
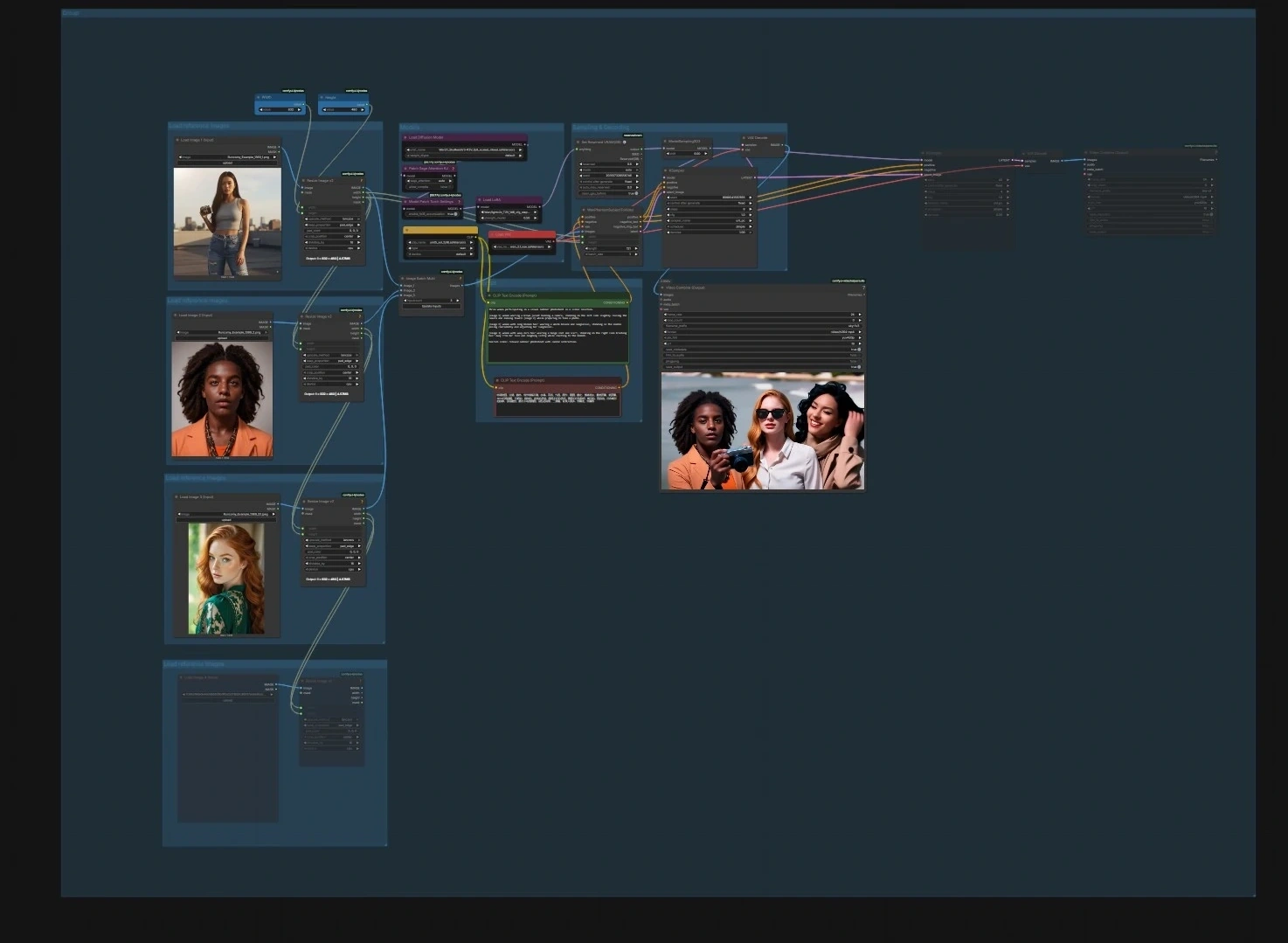
SkyReels V3 ComfyUI: criação de vídeo de imagem, vídeo e áudio fiel à identidade#
SkyReels V3 ComfyUI é um workflow pronto para produção que traz o modelo de vídeo multimodal SkyReels V3 para o ComfyUI, permitindo que você anime imagens estáticas, estenda cenas existentes e crie avatares falantes dirigidos por áudio com sincronização labial precisa. É projetado para criadores que desejam movimento cinematográfico, forte identidade de assunto e coerência temporal enquanto permanecem dentro de um gráfico de nós flexível.
O workflow vem com quatro pipelines focados que podem ser executados independentemente ou encadeados: animação de personagem de imagem para vídeo, continuação de vídeo para vídeo, avatares falantes de áudio para vídeo e geração de próximo take para fluxo de história. Cada caminho inclui pontos de entrada claros e padrões sensatos para que você possa inserir seus ativos e renderizar rapidamente saídas de alta qualidade do SkyReels V3.
Nota para máquinas 2X Large e maiores (workflow R2V): Defina
Patch Sage Attention KJ(#240)sage_attentioncomodisabledantes de executar. Deixar habilitado pode acionar errosSM90 kernel is not available.
Modelos principais no workflow Comfyui SkyReels V3 ComfyUI#
- Backbones de vídeo SkyReels V3 (R2V, V2V Shot, A2V) do pacote WanVideo FP8. Estes são os geradores principais que lidam com movimento consciente de identidade, continuação de vídeo e sincronização labial condicionada por áudio. Veja os pesos do SkyReels V3 no pacote WanVideo no Hugging Face aqui.
- Modelos OpenCLIP Vision ViT para orientação de imagem e incorporação de referência. Eles fornecem recursos visuais robustos que ajudam a preservar aparência e estilo entre os quadros. Página do projeto: open_clip.
- Codificador de texto UMT5 para compreensão de prompts. Ele fornece condicionamento rico de linguagem para direcionar estilo, cena e ações. Repositório: umt5.
- Recursos de fala Wav2Vec2 para sincronização labial e análise de áudio. A variante base chinesa é suportada por padrão e variantes semelhantes em inglês também funcionam. Cartão do modelo: TencentGameMate/chinese-wav2vec2-base.
- Qwen3‑ASR‑1.7B para fala para texto. Usado para transcrever áudio de referência e inicializar prompts de TTS clonados por voz. Cartão do modelo: Qwen/Qwen3-ASR-1.7B.
- MelBandRoFormer para separação vocal. Útil quando você precisa de faixas de fala limpas antes de incorporar sincronização labial. Cartão do modelo: Kijai/MelBandRoFormer_comfy.
- MiniCPM‑V para geração de prompts conscientes de tomadas. Ele analisa filmagens anteriores e propõe a próxima tomada para continuidade da história. Hub do modelo: OpenBMB/MiniCPM-V.
Como usar o workflow Comfyui SkyReels V3 ComfyUI#
O gráfico é organizado em quatro pipelines. Você pode executar qualquer um sozinho ou em sequência para construir edições mais longas.
Animação de personagem de imagem para vídeo#
- Modelos. Carregue o UNet, CLIP e VAE no grupo de Modelos usando
UNETLoader(#241),CLIPLoader(#242) eVAELoader(#194). Os nós de patch do modeloPathchSageAttentionKJ(#240) eModelPatchTorchSettings(#239) otimizam configurações de atenção e matemática, enquantoLoraLoaderModelOnly(#250) permite que você misture opcionalmente um estilo ou movimento LoRA no modelo SkyReels. - Carregar imagens de referência. Use os três grupos “Carregar imagens de referência” para importar 1–3 retratos ou poses. Os ajudantes de redimensionamento
ImageResizeKJv2(#291, #298, #299, #304) alinham a proporção e os agrupam; fotos de identidade mais limpas produzem resultados mais estáveis. - Prompt. Insira texto de cena e ação no grupo de Prompt com
CLIPTextEncode(#6) e um codificador de texto negativo opcionalCLIPTextEncode(#7) para afastar características indesejadas. Mantenha a linguagem concisa e específica para movimento e enquadramento. - Amostragem e decodificação.
WanPhantomSubjectToVideo(#249) funde suas referências e prompts em um latente consciente de identidade que alimentaKSampler(#149) através deModelSamplingSD3(#48). Os quadros decodificados deVAEDecode(#264) são embalados em um filme comVHS_VideoCombine(#280); defina sua taxa de quadros e formato de arquivo alvo lá.
Loop de extensão de vídeo para vídeo#
- Vídeo de entrada e configurações. Traga seu clipe de origem com
VHS_LoadVideo(#329). Defina quantos segmentos extras gerar e quanto de sobreposição entre os segmentos usando os ajudantes inteiros “Número de Extensões” (#342) e “Quadros de Sobreposição” (#341).ImageResizeKJv2(#327) padroniza a resolução para o sampler. - Amostragem de loop extende vídeo. O par de loop
easy forLoopStart(#331) eeasy forLoopEnd(#332) percorre o clipe em janelas para estabilizar transições. Cada janela é codificada comWanVideoEncode(#326), recebe incorporações neutras ou de controle viaWanVideoEmptyEmbeds(#328), e é denoised porWanVideoSampler(#320) deWanVideoModelLoader(#319). Os quadros são decodificados comWanVideoDecode(#321) e pré-visualizados ou salvos comVHS_VideoCombine(#322, #335). - Ajudantes de desempenho.
WanVideoTorchCompileSettings(#323) eWanVideoBlockSwap(#325) permitem truques de compilação e memória para execuções mais longas ou de maior resolução.
Avatar falante de áudio para vídeo#
- 1 – Criar áudio. Você pode gerar uma faixa de fala clonada por voz com
FB_Qwen3TTSVoiceClonePrompt(#416) eFB_Qwen3TTSVoiceClone(#412), ou carregar qualquer voz pré-gravada comLoadAudio(#417).Qwen3ASRLoader(#414) eQwen3ASRTranscribe(#413) ajudam você a extrair texto de um clipe de referência para iniciar o prompt de TTS, se desejado. - 2 – Recursos de áudio.
DownloadAndLoadWav2VecModel(#348) alimentaMultiTalkWav2VecEmbeds(#350) para criar incorporações de movimento labial a partir de sua fala; o comprimento é alinhado ao áudio e pré-visualizável comPreviewAudio(#422). UseAny Switch (rgthree)(#435) para escolher a saída TTS ou seu arquivo importado como a faixa de condução. - 3 – Imagem de entrada. Carregue o rosto falante no grupo “3 - Imagem de entrada” e dimensione-o com
ImageResizeKJv2(#370). Retratos limpos, de frente e com iluminação consistente funcionam melhor. - Geração de vídeo de referência. Primeiro, crie um curto âncora visual a partir da imagem estática usando
WanVideoImageToVideoEncode(#392). Recursos CLIP‑Vision deCLIPVisionLoader(#352) eWanVideoClipVisionEncode(#351) estabilizam a identidade na próxima etapa; um agendadorWanVideoSchedulerv2(#385) é preparado no grupo de Configuração de Amostragem. - Gerar sincronização labial de áudio.
WanVideoImageToVideoSkyreelsv3_audio(#383) combina a imagem inicial, quadros de referência opcionais e incorporações CLIP‑Vision em condicionamento de imagem.WanVideoSamplerv2(#384) então denoisa com o modelo SkyReels A2V enquantoWanVideoSamplerExtraArgs(#386) injeta as incorporações de sincronização labialMultiTalkpara formas de boca precisas.WanVideoPassImagesFromSamples(#381) transmite quadros decodificados paraVHS_VideoCombine(#346) onde o vídeo final é muxado com seu áudio.
Geração de próxima tomada de vídeo para vídeo#
- Pré-processamento de quadros de vídeo. Importe a tomada anterior com
VHS_LoadVideo(#443) e redimensione-a viaImageResizeKJv2(#441).GetImageRangeFromBatch(#445) seleciona uma fatia de contexto queWanVideoEncode(#440) transforma em latentes;WanVideoEmptyEmbeds(#442) prepara a janela de condicionamento. - Prompt automático de vídeo.
CreateVideo(#450) monta um clipe proxy compacto a partir dos quadros de contexto queAILab_MiniCPM_V_Advanced(#449) analisa para redigir um prompt de próxima tomada. Inspecione ou refine o rascunho emShowText|pysssss(#447) e incorpore-o comWanVideoTextEncodeCached(#444) antes de amostrar. - Modelos e amostragem. Carregue o modelo V2V Shot com
WanVideoModelLoader(#436) eWanVideoVAELoader(#438);WanVideoBlockSwapopcional (#439) lida com VRAM. OWanVideoSampler(#451) gera a continuação,WanVideoDecode(#437) renderiza quadros, eVHS_VideoCombine(#446) gera a tomada final. Este caminho do SkyReels V3 ComfyUI é ideal para storyboards e previz onde cada novo corte deve respeitar o anterior.
Nós principais no workflow Comfyui SkyReels V3 ComfyUI#
WanPhantomSubjectToVideo(#249). Constrói um latente consciente de identidade a partir de suas imagens de referência agrupadas mais dicas de texto, que então dirige o sampler. Ajuste o número e a diversidade de referências para equilibrar travamento de semelhança versus movimento criativo; mantenha os nós de redimensionamento que o alimentam consistentes para evitar deriva. Referência: WanVideo Wrapper no GitHub contém notas de implementação e entradas esperadas ComfyUI‑WanVideoWrapper.WanVideoImageToVideoEncode(#392). Codifica uma imagem estática em uma semente de tomada estável e opcionalmente mistura orientação CLIP‑Vision para pose e enquadramento. Use-o para criar quadros âncora antes da etapa dirigida por áudio para que identidade e configuração de câmera permaneçam consistentes entre os pipelines. Documentos do Wrapper: ComfyUI‑WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). Prepara incorporações de imagem adaptadas para o sampler A2V e mescla quadros de vídeo de referência opcionais. Certifique-se de que sua largura e altura correspondam ao caminho do sampler; combine-o comWanVideoSamplerv2eMultiTalkWav2VecEmbedspara sincronização labial precisa.WanVideoSamplerv2(#384, #387). O principal denoiser para SkyReels V3 que aceita incorporações de imagem e texto além de configurações de agendador. Os nósWanVideoSamplerExtraArgs(#386, #409) são onde sincronização labial, loop ou recursos de contexto são injetados; mantenha esses conectados ao alternar entre os modelos A2V e I2V. Detalhes de implementação: ComfyUI‑WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). Converte fala em incorporações temporais que dirigem o movimento da boca. Combinar o orçamento de quadros pretendido e garantir vocais limpos melhora significativamente a precisão dos fonemas. Modelo de referência Wav2Vec: TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). Analisa a tomada anterior e redige um prompt estruturado para personagem, fundo, ação, humor e iluminação. Use isso para manter a continuidade narrativa ao usar o caminho de próxima tomada V2V; o texto resultante flui paraWanVideoTextEncodeCached. Família de modelos: OpenBMB/MiniCPM-V.
Extras opcionais#
- Mantenha as resoluções de imagem, vídeo e sampler consistentes nos nós conectados para evitar distorções de aspecto e cintilação de identidade.
- Para extensões mais longas, aumente a sobreposição de janela no loop de extensão V2V para suavizar transições entre os segmentos.
- Se a memória da GPU estiver apertada, deixe os nós de VRAM Reservada (
ReservedVRAMSetter(#312, #448)) habilitados e use os blocos de configurações de compilação antes de amostrar. - Quando avatares falantes saírem do ritmo, priorize fala limpa ou separe vocais com MelBandRoFormer antes de criar incorporações
MultiTalk. - As configurações de entrega final, como taxa de quadros, formato de pixel e CRF, são controladas nos nós de saída
VHS_VideoCombine; combine a taxa de quadros com sua fonte para edições suaves.
Este README cobre o gráfico completo do SkyReels V3 ComfyUI para que você possa escolher o caminho que se encaixa em seu projeto, combiná-los quando necessário e renderizar vídeos prontos para história com mínima tentativa e erro.
Agradecimentos#
Este workflow implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos a @Benji’s AI Playground e SkyReels pelo workflow SkyReels V3 ComfyUI por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- SkyReels/V3 ComfyUI Source
- Documentos / Notas de Lançamento: SkyReels V3 ComfyUI Source from @Benji’s AI Playground
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.