
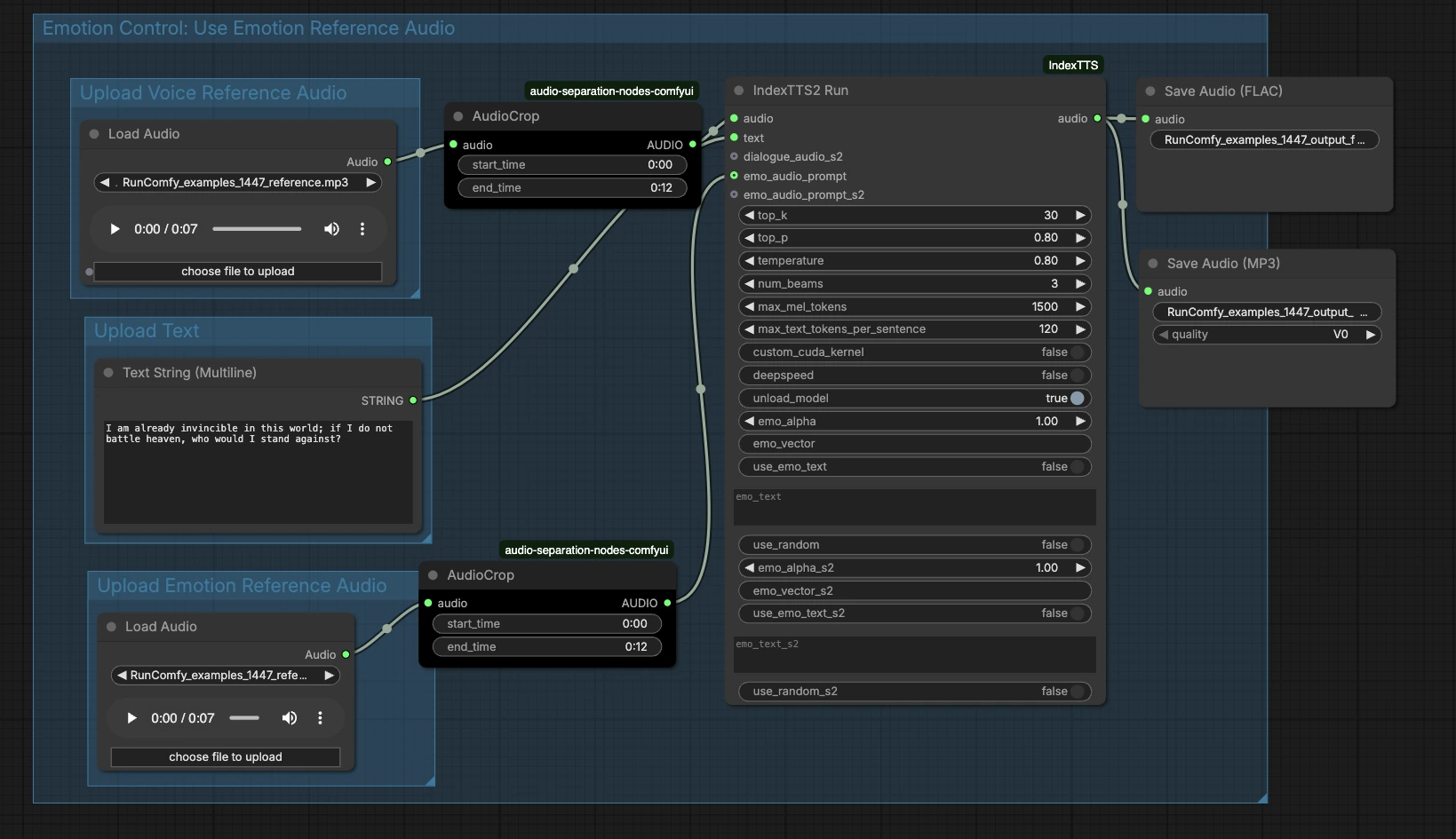
Fluxo de trabalho IndexTTS2 ComfyUI: Clonagem de voz emocional com áudio de referência#
Este fluxo de trabalho IndexTTS2 ComfyUI transforma um clipe de referência curto em fala natural e expressiva que corresponde ao timbre e estilo do falante. Você fornece áudio de referência limpo, sugestão de emoção opcional e seu script; o gráfico gera clones de voz de alta qualidade e os exporta como FLAC para uso arquivístico ou MP3 para compartilhamento rápido.
Construído em torno do modelo IndexTTS‑2 e dos nós ComfyUI IndexTTS, o fluxo de trabalho é ideal para criadores, designers de personagens, educadores e usuários do RunComfy que desejam TTS emocional rápido e reprodutível. Tudo acontece dentro do ComfyUI, para que você possa inspecionar entradas, ajustar configurações e iterar rapidamente em exemplos de narração, diálogo e locução.
Modelos principais no fluxo de trabalho ComfyUI IndexTTS2#
- IndexTTS‑2 da IndexTeam. Um sistema moderno de texto-para-fala que realiza clonagem de voz condicionada por referência e controle de prosódia expressiva. Condiciona-se em um exemplo curto do falante e, opcionalmente, em pistas de emoção para renderizar fala natural a partir do texto. Veja o cartão do modelo no Hugging Face e o artigo acompanhante para detalhes arquitetônicos e de treinamento: IndexTTS‑2, projeto IndexTTS, artigo IndexTTS‑2.
Como usar o fluxo de trabalho Comfyui IndexTTS2 ComfyUI#
Em alto nível, o gráfico aceita três entradas — áudio de timbre de referência, texto e áudio de emoção opcional — e, em seguida, executa a geração e exporta o resultado. Os grupos abaixo mostram onde adicionar entradas e como elas se conectam à fala final.
Carregar Áudio de Referência de Voz#
Este grupo prepara a identidade do falante. Carregue um exemplo limpo da voz alvo em LoadAudio (#13), de preferência um único falante falando claramente sem música ou efeitos. Use AudioCrop (#37) para isolar um segmento estável para que o sistema aprenda um timbre consistente. Segmentos curtos com tom estável e entrega neutra geralmente produzem a clonagem mais confiável. A referência recortada é enviada para frente para condicionar o gerador.
Carregar Texto#
Digite seu script em PrimitiveStringMultiline (#14). A pontuação clara ajuda o modelo a inferir pausas e ênfases, portanto, escreva o texto da maneira que você deseja que seja falado. Se você planeja leituras de várias frases, mantenha cada frase bem formada e evite emojis ou símbolos incomuns. O texto flui diretamente para o nó de síntese para renderização.
Carregar Áudio de Referência de Emoção#
Forneça um clipe opcional que capture a emoção ou entrega que você deseja — por exemplo, empolgado, calmo ou sombrio — via LoadAudio (#15). Recorte-o com AudioCrop (#38) para manter apenas a parte expressiva que você deseja imitar. Isso é separado da referência de timbre e foca no ritmo, energia e tom. Se você pular esta etapa, o fluxo de trabalho IndexTTS2 ComfyUI dependerá apenas do texto para a prosódia.
Controle de Emoção: Use Áudio de Referência de Emoção#
Esta área conecta sua sugestão de emoção ao gerador. O clipe de emoção recortado alimenta a entrada emo_audio_prompt em IndexTTS2Run (#12), guiando a cadência e a intensidade enquanto preserva a voz alvo. Você também pode usar os controles de texto de emoção do nó para ajustar o estilo se não tiver um exemplo de áudio de emoção. Na prática, o áudio de emoção tende a dar expressividade mais forte e consistente, enquanto o texto de emoção fornece uma direção mais leve. Combine-os quando quiser tanto um exemplo concreto quanto uma dica textual.
Gerar e Exportar#
IndexTTS2Run (#12) sintetiza fala usando seu texto, referência de timbre e qualquer orientação de emoção. A saída é direcionada para SaveAudio (#17) para um FLAC sem perdas e para SaveAudioMP3 (#39) para uma prévia pequena e amigável para a web. Use os campos de nome de arquivo nos nós de salvamento para manter as tomadas organizadas entre iterações. Este design facilita comparar diferentes textos ou emoções mantendo a mesma identidade de falante.
Nós principais no fluxo de trabalho Comfyui IndexTTS2 ComfyUI#
IndexTTS2Run (#12)#
Este é o gerador principal que envolve o IndexTTS‑2 e expõe controles para amostragem, busca de feixe e condicionamento de emoção. Ajuste top_p, top_k e temperature para equilibrar estabilidade e variedade — valores mais baixos dão leituras mais consistentes, valores mais altos aumentam a espontaneidade. Use num_beams quando quiser que o nó procure mais leituras candidatas, trocando velocidade por qualidade. Para scripts longos, max_mel_tokens e max_text_tokens_per_sentence ajudam a evitar sobrecargas limitando tamanhos de bloco de áudio e texto. A emoção pode ser direcionada com emo_audio_prompt, emo_alpha para força de mistura, ou com use_emo_text e emo_text quando preferir uma dica textual. Auxiliares de desempenho como deepspeed, custom_cuda_kernel e unload_model estão disponíveis dependendo do seu hardware. A implementação do nó é fornecida pelos nós personalizados ComfyUI IndexTTS: ComfyUI_IndexTTS, e o modelo subjacente está documentado aqui: IndexTTS‑2, projeto IndexTTS.
AudioCrop (#37) — timbre de referência#
Use este nó para isolar um trecho limpo e estável do seu exemplo de falante. Evite ruído de fundo, risos ou emoção extrema, pois esses detalhes podem vazar na voz clonada. Recortar para um tom consistente melhora o bloqueio de identidade e reduz artefatos indesejados.
AudioCrop (#38) — sugestão de emoção#
Este recorte seleciona a dica expressiva que controla a entrega. Escolha uma parte com o ritmo ou intensidade exatos que você deseja e mantenha-a concisa para evitar diluição do sinal. Para melhor coerência, use sugestões de emoção do mesmo falante que a referência de timbre sempre que possível.
Extras opcionais#
- Mantenha o áudio de referência seco e monofônico; remova reverberação, música de fundo e compressão pesada para uma clonagem mais limpa.
- Pontue intencionalmente. Vírgulas, pontos e pontos de interrogação ajudam o modelo a colocar pausas e inflexões que correspondem à sua intenção.
- Para tomadas reprodutíveis, desative a aleatoriedade no nó ou mantenha anotações sobre seleções de texto e áudio para que você possa regenerar a mesma saída posteriormente.
- Se a memória de vídeo estiver apertada, habilite a descarga do modelo entre execuções; isso pode adicionar um pequeno custo de tempo, mas libera memória para outros gráficos.
- Respeite os direitos de voz. Use apenas gravações de referência que você está autorizado a clonar e divulgue a fala sintética quando necessário.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos sinceramente ao RunningHub pela referência do fluxo de trabalho, ao RunComfy pelo fluxo de trabalho Cloud Save, à Index Team pelo IndexTTS e IndexTTS-2, aos autores do artigo IndexTTS2, e a billwuhao pelos nós personalizados ComfyUI IndexTTS por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- RunningHub/Workflow Reference
- Documentação / Notas de lançamento: RunningHub post
- RunComfy/Cloud Save Workflow
- Documentação / Notas de lançamento: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.