stable Audio 3.0 Medium Base#
- Stable Audio 3 Medium Base checkpoint. O modelo generativo central que sintetiza áudio estéreo a partir de condicionamento de texto e latentes. Fonte: Comfy-Org/stable-audio-3.
- Codificador de texto T5-Gemma Base UL2. Produz as embeddings de texto usadas para condicionar o Stable Audio 3 para prompts positivos e negativos. O arquivo do codificador de texto empacotado está incluído na pasta text_encoders do repositório Stable Audio 3: Comfy-Org/stable-audio-3.
- Modelo de texto Qwen3.5 2B. Alimenta o reprompt opcional consciente de categoria que expande uma ideia curta em uma descrição detalhada de música, instrumento, SFX ou one-shot. Fonte: Comfy-Org/Qwen3.5.
Como usar o workflow Comfyui Stable Audio 3.0 Medium Base#
Em um nível alto, você fornece uma ideia curta e uma duração alvo. O gráfico pode manter suas palavras como estão ou usar o Qwen3.5 para reescrevê-las via um template de categoria. O resultado é codificado para condicionamento, amostrado pelo Stable Audio 3, decodificado para áudio e salvo.
Entradas do usuário: prompt e duração#
O subgrafo Audio Generation (Stable Audio 3 Medium Base) (#52) expõe user_input, duration, seed, use_reprompt e category. Escreva uma ideia breve em linguagem simples, como um estilo, lista de instrumentos, humor e um BPM opcional. Escolha um comprimento de clipe em segundos e defina uma seed para reprodutibilidade ou variação. Ative use_reprompt quando quiser a reescrita orientada por template, então selecione uma category como Música, Instrumento, SFX ou One-shot.
Carregadores: checkpoint e codificadores de texto#
CheckpointLoaderSimple (#25) carrega stable_audio_3_medium_base.safetensors, fornecendo o MODEL e VAE usados posteriormente para amostragem e decodificação. CLIPLoader (#26) carrega o codificador T5-Gemma usado para condicionamento. Um segundo CLIPLoader (#29) carrega o modelo Qwen3.5 que dirige a etapa de reprompt.
Reprompt: modelos JSON e categoria#
Um seletor de categoria CustomCombo (#43) alimenta um grande JSON de prompts de sistema em JsonExtractString (#49). O modelo selecionado é inserido em um meta-prompt por Text Replace (PROMPT TEMPLATE) (#38). Seu user_input é injetado por Text Replace (USER INPUT) (#39), e o comprimento alvo é inserido usando Text Replace (AUDIO LENGTH) (#40), mantendo a reescrita alinhada com a duração escolhida.
Reprompt: Qwen TextGenerate#
TextGenerate (#28) usa o Qwen3.5 para transformar o modelo montado mais sua ideia em um prompt conciso e detalhado que segue regras específicas de categoria. Esta etapa é especialmente útil para estruturas musicais mais longas e para SFX onde a linguagem técnica concreta é importante. A reescrita do prompt é pré-visualizável, para que você possa iterar rapidamente na escolha de categoria e fraseado.
Alternando entre texto original e reescrito#
ComfySwitchNode (#34) seleciona seu texto original ou a reescrita gerada pelo Qwen com base em use_reprompt. Deixe ligado para obter prompts estruturados e conscientes de comprimento, ou desligue quando quiser controle literal sobre a redação. Este simples interruptor torna o teste A/B direto.
Codificação CLIP: condicionamento#
CLIPTextEncode (#6) converte o prompt selecionado no condicionamento positivo que dirige o modelo. Um segundo CLIPTextEncode (#7) fornece um condicionamento negativo neutro por padrão. Este emparelhamento fornece ao Stable Audio 3 uma orientação clara enquanto evita artefatos indesejados.
Geração de áudio: Stable Audio#
EmptyLatentAudio (#11) cria um latente de áudio cujo comprimento corresponde à duration. KSampler (#3) realiza o processo de remoção de ruído usando o MODEL Stable Audio 3 Medium Base do checkpoint. VAEDecodeAudio (#12) transforma o latente final em uma forma de onda estéreo audível. Como a mesma duration também informa o reprompt, o comprimento do clipe renderizado e o texto reescrito permanecem sincronizados.
Salvar e exportar#
Fora do subgrafo, SaveAudioMP3 (#19) grava o resultado em um arquivo MP3 com um prefixo útil para organização. Use isso ao gerar em lote takes com diferentes valores de seed ou categorias, depois ouça e mantenha seus favoritos.
Nós-chave no workflow Comfyui Stable Audio 3.0 Medium Base#
ComfySwitchNode(#34). Alterna entre ouser_inputoriginal e o texto gerado pelo Qwen. Ative para reescritas estruturadas e conscientes de comprimento ou desative para controle direto.TextGenerate(#28). Executa o Qwen3.5 com um prompt de sistema específico de categoria para expandir ideias. Para personalizar o estilo de reescrita, edite os modelos de categoria emJsonExtractString(#49) e os prompts de cola nos nósText Replaceadjacentes.EmptyLatentAudio(#11). Define o comprimento do clipe. Mantenha isso alinhado com o tokenAUDIO_LENGTHinserido para que o tempo de síntese corresponda à intenção textual.KSampler(#3). Governa a trajetória de remoção de ruído para Stable Audio 3. Ajusteseedpara variações enquanto mantém outras configurações estáveis para comparar takes de forma justa.SaveAudioMP3(#19). Controla o prefixo do nome do arquivo de saída e o formato para uma rápida construção de biblioteca a partir de várias execuções.
Extras opcionais#
- Comece com uma ideia de uma ou duas frases que nomeie gênero ou origem, instrumentos-chave ou texturas e humor. O reprompt pode preencher detalhes como BPM e arranjo.
- Escolha a categoria que corresponde ao seu objetivo: Música para faixas completas, Instrumento para loops ou stems, SFX para ambientes e ações, One-shot para hits isolados.
- Mantenha a duração realista para o seu conteúdo alvo. Clipe muito longos são mais pesados para computar e podem se beneficiar de uma
seedestável enquanto você itera. - Quando os resultados parecerem lotados, desative o reprompt e tente uma frase mais simples, depois reative uma vez que você goste da direção.
- Para takes alternativos rápidos, mantenha tudo constante e altere apenas a
seed.
Agradecimentos#
Este workflow implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos a Comfy-Org pelo artigo de suporte do ComfyUI Stable Audio 3 Day-0, Comfy-Org pelo template oficial do workflow Stable Audio 3.0 Medium Base, Comfy-Org pelos arquivos de modelo Stable Audio 3, e Comfy-Org pelos arquivos de modelo do codificador Qwen3.5 por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Comfy-Org/ComfyUI Stable Audio 3 Day-0 Support Article
- Docs / Release Notes: Stable Audio 3 Day-0 Support
- Comfy-Org/Official Stable Audio 3.0 Medium Base Workflow Template
- GitHub: Comfy-Org/workflow_templates
- Comfy-Org/Stable Audio 3 Model Files
- Hugging Face: Comfy-Org/stable-audio-3
- Comfy-Org/Qwen3.5 Encoder Model Files
- Hugging Face: Comfy-Org/Qwen3.5
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.