
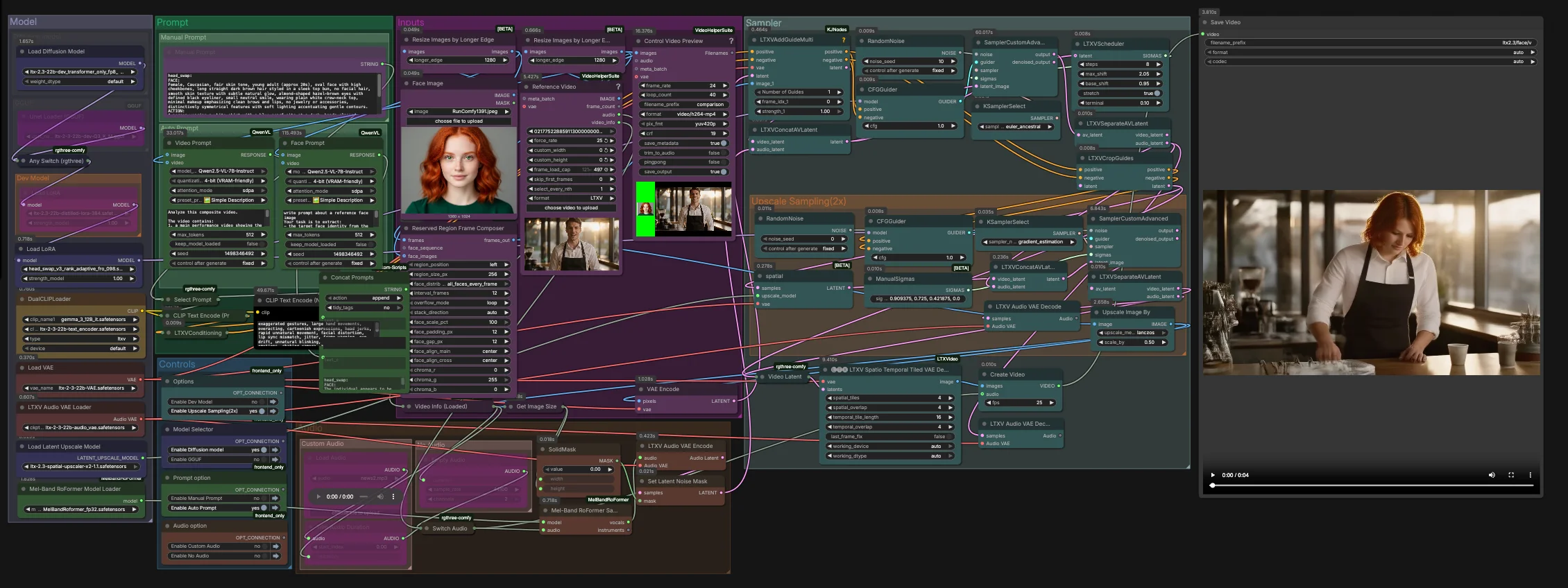
LTX-2.3-Video-Face-Swap para ComfyUI#
Este fluxo de trabalho oferece substituição de rosto em vídeo de alta fidelidade e temporalmente estável usando a família LTX 2.3. Construído para RunComfy e ComfyUI, ele combina uma imagem guia de identidade com um vídeo-alvo e orientação de áudio opcional para preservar expressões, iluminação e movimento em todos os quadros. O resultado é uma troca realista, resistente a cintilações, que se mantém em close-ups e tomadas médias.
Criadores, artistas de VFX e cineastas de IA podem usar o LTX-2.3-Video-Face-Swap para manter controle criativo total: faça prompts manualmente ou gere prompts estruturados a partir das entradas, escolha entre as variantes dev, distilled, FP8 ou GGUF, e finalize com uma decodificação espaço-temporal e upscaling latente 2x opcional para detalhes nítidos.
Modelos chave no fluxo de trabalho Comfyui LTX-2.3-Video-Face-Swap#
- LTX 2.3 22B Video Diffusion Transformer. Modelo central de geração e edição de vídeo que impulsiona a preservação de identidade e coerência temporal. Veja a família de modelos oficial em Lightricks/LTX-2.3.
- LTX 2.3 Text Encoders. O gráfico emparelha o codificador de texto LTX 2.3 com um codificador de instruções Gemma 3 12B para melhorar o alinhamento de prompts para edição de vídeo. Exemplos de artefatos: ltx-2-3-22b-text_encoder.safetensors e gemma_3_12B_it.safetensors.
- LTX 2.3 VAE e Audio VAE. Codificadores/decodificadores usados para comprimir e reconstruir quadros visuais e faixas de áudio enquanto preservam detalhes e sincronização. Veja Lightricks/LTX-2.3 VAE files e variantes de audio VAE no repositório dividido vantagewithai/LTX-2.3-Split.
- LTX 2.3 Spatial Upscaler x2. Upscaler 2x em espaço latente que aumenta a fidelidade espacial antes da decodificação final, ideal para detalhes faciais. ltx-2.3-spatial-upscaler-x2-1.1.safetensors.
- Head‑swap LoRA. Um LoRA adaptativo em rank especializado para transferência de identidade que melhora a semelhança e estabilidade ao conduzir a edição. Exemplo: head_swap_v3_rank_adaptive_fro_098.safetensors.
- MelBandRoFormer. Modelo opcional de separação de fonte musical usado aqui para isolar vocais para uma orientação de movimento bucal mais forte. Kijai/MelBandRoFormer_comfy.
- Variantes de implantação opcionais. Pesos FP8 apenas para transformadores para velocidade em GPUs suportadas Kijai/LTX2.3_comfy e construções leves UNet GGUF para CPU ou cenários de baixa VRAM vantagewithai/LTX-2.3-GGUF.
Como usar o fluxo de trabalho Comfyui LTX-2.3-Video-Face-Swap#
Este gráfico funciona em duas etapas. A primeira etapa realiza a troca principal na resolução latente nativa com orientação de áudio. A segunda etapa faz upsampling no espaço latente e refina a região do rosto antes de uma decodificação espaço-temporal e multiplexação final para vídeo.
Entradas#
- Carregue sua imagem de identidade em
Face Image(LoadImage(#255)). Use uma foto bem iluminada, frontal ou de três quartos para a extração de identidade mais confiável. - Carregue a filmagem-alvo em
Reference Video(VHS_LoadVideo(#393)). Os quadros são normalizados e pré-visualizados viaResizeImagesByLongerEdgeeControl Video Preview(VHS_VideoCombine(#396)) para verificações rápidas antes da amostragem. - O
ReservedRegionFrameComposer(#395) prepara quadros guia que alinham a imagem do rosto ao layout da cena, ajudando o modelo a focar na área de troca durante o condicionamento.
Prompt#
- Você pode descrever o visual e a ação desejados manualmente em
Manual Promptou deixar o gráfico compor automaticamente um prompt estruturado.Video Prompt(AILab_QwenVL(#400)) extrai o movimento corporal e a cena do vídeo enquantoFace Prompt(AILab_QwenVL(#401)) extrai detalhes de identidade da imagem facial. Concat Promptsmescla identidade e ação em uma instrução concisa, entãoSelect Promptencaminha seu texto manual ou o prompt automático paraCLIP Text Encode. O texto do prompt negativo é codificado separadamente para suprimir artefatos comuns de vídeo.
Modelo#
- O grupo
Modelcarrega o LTX 2.3 UNet ou sua variante GGUF, aplica o LoRA destilado e o LoRA de troca de rosto, e traz os VAEs LTX e codificadores de texto duplos. A configuração de dois codificadores melhora o alinhamento para conteúdo falado e bloqueio de câmera sem restringir excessivamente a identidade. - Se você estiver otimizando para velocidade ou memória, alterne entre dev, destilado, apenas transformador FP8, ou GGUF no seletor de modelo fornecido. Nenhuma configuração extra é necessária no RunComfy.
Amostrador#
- A primeira etapa combina latentes de vídeo e áudio em
LTXVConcatAVLatent(#321), depois remove o ruído comCFGGuider(#326),LTXVScheduler(#324), eSamplerCustomAdvanced(#257). OLTXVAddGuideMulti(#392) injeta seu guia de identidade para que o rosto seja estabelecido cedo e permaneça estável ao longo do tempo. - Após a primeira passagem,
LTXVSeparateAVLatent(#323) divide fluxos para queLTXVCropGuides(#282) possa focar a edição ao redor do rosto. Isso concentra o cálculo onde é importante e melhora a consistência temporal.
Amostragem de Upscale (2x)#
LTXVLatentUpsampler(#279) aplica o upscaler espacial x2 do LTX 2.3 no espaço latente. O latente de vídeo com upscaling é então reunido com o latente de áudio emLTXVConcatAVLatent(#287) e refinado por uma segunda passagemSamplerCustomAdvanced(#288) guiada porCFGGuider(#284).- Esta estratégia de duas etapas produz pele, olhos e cabelos mais nítidos enquanto mantém a troca bloqueada na identidade pretendida.
Áudio#
- O grupo
Audiopermite que você encaminhe áudio original, silêncio ou um segmento cortado viaSwitch Audio. Para pistas de movimento labial mais fortes, a faixa selecionada é enviada através deMelBandRoFormerSampler(#355) para isolar vocais, depois codificada comLTXVAudioVAEEncode(#364). - Uma máscara de ruído sólida (
SetLatentNoiseMask(#365)) previne mudanças indesejadas impulsionadas por áudio fora da região da boca enquanto ainda aproveita o tempo da fala para guiar expressões.
Decodificação e exportação#
- Os quadros finais são reconstruídos com
LTXVSpatioTemporalTiledVAEDecode(#377), que decodifica com mosaico sensível ao tempo para evitar costuras e manter a continuidade do movimento.CreateVideo(#292) multiplica as imagens com o áudio escolhido, eSaveVideograva o clipe finalizado.
Nós chave no fluxo de trabalho Comfyui LTX-2.3-Video-Face-Swap#
LTXVAddGuideMulti(#392). Alimenta o guia de rosto alinhado no fluxo de condicionamento para que o modelo fixe-se na identidade-alvo desde os primeiros passos. Se a semelhança se desviar em movimento rápido, aumente o número ou a frequência dos quadros guia em vez de aumentar a orientação globalmente.LTXVCropGuides(#282). Foca automaticamente a segunda passagem na região facial derivada dos latentes e prompts da primeira etapa. Use-o para apertar a área de edição quando fundos ou mãos competirem por atenção.SamplerCustomAdvanced(#257). Passagem principal de remoção de ruído que estabelece identidade, iluminação e movimento grosseiro. Emparelhe-o com oLTXVSchedulerpara modelagem de etapas e mantenha a escolha do amostrador estável em experimentos para tornar comparações significativas.LTXVLatentUpsampler(#279). Realiza um upscale latente 2x usando o upscaler espacial LTX antes do refinamento. Use isso quando precisar de poros mais nítidos, cílios e costuras de chapéu sem introduzir cintilação de upscalers de pixels pós-decodificação.SamplerCustomAdvanced(#288). Passagem de refinamento após o upscaling. Ajuste moderadamente a orientação aqui para aguçar características enquanto preserva a identidade definida pela primeira passagem.LTXVSpatioTemporalTiledVAEDecode(#377). Decodificador sensível ao tempo que reduz costuras de mosaico em quadros. Se você atingir limites de VRAM em clipes longos, prefira ajustar seu layout de mosaico em vez de diminuir a resolução.MelBandRoFormerSampler(#355). Separação vocal usada apenas para orientação. Se o áudio fonte for barulhento, mude para áudio original ou silencioso para evitar a propagação de artefatos em movimento de boca.
Extras opcionais#
- A qualidade da imagem do rosto importa. Use uma foto neutra, bem iluminada, de frente ou ligeiramente de três quartos com idade e expressão semelhantes à performance.
- Mantenha o vídeo de referência estável. Tomadas estáticas ou com tripé produzem os resultados mais estáveis do LTX-2.3-Video-Face-Swap, especialmente em tomadas médias e close.
- Os prompts devem ser concisos. Declare a cena e a ação em um único parágrafo e reserve adjetivos de identidade para o prompt de rosto, não para o prompt de ação.
- A orientação de áudio é opcional. O discurso claro melhora as formas da boca; faixas apenas musicais oferecem pouco benefício, então escolha silêncio para concentrar o cálculo em visuais.
- Para execução com baixa VRAM ou apenas CPU, prefira a construção UNet GGUF; para alta taxa de transferência em GPUs modernas, os pesos apenas para transformadores FP8 são uma boa opção padrão.
- Use com responsabilidade. Obtenha consentimento para qualquer semelhança que você trocar e cumpra as leis e políticas de plataforma aplicáveis.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos imensamente ao LTX-2.3 pelo modelo LTX-2.3, e ao EyeForAILabs pelo tutorial no YouTube, por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- LTX-2.3/LTX-2.3 Model
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Nota: O uso dos modelos, conjuntos de dados e códigos referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.