
Qwen Image 2512 LoRA Inferência: gerações do AI Toolkit alinhadas ao pipeline e correspondentes ao treinamento em ComfyUI#
Este fluxo de trabalho RunComfy pronto para produção aplica um AI Toolkit–treinado LoRA ao Qwen Image 2512 no ComfyUI com foco em comportamento correspondente ao treinamento. Ele se concentra em RC Qwen Image 2512 (RCQwenImage2512)—um nó personalizado de código aberto construído pelo RunComfy (source) que executa um pipeline de inferência nativo do Qwen (em vez de um gráfico de amostrador genérico) e carrega seu adaptador através de lora_path e lora_scale.
Por que a Inferência Qwen Image 2512 LoRA muitas vezes parece diferente no ComfyUI#
Os previews do AI Toolkit para Qwen Image 2512 são produzidos por um pipeline específico do modelo, incluindo o comportamento de orientação “true CFG” do Qwen e os padrões que esse pipeline usa para condicionamento e amostragem. Se você reconstruir o mesmo trabalho como um gráfico de amostrador padrão do ComfyUI, a semântica da orientação e o ponto de inserção do LoRA podem mudar—então “mesmo prompt + mesma seed + mesmos passos” ainda pode resultar em um resultado de aparência diferente. Na prática, muitos relatórios de “meu LoRA não corresponde ao treinamento” são incompatibilidades de pipeline, não um parâmetro ausente.
RCQwenImage2512 mantém a inferência alinhada envolvendo o pipeline Qwen Image 2512 dentro do nó e aplicando o LoRA nesse pipeline via lora_path e lora_scale. Fonte do pipeline: `src/pipelines/qwen_image.py`.
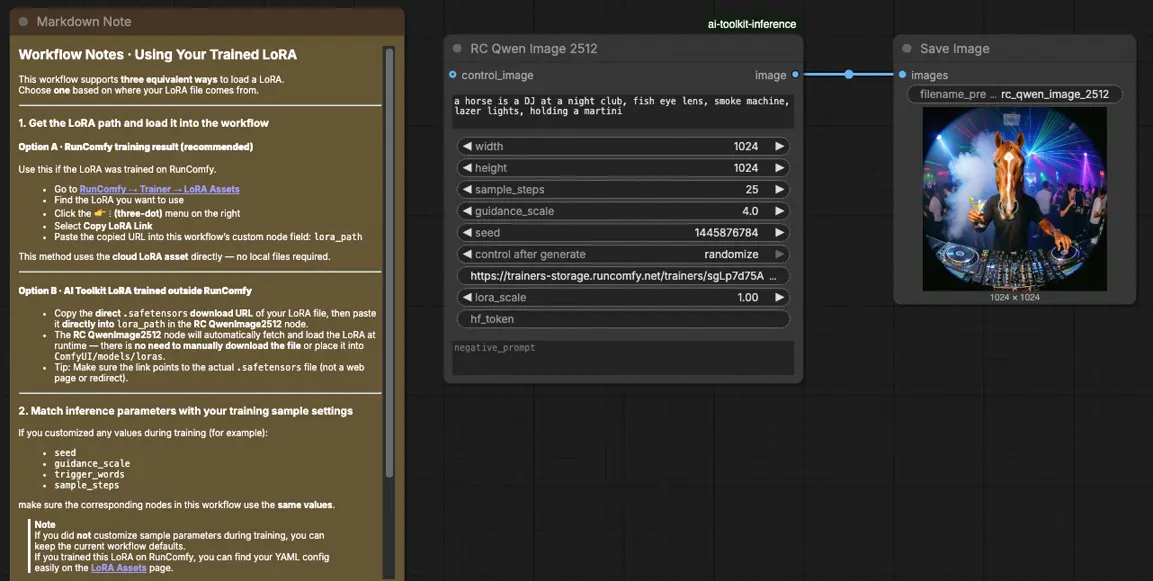
Como usar o fluxo de trabalho de Inferência Qwen Image 2512 LoRA#
Passo 1: Abra o fluxo de trabalho#
Inicie o fluxo de trabalho na nuvem no ComfyUI.
Passo 2: Importe seu LoRA (2 opções)#
- Opção A (resultado de treinamento do RunComfy): RunComfy → Trainer → LoRA Assets → encontre seu LoRA → ⋮ → Copiar Link do LoRA

- Opção B (LoRA do AI Toolkit treinado fora do RunComfy): Copie um link direto de download
.safetensorspara seu LoRA e cole esse URL emlora_path(não é necessário baixar paraComfyUI/models/loras)
Passo 3: Configure o nó personalizado RCQwenImage2512 para Inferência Qwen Image 2512 LoRA#
Cole seu link do LoRA em lora_path no RC Qwen Image 2512 (RCQwenImage2512).

Em seguida, defina os parâmetros restantes do nó (comece correspondendo aos valores que você usou para geração de preview/amostra durante o treinamento):
prompt: seu prompt positivo (inclua quaisquer tokens de gatilho que seu LoRA espera)negative_prompt: opcional; mantenha vazio se você não usou negativos em seus previewswidth/height: resolução de saída (múltiplos de 32 são recomendados para esta família de pipelines)sample_steps: passos de inferência; espelhe sua contagem de passos de preview antes de ajustar (25 é uma base comum)guidance_scale: força da orientação (Qwen usa uma escala “true CFG”, então reutilize seu valor de preview primeiro)seed: bloqueie a seed enquanto valida o alinhamento configurando o control_after_generate para 'fixo', então varie para novas amostraslora_scale: força do LoRA; comece perto do seu valor de preview e ajuste em pequenos incrementos
Este é um fluxo de trabalho de texto para imagem, então você não precisa fornecer uma imagem de entrada.
Nota de alinhamento de treinamento: se você personalizou a amostragem durante o treinamento, abra seu YAML de treinamento do AI Toolkit e espelhe width, height, sample_steps, guidance_scale, seed e lora_scale. Se você treinou no RunComfy, abra Trainer → LoRA Assets → Config e copie os valores de preview/amostra para o RCQwenImage2512 antes de iterar.

Passo 4: Execute a Inferência Qwen Image 2512 LoRA#
Clique em Queue/Run. O nó SaveImage salva a imagem gerada na sua pasta de saída padrão do ComfyUI.
Solução de problemas da Inferência Qwen Image 2512 LoRA#
O nó personalizado RC Qwen Image 2512 (RCQwenImage2512) do RunComfy é projetado para manter a inferência alinhada ao pipeline com a amostragem no estilo de preview do Qwen Image 2512 por:
- executar um pipeline de inferência nativo do Qwen dentro do nó (não um gráfico de amostrador genérico), e
- injetar o LoRA via
lora_path+lora_scaledentro desse pipeline (ponto de inserção consistente).
(1)Qwen-Image Loras não funcionam no comfyui#
Por que isso acontece
Usuários relataram que LoRAs Qwen-Image treinados pelo AI Toolkit podem falhar ao serem aplicados no ComfyUI porque os prefixos de chave do estado-dict do LoRA não correspondem ao que o caminho de carregamento/inferência do lado do ComfyUI espera (então o adaptador carrega “silenciosamente” mas não insere realmente os módulos de transformador Qwen).
Como corrigir (opções verificadas por usuários)
- Use RCQwenImage2512 para injeção de LoRA ao nível do pipeline: carregue o adaptador apenas via
lora_path+lora_scaleno RCQwenImage2512 (evite empilhar nós de carregador de LoRA adicionais enquanto depura). Isso mantém o ponto de inserção do LoRA alinhado com o pipeline Qwen usado pela amostragem no estilo de preview. - Se você precisar usar um provedor de inferência/não RC: uma correção relatada por usuários é renomear as chaves do LoRA substituindo o primeiro segmento do prefixo da chave do LoRA de
diffusion_model→transformer, para que os pesos se mapeiem para os módulos de transformador Qwen esperados (veja o problema para o contexto exato e por que isso é necessário).
(2)Patch para travamento ao usar inference_lora_path com imagem qwen (permite gerar amostras com turbo lora)#
Por que isso acontece
Alguns usuários enfrentam um travamento quando tentam carregar um LoRA de inferência para Qwen (incluindo Qwen-Image-2512) através do fluxo inference_lora_path do AI Toolkit. Isso não é um problema de “prompt/CFG/seed”—é um problema de caminho de carregamento de inferência.
Como corrigir (verificado por usuários)
- Aplique o patch/atualize para uma versão que inclua o patch descrito no problema. O autor do problema relata que o patch corrige o travamento ao carregar um LoRA de inferência para Qwen (veja o problema para a mudança exata e o contexto de configuração).
- Para inferência ComfyUI especificamente: prefira RCQwenImage2512 e carregue o adaptador via
lora_path/lora_scaledentro do nó RC. Isso evita depender de rotas externas de carregamento de LoRA de inferência e mantém o pipeline consistente com a amostragem no estilo de preview.
(3)usar sageattention 2 qwen-image no comfyui mostra imagens pretas devido a NaNs (ou seja, imagens pretas)#
Por que isso acontece
Usuários relataram que executar Qwen Image no ComfyUI com SageAttention pode produzir NaNs que se transformam em imagens pretas. Isso pode parecer “meu LoRA está quebrado,” mas na verdade é o backend de atenção produzindo valores inválidos—a execução do pipeline falha antes que você possa avaliar significativamente o comportamento do LoRA.
Como corrigir (verificado por usuários)
- Não use
--use-sage-attentionpara Qwen Image quando causar NaNs/saídas pretas. Valide uma linha de base limpa primeiro (saídas não pretas), depois avalie o impacto do LoRA. - Se você precisar de acelerações SageAttention: corrigindo a saída preta do Qwen forçando um caminho de backend CUDA. Na prática, isso geralmente significa usar um patch de nível de fluxo de trabalho (por exemplo, um nó “Patch Sage Attention”) e selecionar uma variante de backend CUDA que evite o caminho Triton quebrado para a GPU/arquitetura afetada.
- Depois de ter saídas de linha de base estáveis (não pretas), execute a inferência Qwen Image 2512 através do RCQwenImage2512 para que o pipeline + ponto de injeção do LoRA permaneçam alinhados ao preview enquanto você corresponde
width/height/sample_steps/guidance_scale/seed/lora_scale.
Execute a Inferência Qwen Image 2512 LoRA agora#
Abra o fluxo de trabalho compartilhado, cole seu URL do LoRA em lora_path, corresponda seus valores de amostragem de preview e execute RCQwenImage2512 para gerações de Qwen Image 2512 correspondentes ao treinamento no ComfyUI.