
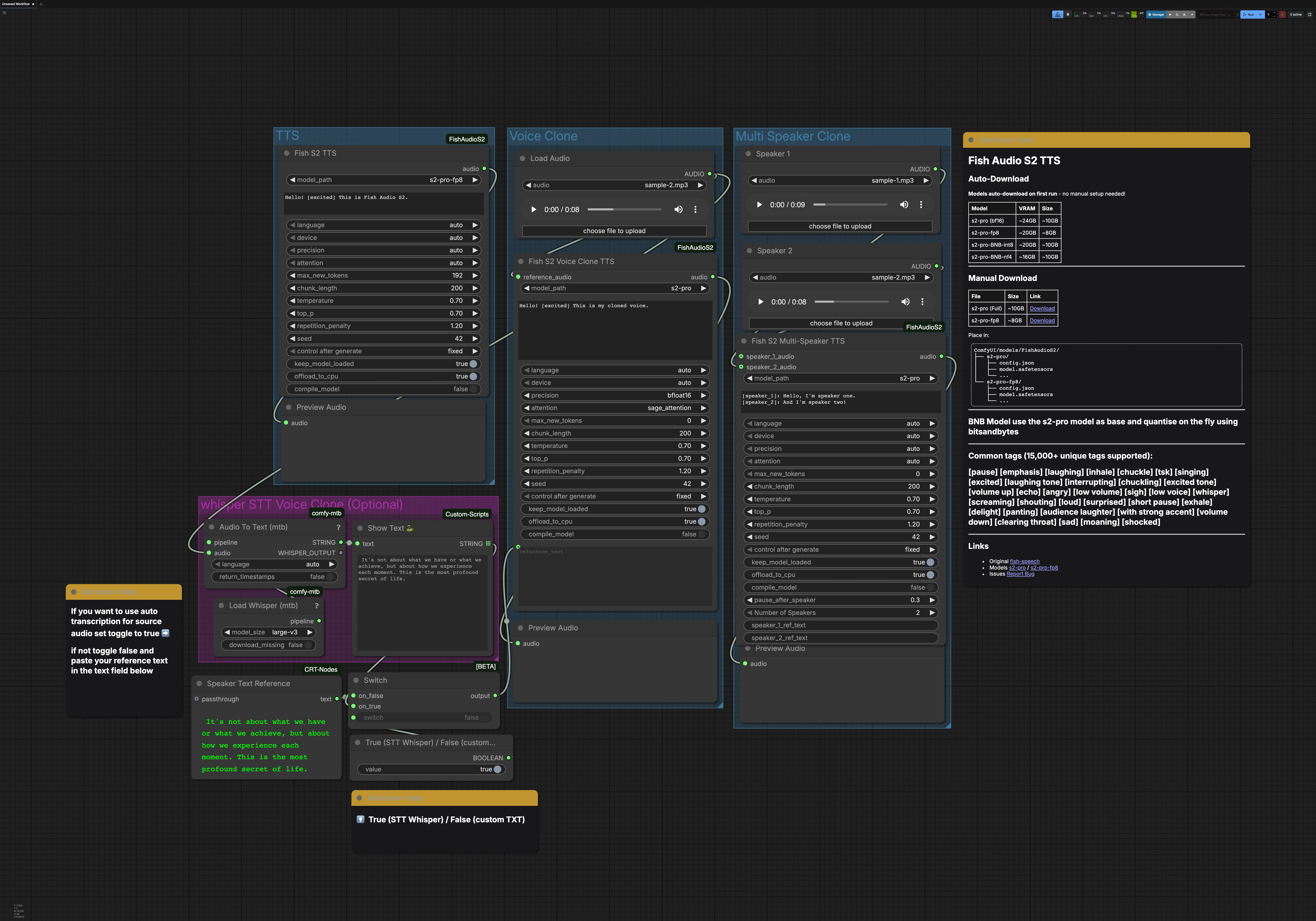
Fish Audio S2 TTS para ComfyUI: TTS de alta qualidade, clonagem de voz e diálogo multi-locutor#
Fish Audio S2 TTS é um fluxo de trabalho pronto para uso do ComfyUI que transforma texto em fala natural, clona uma voz a partir de um clipe de referência curto e gera conversas de múltiplos locutores. É alimentado pela família Fish Audio S2-Pro e suporta controle de estilo rico via tags de emoção e prosódia, como [excited], [whisper], e [laughing].
Este fluxo de trabalho é ideal para criadores, equipes de produto e desenvolvedores que desejam síntese de fala flexível e expressiva dentro do ComfyUI. Inclui opcionalmente texto para fala para captura rápida de transcrição, detecção automática de idioma e múltiplas escolhas de precisão, incluindo fp8 e sage_attention para inferência eficiente.
Nota: Execute este fluxo de trabalho em uma máquina 2X Large ou maior. Instâncias menores podem ficar sem memória (OOM).
Modelos principais no fluxo de trabalho Comfyui Fish Audio S2 TTS#
- Fish Audio S2-Pro — o modelo de texto para fala generativo central usado para TTS de um único locutor, clonagem de voz e diálogo multi-locutor. Ele suporta extensos tokens de estilo e síntese multilíngue model card e faz parte do projeto Fish-Speech repo.
- Fish Audio S2-Pro FP8 — uma variante do S2-Pro eficiente em termos de memória que reduz as necessidades de VRAM com mínimas perdas de qualidade, recomendada para GPUs restritas model card.
- OpenAI Whisper large-v3 — um modelo opcional de texto para fala usado para transcrever automaticamente seu áudio de referência ao preparar prompts de clonagem de voz repo.
Como usar o fluxo de trabalho Comfyui Fish Audio S2 TTS#
Este fluxo de trabalho contém três caminhos principais que podem ser executados de forma independente: TTS, Clonagem de Voz e Clonagem de Multi-Locutor. Um grupo opcional Whisper STT pode gerar a transcrição para clonagem de voz. Cada caminho termina com uma prévia de áudio para que você possa monitorar os resultados rapidamente.
Grupo TTS#
O nó FishS2TTS (#42) realiza a conversão direta de texto para fala com Fish Audio S2 TTS. Insira seu roteiro na caixa de texto do nó e adicione tags de estilo como [excited], [pause] ou [whisper] para moldar a emoção e o ritmo. A detecção de idioma é automática, então você pode escrever no idioma alvo e o modelo se adapta. Escolha a variante S2-Pro que se adapta à memória de sua GPU, por exemplo, fp8 para cargas mais leves. A saída é direcionada para PreviewAudio para audição instantânea.
Grupo de Clonagem de Voz#
Use LoadAudio para fornecer um clipe de referência curto e limpo da voz alvo, depois encaminhe-o para FishS2VoiceCloneTTS (#14). Forneça a transcrição que corresponda ao estilo de fala desejado; um texto preciso ajuda o modelo a preservar o ritmo e o sotaque. Você pode dirigir o texto de referência do grupo STT ou digitar o seu próprio, e pode adicionar tags de estilo para refinar a emoção e a entrega. As escolhas de precisão e backend de atenção equilibram velocidade, memória e estabilidade para linhas longas. O clone sintetizado é enviado para PreviewAudio para que você possa iterar rapidamente.
Grupo de Clonagem de Multi-Locutor#
Carregue um clipe de referência por locutor usando os nós LoadAudio, depois conecte-os ao FishS2MultiSpeakerTTS (#41). Forneça um roteiro de diálogo que rotule cada turno com [speaker_1], [speaker_2], e assim por diante. Este modelo inclui dois locutores por padrão, e o nó suporta escalonamento até oito vozes distintas quando configurado adequadamente. Você pode misturar prosa narrativa, tags e diálogo para controlar o fluxo e a emoção de cada personagem. A mistura final é pré-visualizada para que o tempo e a clareza possam ser verificados.
Whisper STT para clonagem de voz (opcional)#
Load Whisper (mtb) (#6) com large-v3 alimenta Audio To Text (mtb) (#7) para transcrever automaticamente um clipe de referência. O texto reconhecido é exibido por ShowText|pysssss (#8). Um pequeno alternador construído com ComfySwitchNode (#34) e um controle booleano permite que você escolha entre a saída STT (true) ou seu próprio texto digitado de Text Box line spot (#31) (false). Isso é útil quando você deseja uma transcrição básica rápida ou ao criar um prompt preciso para clonagem.
Nós principais no fluxo de trabalho Comfyui Fish Audio S2 TTS#
FishS2TTS (#42)#
Gera fala de um único locutor a partir de texto com tags de estilo opcionais e detecção automática de idioma. Ajuste a variante do modelo para corresponder ao seu hardware, por exemplo, escolhendo fp8 quando a VRAM estiver apertada. Use o controle de semente para tomadas repetíveis e introduza pequenas mudanças ao explorar entregas alternativas. Para roteiros longos, selecione um backend de atenção otimizado para estabilidade.
FishS2VoiceCloneTTS (#14)#
Cria uma voz clonada condicionando com reference_audio e reference_text. Resultados melhores vêm de fala limpa com tom consistente e uma transcrição que espelha a cadência pretendida. As tags de estilo podem ser misturadas ao texto final para direcionar o humor sem prejudicar a identidade. As configurações de precisão e atenção ajudam a equilibrar qualidade e memória para linhas estendidas.
FishS2MultiSpeakerTTS (#41)#
Sintetiza conversas de multi-locutor emparelhando o áudio de referência de cada locutor com um diálogo marcado por rótulos [speaker_n]. Aumente o número de locutores conforme necessário e atribua clipes distintos para uma separação mais forte. Mantenha o áudio de referência de cada locutor consistente em tom para evitar mistura. Use a semente para mistura determinística ao renderizar cenas de múltiplas tomadas.
Extras opcionais#
- Use tags de estilo com cuidado. Comece com algumas como [excited], [whisper], [emphasis], [pause], e construa apenas conforme necessário para clareza.
- Para clonagem de voz, corte o silêncio do início e do fim da referência e evite ruído de fundo para preservar o timbre.
- Se a memória da GPU for limitada, prefira S2-Pro fp8 ou opções quantizadas em tempo de execução. Para máxima fidelidade, use maior precisão.
- Pontuação importa. Vírgulas e pontos melhoram a fraseação, e tags colocadas nos limites das cláusulas tendem a soar mais naturais.
- Para roteiros de multi-locutor, mantenha uma fala por linha e sempre prefixe com o rótulo [speaker_n] correto para manter a separação.
Recursos:
- Cartão de modelo Fish Audio S2-Pro: Hugging Face
- Variante S2-Pro fp8: Hugging Face
- Projeto Fish-Speech: GitHub
- Nós ComfyUI Fish Audio S2: GitHub
- Whisper large-v3: GitHub
Reconhecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos a Saganaki22 pelos nós personalizados ComfyUI-FishAudioS2, e Fish Audio pelo modelo S2-Pro por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.