
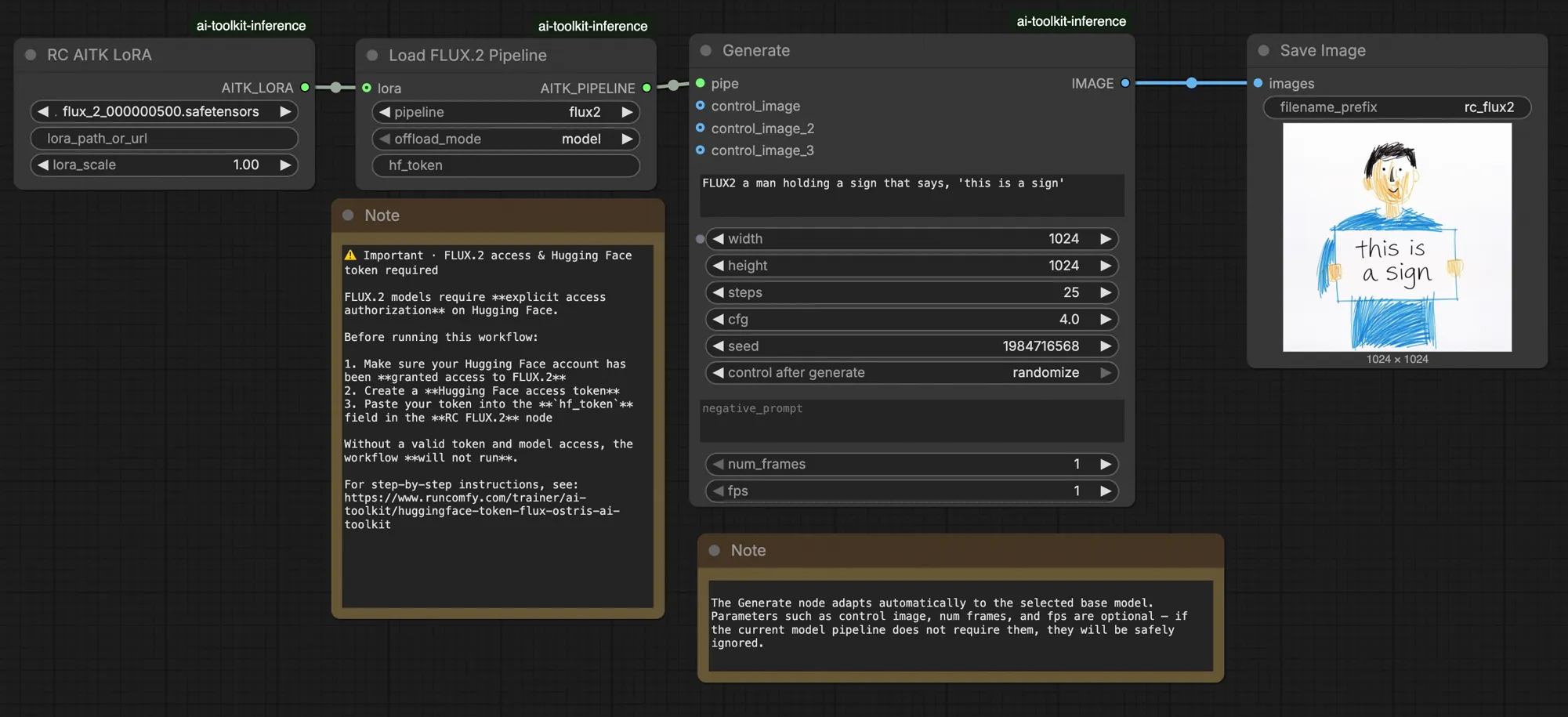
FLUX.2 LoRA ComfyUI Inferência: saída de LoRA do AI Toolkit compatível com treinamento com o pipeline FLUX.2 Dev#
Este workflow de produção pronto para uso RunComfy executa a inferência FLUX.2 Dev LoRA no ComfyUI através de RC FLUX.2 Dev (Flux2Pipeline) (alinhamento a nível de pipeline, não um gráfico de amostragem genérico). RunComfy construiu e disponibilizou este nó personalizado de código aberto — veja os repositórios runcomfy-com — e você controla a aplicação do adaptador com lora_path e lora_scale.
Nota: Este workflow requer uma máquina 3XL para rodar.
Por que a inferência FLUX.2 LoRA ComfyUI muitas vezes parece diferente no ComfyUI#
As pré-visualizações de treinamento do AI Toolkit são renderizadas através de um pipeline FLUX.2 específico do modelo, onde a codificação de texto, o agendamento e a injeção de LoRA são projetados para funcionar juntos. No ComfyUI, reconstruir o FLUX.2 com um gráfico diferente (ou um caminho de carregamento de LoRA diferente) pode alterar essas interações, então copiar o mesmo prompt, passos, CFG e semente ainda produz um desvio visível. Os nós do pipeline RunComfy RC fecham essa lacuna executando o FLUX.2 de ponta a ponta no Flux2Pipeline e aplicando seu LoRA dentro desse pipeline, mantendo a inferência alinhada com o comportamento de pré-visualização. Fonte: Repositórios de código aberto RunComfy.
Como usar o workflow de inferência FLUX.2 LoRA ComfyUI#
Passo 1: Obtenha o caminho do LoRA e carregue-o no workflow (2 opções)#
⚠️ Importante · Acesso FLUX.2 & token Hugging Face necessário#
Os modelos FLUX.2 Dev requerem autorização de acesso explícita no Hugging Face.
Antes de executar este workflow:
- Certifique-se de que sua conta Hugging Face foi autorizada a acessar o FLUX.2 (Dev)
- Crie um token de acesso Hugging Face
- Cole seu token no campo
hf_tokenno nó Load Pipeline
Sem um token válido e acesso adequado ao modelo, o workflow não será executado. Para instruções passo a passo, veja Token Hugging Face para FLUX.2.
Opção A — Resultado de treinamento RunComfy → download para ComfyUI local:
- Vá para Treinador → Ativos LoRA
- Encontre o LoRA que deseja usar
- Clique no menu ⋮ (três pontos) à direita → selecione Copiar Link do LoRA
- Na página de workflow do ComfyUI, cole o link copiado no campo de entrada Download no canto superior direito da UI
- Antes de clicar em Download, certifique-se de que a pasta de destino está definida para ComfyUI > models > loras (esta pasta deve ser selecionada como destino de download)
- Clique em Download — isso garante que o arquivo LoRA seja salvo no diretório
models/lorascorreto - Após o término do download, atualize a página
- O LoRA agora aparece no menu suspenso de seleção de LoRA no workflow — selecione-o

Opção B — URL direto do LoRA (substitui a Opção A):
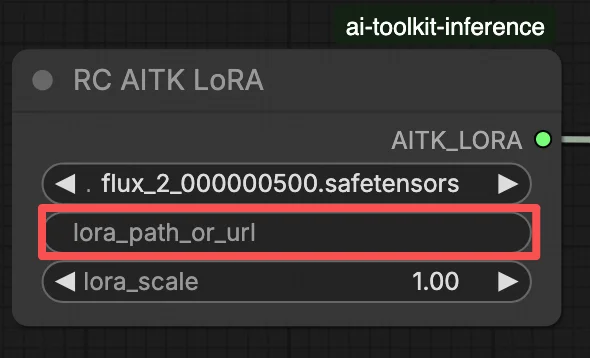
- Cole o URL direto de download
.safetensorsno campo de entradapath / urldo nó LoRA - Quando um URL é fornecido aqui, ele substitui a Opção A — o workflow carrega o LoRA diretamente do URL em tempo de execução
- Não é necessário download local ou colocação de arquivo
Dica: confirme que o URL resolve para o arquivo real .safetensors (não uma página de destino ou redirecionamento).
Passo 2: Combine os parâmetros de inferência com suas configurações de amostra de treinamento#
No nó LoRA, selecione seu adaptador em lora_path (Opção A), ou cole um link direto .safetensors em path / url (Opção B substitui o menu suspenso). Em seguida, defina lora_scale para a mesma força que você usou durante as pré-visualizações de treinamento e ajuste a partir daí.
Os parâmetros restantes estão no nó Generate (e, dependendo do gráfico, no nó Load Pipeline):
prompt: seu prompt de texto (inclua palavras de ativação se você as treinou)width/height: resolução de saída; combine com o tamanho da pré-visualização de treinamento para a comparação mais limpa (múltiplos de 16 são recomendados para FLUX.2)sample_steps: número de passos de inferência (25 é um padrão comum)guidance_scale: valor de CFG/orientação (4.0 é um padrão comum)seed: semente fixa para reproduzir; altere para explorar variaçõesseed_mode(apenas se presente): escolhafixedourandomizenegative_prompt(apenas se presente): FLUX.2 é destilado por orientação neste workflow, então prompts negativos são ignoradoshf_token: token de acesso Hugging Face; necessário para download do modelo FLUX.2 Dev (cole-o no nó Load Pipeline)
Dica de alinhamento de treinamento: se você personalizou valores de amostragem durante o treinamento (seed, guidance_scale, sample_steps, palavras de ativação, resolução), espelhe esses valores exatos aqui. Se você treinou no RunComfy, abra Treinador → Ativos LoRA > Config para ver o YAML resolvido e copiar as configurações de pré-visualização/amostra nos nós do workflow.

Passo 3: Execute a Inferência FLUX.2 LoRA ComfyUI#
Clique em Queue/Run — o nó SaveImage grava os resultados na sua pasta de saída do ComfyUI.
Lista de verificação rápida:
- ✓ LoRA está: baixado em
ComfyUI/models/loras(Opção A), ou carregado via um URL direto.safetensors(Opção B) - ✓ Página atualizada após download local (apenas Opção A)
- ✓ Parâmetros de inferência correspondem à configuração de
samplede treinamento (se personalizado)
Se tudo acima estiver correto, os resultados da inferência aqui devem corresponder de perto às suas pré-visualizações de treinamento.
Solução de Problemas de Inferência FLUX.2 LoRA ComfyUI#
A maioria das diferenças "pré-visualização de treinamento vs inferência ComfyUI" do FLUX.2 vem de diferenças a nível de pipeline (como o modelo é carregado, agendado e como o LoRA é mesclado), não de um único botão errado. Este workflow RunComfy restaura a linha de base "compatível com treinamento" mais próxima ao executar a inferência através de RC FLUX.2 Dev (Flux2Pipeline) de ponta a ponta e aplicando seu LoRA dentro desse pipeline via lora_path / lora_scale (em vez de empilhar nós de carregador/amostrador genéricos).
(1) Flux.2 com erro Lora: "mul_cuda" não implementado para 'Float8_e4m3fn'#
Por que isso acontece Isso geralmente ocorre quando o FLUX.2 é carregado com pesos Float8/FP8 (ou quantização de precisão mista) e o LoRA é aplicado através de um caminho genérico de LoRA no ComfyUI. A mesclagem de LoRA pode forçar operações Float8 não suportadas (ou promoções mistas Float8 + BF16), o que desencadeia o erro de tempo de execução mul_cuda Float8.
Como corrigir (recomendado)
- Execute a inferência através de RC FLUX.2 Dev (Flux2Pipeline) e carregue o adaptador apenas via
lora_path/lora_scalepara que a mesclagem de LoRA aconteça no pipeline alinhado ao AI Toolkit, não via um carregador de LoRA genérico empilhado no topo. - Se você estiver depurando em um gráfico não RC: evite aplicar um LoRA em cima de pesos de difusão Float8/FP8. Use um caminho de carregamento compatível com BF16/FP16 para FLUX.2 antes de adicionar o LoRA.
(2) Incompatibilidades de forma LoRA devem falhar rapidamente em vez de corromper o estado da GPU e causar OOM/instabilidade do sistema#
Por que isso acontece Isso é quase sempre uma incompatibilidade de base: o LoRA foi treinado para uma família de modelos diferente (por exemplo, FLUX.1) mas está sendo aplicado ao FLUX.2 Dev. Você geralmente verá muitas linhas lora key not loaded e então incompatibilidades de forma; no pior caso, a sessão pode se tornar instável e terminar em OOMs.
Como corrigir (recomendado)
- Certifique-se de que o LoRA foi treinado especificamente para
black-forest-labs/FLUX.2-devcom AI Toolkit (FLUX.1 / FLUX.2 / variantes Klein não são intercambiáveis). - Mantenha o gráfico "caminho único" para LoRA: carregue o adaptador apenas através da entrada
lora_pathdo workflow e deixe o Flux2Pipeline lidar com a mesclagem. Não empilhe um carregador LoRA genérico adicional em paralelo. - Se você já encontrou uma incompatibilidade e o ComfyUI começar a produzir erros CUDA/OOM não relacionados posteriormente, reinicie o processo ComfyUI para redefinir completamente o estado da GPU + modelo, então tente novamente com um LoRA compatível.
(3) Flux.2 Dev - Usar LoRAs mais do que dobra o tempo de inferência#
Por que isso acontece Um LoRA pode tornar o FLUX.2 Dev muito mais lento quando o caminho do LoRA força trabalho extra de remendo/desquantização ou aplica pesos em um caminho de código mais lento do que o modelo base sozinho.
Como corrigir (recomendado)
- Use o caminho RC FLUX.2 Dev (Flux2Pipeline) deste workflow e passe seu adaptador através de
lora_path/lora_scale. Nesta configuração, o LoRA é mesclado uma vez durante o carregamento do pipeline (estilo AI Toolkit), então o custo de amostragem por passo permanece próximo ao modelo base. - Quando você está buscando comportamento compatível com pré-visualização, evite empilhar múltiplos carregadores de LoRA ou misturar caminhos de carregador. Mantenha para um
lora_path+ umlora_scaleaté que a linha de base corresponda.
Nota Neste workflow FLUX.2 Dev, o FLUX.2 é destilado por orientação, então negative_prompt pode ser ignorado pelo pipeline mesmo se um campo UI existir — combine pré-visualizações usando a formulação do prompt + guidance_scale + lora_scale primeiro.
Execute a Inferência FLUX.2 LoRA ComfyUI agora#
Abra o workflow, defina lora_path, e clique em Queue/Run para obter resultados FLUX.2 Dev LoRA que se aproximam das suas pré-visualizações de treinamento do AI Toolkit.

