
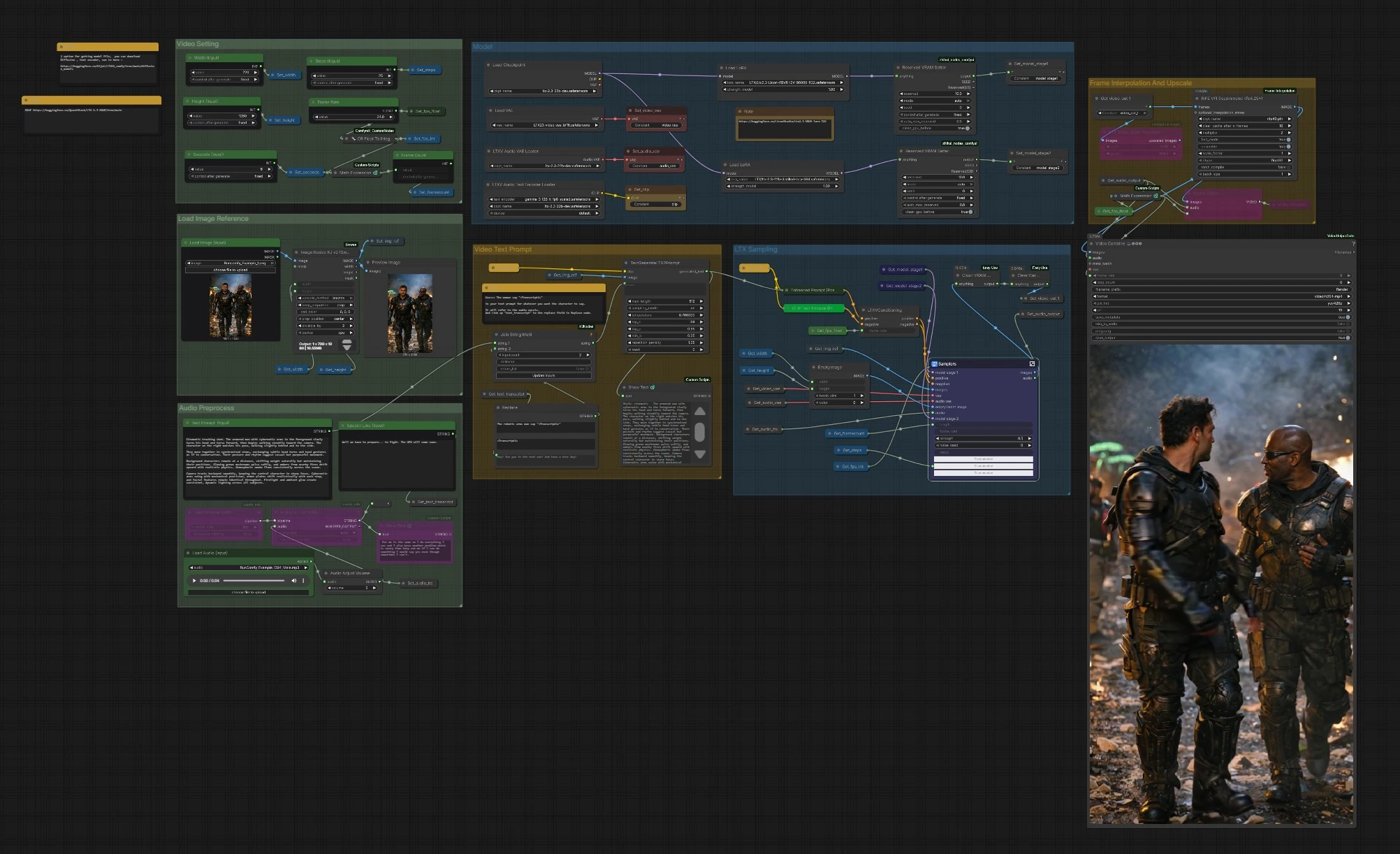
Workflow LTX 2.3 VBVR ComfyUI: imagem-para-vídeo com raciocínio e diálogo#
Este workflow transforma uma única imagem de referência em uma sequência de vídeo coerente guiada por texto e fala opcional, alimentada pelo LTX-2.3 e pelo LTX 2.3 VBVR LoRA. VBVR significa raciocínio visual baseado em vídeo: ele ajuda o modelo a manter identidades, relações espaciais e causa e efeito consistentes em todos os quadros, para que suas cenas pareçam intencionais em vez de aleatórias. O gráfico inclui prompts sensíveis à fala, amostragem LTX em duas etapas, suavização de movimento e upscale/exportação final para MP4.
Criadores que precisam de continuidade narrativa, movimento crível ou tempo de diálogo acharão o workflow LTX 2.3 VBVR especialmente útil. Forneça um quadro de referência forte, descreva a ação e as interações, e insira opcionalmente uma linha falada que é transcrita automaticamente e incorporada no prompt para melhor alinhamento de lábios e tempo.
Modelos principais no workflow Comfyui LTX 2.3 VBVR#
- Modelo de geração de vídeo LTX-2.3 22B da Lightricks, a principal espinha dorsal de difusão para decodificação de imagem-para-vídeo e condicionada por áudio. Hugging Face: Lightricks/LTX-2.3
- LTX-2.3 Video VAE para codificação/decodificação de latentes de vídeo, emparelhado com o checkpoint base para decodificação em mosaico eficiente. Hugging Face: Lightricks/LTX-2.3
- Modelo latente LTX-2.3 Spatial Upscaler x2 para melhorar o detalhe espacial após a primeira passagem. Hugging Face: Lightricks/LTX-2.3
- Codificador de texto Gemma 3 12B empacotado para LTX-2, usado aqui para analisar instruções complexas e tokens de diálogo. Hugging Face: Comfy-Org/ltx-2
- LTX 2.3 VBVR LoRA para estrutura de cena centrada em raciocínio, interação de objetos e continuidade ao longo do tempo. Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- Modelo de interpolação de quadros RIFE para suavizar o movimento entre quadros gerados. GitHub: hzwer/Practical-RIFE
- Modelo de reconhecimento de fala Whisper para infusão opcional de áudio-para-texto no prompt. GitHub: openai/whisper
Como usar o workflow Comfyui LTX 2.3 VBVR#
O gráfico é organizado em grupos claros. Você configura entradas, a pilha de modelos e configurações de vídeo, então os amostradores LTX geram quadros que são opcionalmente interpolados e ampliados antes da exportação.
Carregar Referência de Imagem#
Use Load Image (Input) (#5525) para escolher um quadro de referência forte e no estilo. A imagem é redimensionada por ImageResizeKJv2 (#5280) para a largura e altura escolhidas enquanto preserva a composição. Um nó de pré-visualização confirma o que o modelo realmente verá. Boas imagens de referência com sujeitos claros e iluminação dão ao conjunto LTX 2.3 VBVR uma âncora confiável para identidade e estilo.
Configuração de Vídeo#
Defina Width (Input) (#5284), Height (Input) (#5286), Seconds (Input) (#5573), e a base Frame Rate (#5289). O gráfico calcula automaticamente a contagem de quadros para que o tempo permaneça consistente quando você muda a duração ou fps. Se planejar habilitar a interpolação mais tarde, você pode escolher um fps base modesto para economizar tempo e deixar o RIFE adicionar suavidade. Essas configurações também informam o nó de condicionamento para que o movimento e o ritmo permaneçam coerentes.
Modelo#
CheckpointLoaderSimple (#5493) carrega o LTX-2.3. O gráfico anexa o LTX 2.3 VBVR LoRA via LoraLoaderModelOnly (#5616) e pode opcionalmente aplicar um LoRA destilado e um LoRA detalhador para fidelidade extra. LTXAVTextEncoderLoader (#5494) traz o codificador de texto baseado em Gemma, enquanto VAELoader (#5629) e LTXVAudioVAELoader (#5492) fornecem os VAE de vídeo e áudio. Dois nós ReservedVRAMSetter equilibram o uso de memória para que execuções longas permaneçam estáveis.
Prompt de Texto para Vídeo#
Escreva sua cena em Text Prompt (Input) (#5620). Para injetar diálogo alinhado com o áudio, inclua um marcador como: A mulher diz "<Transcript1>". Insira a linha real em Speech Line (Input) (#5524) ou deixe o Whisper produzi-la a partir do áudio; StringReplace (#5226) e JoinStringMulti (#5602) substituem <Transcript1> pela transcrição. TextGenerateLTX2Prompt (#5488) então compõe uma instrução refinada, que Enhanced Prompt (Positive) (#5174) codifica antes que LTXVConditioning (#5173) prepare a orientação final. Verbos claros, referências a sujeitos e dicas espaciais dão ao LTX 2.3 VBVR LoRA o contexto necessário para raciocinar ao longo do tempo.
Pré-processamento de Áudio#
Traga uma faixa de voz com Load Audio (Input) (#5590) ou conecte TTS. AudioAdjustVolume (#5601) normaliza os níveis. Se você quiser diálogo sensível ao prompt, use o Whisper via Load Whisper (mtb) (#5606) e Audio To Text (mtb) (#5607) para gerar a transcrição usada no prompt. O mesmo áudio também é codificado como um latente e mais tarde incorporado de volta ao vídeo final para que dicas de lábios e tempo possam influenciar a geração.
Amostragem LTX#
LTXVPreprocess (#5240) e LTXVImgToVideoInplace (#5245) convertem seu quadro de referência em uma sequência latente inicial, preservando a identidade central enquanto permitem movimento. O subgráfico Samplers (#5278) executa um processo em duas etapas com guias CFG e um agendador, produzindo latentes espaço-temporais que respeitam tanto seu prompt quanto o raciocínio LTX 2.3 VBVR LoRA. Latentes de áudio são concatenados com latentes de vídeo para que o tempo da fala possa informar o movimento. LTXVSpatioTemporalTiledVAEDecode (#5237) decodifica quadros, e LTXVAudioVAEDecode (#5103) restaura a trilha de áudio.
Interpolação de Quadros e Upscale#
RIFE VFI (#5554) interpola entre quadros para criar movimento mais suave e atingir sua taxa de reprodução alvo quando combinado com o fps base. RTXVideoSuperResolution (#5631) melhora o detalhe e reduz artefatos de compressão, melhorando a legibilidade de rostos, bordas e pequenos objetos. Use esta etapa para equilibrar velocidade e qualidade: interpole para suavidade, então amplie para nitidez.
Exportação#
Escolha entre CreateVideo (#5599) para uma simples mux ou VHS_VideoCombine (#5618) para mais controle sobre formato, metadados e corte. O pipeline escreve um H.264 MP4 via SaveVideo (#5597). A taxa de quadros é derivada de suas configurações e da etapa de interpolação para que a reprodução corresponda à intenção de movimento que você criou no início.
Nós principais no workflow Comfyui LTX 2.3 VBVR#
LoraLoaderModelOnly (#5616)#
Carrega o LTX 2.3 VBVR LoRA que melhora a continuidade lógica, interação de objetos e movimento sensível à câmera. Ajuste o peso do LoRA para equilibrar a influência do raciocínio com o estilo do modelo base e outros LoRAs. Este nó é central para o visual distinto e a coerência que definem o workflow LTX 2.3 VBVR. Para uso de nós LTX e LoRA, veja Lightricks/ComfyUI-LTXVideo e o cartão VBVR LoRA acima.
TextGenerateLTX2Prompt (#5488)#
Assembla o prompt positivo final mesclando sua descrição base, a referência de imagem e o token de diálogo substituído de <Transcript1>. Mantenha as instruções concisas, explícitas e consistentes sobre sujeitos e ações para que o modelo possa raciocinar ao longo do tempo. É aqui que você codifica a intenção que o LTX 2.3 VBVR LoRA reforçará durante a amostragem.
LTXVConditioning (#5173)#
Empacota condicionamento positivo e negativo e encaminha informações de tempo para que o movimento e o ritmo alinhem-se com sua escolha de fps. Se você mudar a taxa de quadros nas configurações, atualize-a aqui para manter a dinâmica de movimento consistente. Negativos fortes ajudam a prevenir quadros parados, marcas d'água ou sobreposições indesejadas de aparecerem na sequência.
Samplers (#5278)#
O bloco de sampler em duas etapas coordena ruído, orientação e agendamento para transformar os latentes de imagem e áudio em um vídeo coerente. Os ajustes mais impactantes são os steps totais, a image strength da etapa inicial I2V, e o noise_seed para reprodutibilidade. Ajuste-os cuidadosamente para equilibrar a fidelidade ao quadro de referência contra a disposição de seguir novos movimentos e ações.
RIFE VFI (#5554)#
Interpola quadros para um movimento mais suave ou para alcançar um fps efetivo mais alto sem regenerar a sequência. Aumente a interpolação quando seu fps base for baixo ou quando o movimento parecer trêmulo; diminua para preservar o ritmo gerativo original. O modelo é amplamente usado para VFI de alta qualidade; veja o projeto RIFE no GitHub.
Extras opcionais#
- Truque de diálogo com LTX 2.3 VBVR: escreva uma frase natural com o marcador, por exemplo, A mulher diz "<Transcript1>", então forneça a linha em Speech Line ou deixe o Whisper transcrever o áudio para que o prompt e os lábios se alinhem.
- Prompting para raciocínio: indique quem faz o quê, onde e por quê. Use nomes de sujeitos consistentes e dicas temporais como então, enquanto, e à medida que a câmera se move para aproveitar as forças do VBVR.
- Iterações mais rápidas: comece com uma duração mais curta ou fps base mais baixo, confirme os momentos de movimento, então aumente a interpolação ou os segundos para terminar.
- Dicas de estabilidade: se você notar deriva de identidade, diminua ligeiramente a força de imagem-para-vídeo ou aumente o peso do VBVR LoRA; se você notar sobreconstrangimento, faça o inverso.
Agradecimentos#
Este workflow implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos ao @Benji’s AI Playground pela contribuição e manutenção do 2.3 VBVR Workflow Source. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- LTX/2.3 VBVR Workflow Source
- Docs / Release Notes: LTX 2.3 VBVR Workflow Source @Benji’s AI Playground
Nota: O uso dos modelos, datasets e códigos referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.