
ComfyUI MOSS TTS: texto-para-fala, clonagem de voz, SFX e diálogo em um único fluxo de trabalho#
Este fluxo de trabalho ComfyUI MOSS TTS transforma texto em fala vívida de 24 kHz usando a família OpenMOSS MOSS-TTS. Ele cobre síntese rápida de falante único, clonagem de voz zero-shot a partir de um pequeno clipe de referência, design de voz descritivo, efeitos sonoros processuais e diálogo multisspeakers com referências opcionais por falante.
Construído sobre a pilha de nós oficial MOSS-TTS e a família de modelos, equilibra velocidade e qualidade. O caminho Local 1.7B é a via rápida prática em uma única GPU, enquanto os modelos maiores Delay 8B trocam velocidade por maior capacidade e expressividade. Se você precisar de prompts reutilizáveis, vozes clonadas ou diálogo dentro do ComfyUI, este fluxo de trabalho ComfyUI MOSS TTS foi projetado para você.
Modelos principais no fluxo de trabalho Comfyui ComfyUI MOSS TTS#
- OpenMOSS MOSS-TTS Local 1.7B. Transformer texto-para-fala amigável a uma única GPU que entrega fala natural rápida de 24 kHz para trabalhos de produção diária. Cartão do modelo: MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. Uma linha de modelo maior que enfatiza qualidade, similaridade de falante e prosódia ao custo de velocidade e memória. Cartão do modelo: MOSS-TTS.
- MOSS Audio Tokenizer. O codec aprendido que faz a ponte entre formas de onda e tokens discretos para os modelos MOSS-TTS, permitindo decodificação de alta fidelidade. Cartão do modelo: MOSS-Audio-Tokenizer.
Para detalhes de implementação e atualizações, veja os repositórios oficiais: OpenMOSS/MOSS-TTS e a pilha de nós que alimenta este fluxo de trabalho richservo/comfyui-moss-tts.
Como usar o fluxo de trabalho Comfyui ComfyUI MOSS TTS#
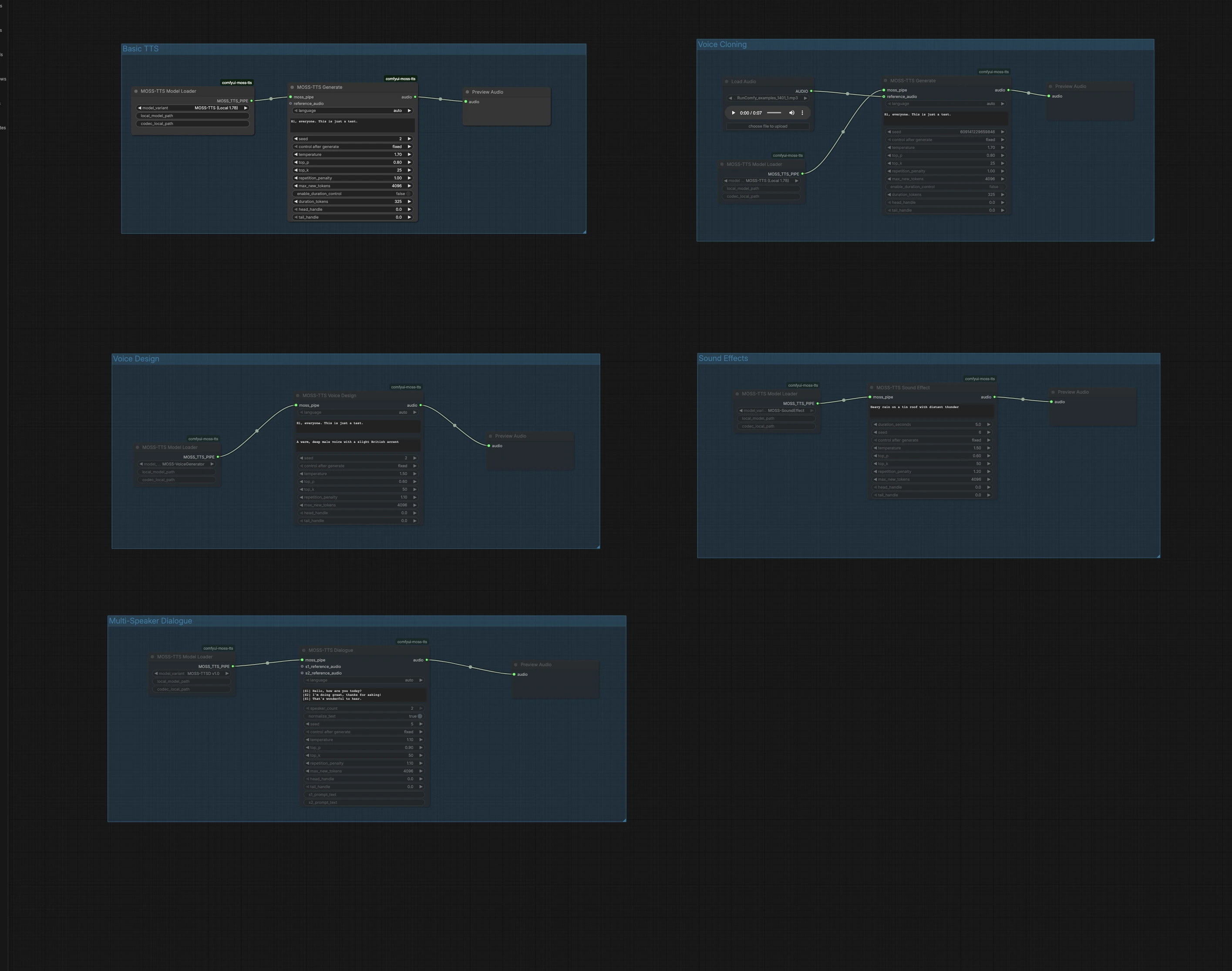
Este gráfico está organizado em cinco grupos independentes. Escolha o grupo que corresponde ao seu objetivo, execute-o e então visualize o áudio diretamente na tela. Você pode executar múltiplos grupos em paralelo para testar diferentes abordagens.
TTS Básico#
O grupo TTS Básico converte texto simples em fala com o caminho rápido Local 1.7B. Carregue o modelo em MossTTSModelLoader (#1), alimente seu texto para MossTTSGenerate (#2), então ouça em PreviewAudio (#3). O gerador condiciona seu prompt para moldar a pronúncia e a prosódia, então escreva naturalmente com pontuação para ritmo. Mantenha a semente fixa quando quiser tomadas repetíveis ou randomize-a ao explorar variantes de entrega.
Clonagem de Voz#
O grupo de Clonagem de Voz realiza clonagem de voz zero-shot a partir de um pequeno clipe de áudio de referência. Importe uma amostra de voz limpa usando LoadAudio (#4), conecte-a a MossTTSGenerate (#6) impulsionado por MossTTSModelLoader (#5) e forneça o texto-alvo. O modelo extrai timbre e estilo do falante da referência e renderiza seu novo script nessa voz. Use conteúdo neutro e ruído de fundo mínimo na referência para melhorar a similaridade e mantenha as durações moderadas para um retorno mais rápido.
Design de Voz#
O Design de Voz cria uma nova voz a partir de uma descrição em linguagem natural em vez de um clipe de exemplo. MossTTSVoiceDesign (#9) usa uma descrição de texto como "Uma voz masculina quente e profunda com um leve sotaque britânico," combinada com seu script, para sintetizar fala de 24 kHz. O nó é alimentado por um caminho de gerador de voz dedicado carregado via MossTTSModelLoader (#8). Isso é ideal quando você quer uma persona consistente e reproduzível sem precisar de gravações reais. Refine descritores com características como idade, timbre, sotaque e energia para direcionar o som.
Efeitos Sonoros#
Efeitos Sonoros geram áudio não verbal a partir de prompts de texto, útil para trilhas de fundo, transições ou camadas de ambiente. Com MossTTSSoundEffect (#12) e seu pipe de modelo de MossTTSModelLoader (#11), prompts como "Chuva forte em um telhado de zinco com trovões distantes" produzem texturas ricas e repetíveis. Use substantivos e ações concisos para definir a cena, então adicione alguns adjetivos para acertar a intensidade ou distância. Visualize em PreviewAudio (#13) e itere rapidamente para ajustar ao seu mix.
Diálogo Multi-Falante#
O grupo de Diálogo Multi-Falante renderiza conversas roteirizadas com clipes de referência opcionais por falante. Escreva seu script usando tags de falante entre colchetes, por exemplo [S1] Olá. e [S2] Oi!, então passe para MossTTSDialogue (#15) sob o pipe de modelo de MossTTSModelLoader (#14). Você pode anexar entradas de áudio de referência para S1 e S2 para clonar vozes específicas para cada papel, ou deixá-las vazias para que o modelo escolha falantes distintos apenas do contexto do texto. Este caminho é bem adequado para chamada e resposta, narração com falas de personagens ou protótipos de IU de voz.
Nós principais no fluxo de trabalho Comfyui ComfyUI MOSS TTS#
MossTTSModelLoader (#1)#
Carrega a família de modelos OpenMOSS selecionada e monta o pipeline interno TTS. Escolha a variante Local 1.7B para iteração rápida em uma única GPU, ou mude para um modelo maior Delay 8B quando você priorizar expressividade e similaridade. Mantenha um carregador por família de tarefas para que cada ramo downstream permaneça autônomo.
MossTTSGenerate (#2)#
O principal sintetizador de falante único que consome seu prompt de texto e áudio de referência opcional para produzir fala de 24 kHz. Forneça texto limpo e bem pontuado para um ritmo mais claro e conecte um pequeno clipe de voz quando precisar de clonagem zero-shot. Altere a semente entre fixa e aleatória para equilibrar reprodutibilidade e exploração.
MossTTSVoiceDesign (#9)#
Gera uma nova voz a partir de um prompt descritivo junto com o texto a ser falado. Foque a descrição no timbre, idade, sotaque e energia para direcionar a identidade enquanto a mantém concisa. Esta é uma escolha forte quando licenciar ou obter uma voz real não é prático.
MossTTSSoundEffect (#12)#
Sintetiza áudio não verbal a partir de uma curta descrição textual. Escreva prompts compactos que ancorem a fonte, ação e espaço, então itere para corresponder à cena. Ótimo para ambiência e one-shots dentro do mesmo gráfico ComfyUI MOSS TTS que você usa para diálogo.
MossTTSDialogue (#15)#
Analisa tags de falante entre colchetes e renderiza conversas em múltiplas turnos como uma única saída de áudio. Use [S1], [S2], e assim por diante para marcar cada linha, e opcionalmente conecte clipes de referência por falante para preservar identidade entre turnos. Mantenha as linhas concisas para as transferências mais confiáveis entre falantes.
Extras opcionais#
- Comece com o modelo Local 1.7B para rascunhos rápidos, então mude para um checkpoint Delay 8B quando precisar de maior similaridade ou prosódia mais rica.
- Para clonagem zero-shot, use um clipe de voz limpo de 5–15 s com reverberação e ruído mínimos para melhorar a transferência de timbre.
- Em diálogos, mantenha as tags de falante consistentes e livres de pontuação como
[S1]para evitar erros de análise. - Crie prompts de design de voz com 3–6 características como timbre, idade, sotaque, estilo e energia para resultados previsíveis.
- Use pontuação e quebras de linha em seu texto para controlar pausas e ritmo nas saídas do ComfyUI MOSS TTS.
- Adicione um nó
SaveAudioapós qualquer visualização se você quiser exportação automática de arquivos para renderizações em lote.
Referências: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos profundamente a richservo pelos nós personalizados ComfyUI MOSS-TTS, OpenMOSS pelo repositório MOSS-TTS, e OpenMOSS-Team pelos modelos MOSS-TTS (Delay 8B e Local 1.7B) e o MOSS Audio Tokenizer por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.