
InfiniteTalk: vídeo de retrato sincronizado com lábios a partir de uma única imagem no ComfyUI#
Este fluxo de trabalho InfiniteTalk do ComfyUI cria vídeos de retrato naturais e sincronizados com a fala a partir de uma única imagem de referência e um clipe de áudio. Ele combina a geração de imagem para vídeo do WanVideo 2.1 com o modelo de cabeça falante MultiTalk para produzir movimento labial expressivo e identidade estável. Se você precisa de clipes sociais curtos, dublagens de vídeo ou atualizações de avatar, o InfiniteTalk transforma uma foto estática em um vídeo falante fluido em minutos.
O InfiniteTalk é baseado na excelente pesquisa MultiTalk da MeiGen-AI. Para contexto e atribuições, veja o projeto de código aberto: MeiGen-AI/MultiTalk.
Modelos principais no fluxo de trabalho Comfyui InfiniteTalk#
- MultiTalk (GGUF, variante InfiniteTalk): Impulsiona o movimento facial consciente de fonemas a partir do áudio, para que os movimentos da boca e mandíbula acompanhem a fala naturalmente. Referência: Kijai/WanVideo_comfy_GGUF › InfiniteTalk e ideia original: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): O gerador primário de imagem para vídeo que preserva identidade, iluminação e pose enquanto anima os quadros. Pesos recomendados: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): Decodifica quadros latentes para RGB com mudança mínima de cor; fornecido nos pacotes WanVideo acima.
- Codificador de texto UMT5-XXL: Interpreta seus prompts positivos e negativos para ajustar estilo, cena e contexto de movimento. Família do modelo: google/umt5-xxl.
- CLIP Vision: Extrai embeddings visuais da sua imagem de referência para fixar identidade e aparência geral.
- Wav2Vec2 (Tencent GameMate): Converte fala bruta em recursos de áudio robustos para embeddings MultiTalk, melhorando sincronização e prosódia: TencentGameMate/chinese-wav2vec2-base.
Dica: este gráfico InfiniteTalk é construído para GGUF. Mantenha os pesos MultiTalk do InfiniteTalk e a base WanVideo em GGUF para evitar incompatibilidades. Construções opcionais fp8/fp16 também estão disponíveis: Kijai/WanVideo_comfy_fp8_scaled e Kijai/WanVideo_comfy.
Como usar o fluxo de trabalho Comfyui InfiniteTalk#
O fluxo de trabalho executa da esquerda para a direita. Você fornece três coisas: uma imagem de retrato limpa, um arquivo de áudio de fala e um prompt curto para direcionar o estilo. O gráfico então extrai pistas de texto, imagem e áudio, funde-as em latentes de vídeo conscientes de movimento e renderiza um MP4 sincronizado.
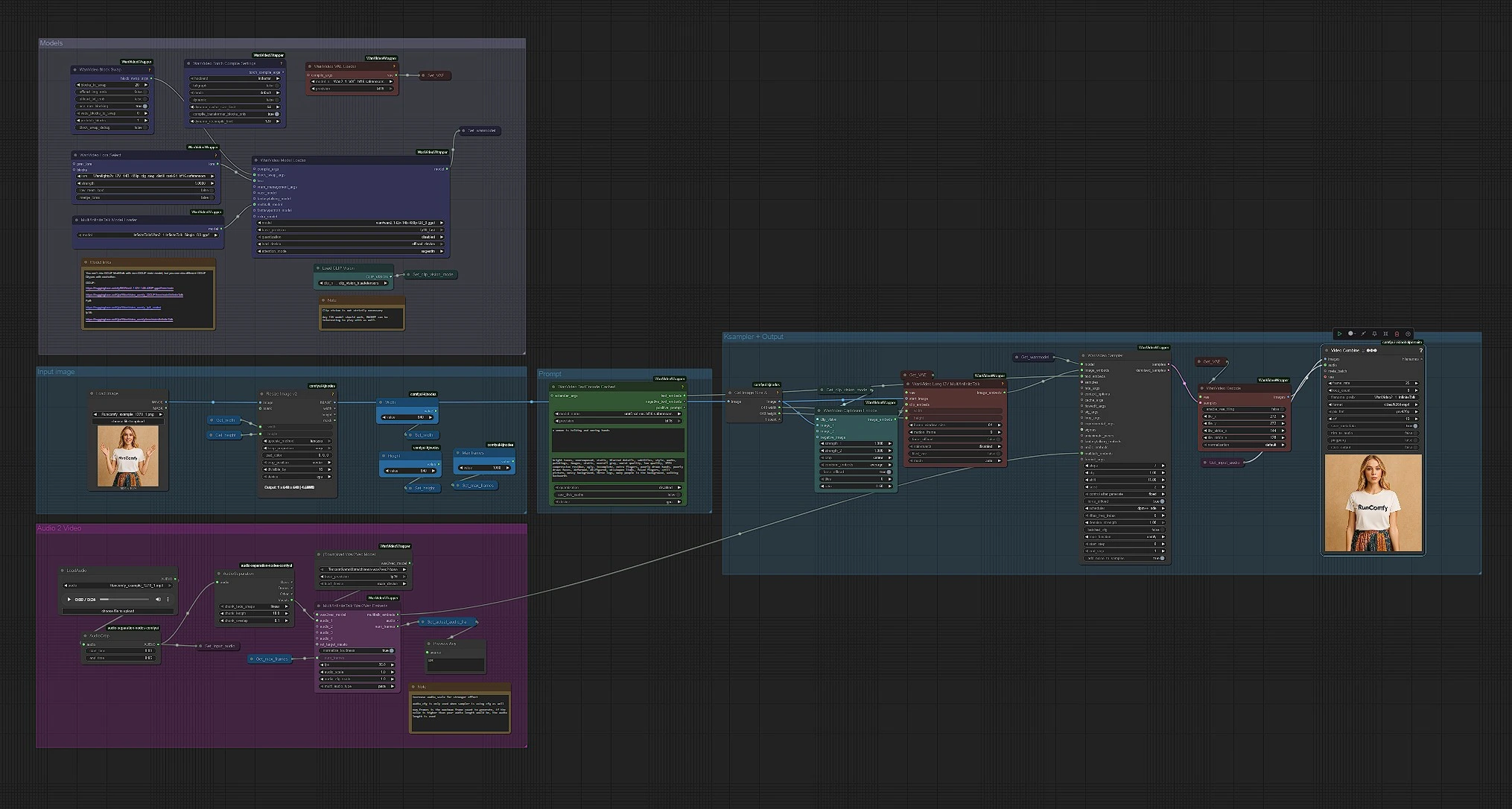
Modelos#
Este grupo carrega WanVideo, VAE, MultiTalk, CLIP Vision e o codificador de texto. WanVideoModelLoader (#122) seleciona a base Wan 2.1 I2V 14B GGUF, enquanto WanVideoVAELoader (#129) prepara o VAE correspondente. MultiTalkModelLoader (#120) carrega a variante InfiniteTalk que impulsiona o movimento orientado pela fala. Você pode opcionalmente anexar um Wan LoRA em WanVideoLoraSelect (#13) para influenciar aparência e movimento. Deixe estes intocados para uma primeira execução rápida; eles estão pré-configurados para um pipeline 480p que é amigável para a maioria das GPUs.
Prompt#
WanVideoTextEncodeCached (#241) pega seus prompts positivos e negativos e os codifica com UMT5. Use o prompt positivo para descrever o assunto e o tom da cena, não a identidade; a identidade vem da foto de referência. Mantenha o prompt negativo focado em artefatos que você deseja evitar (borrões, membros extras, fundos cinzas). Prompts em InfiniteTalk moldam principalmente iluminação e energia de movimento enquanto o rosto permanece consistente.
Imagem de entrada#
CLIPVisionLoader (#238) e WanVideoClipVisionEncode (#237) incorporam seu retrato. Use uma foto nítida, de frente, de cabeça e ombros com luz uniforme. Se necessário, corte suavemente para que o rosto tenha espaço para se mover; cortes pesados podem desestabilizar o movimento. Os embeddings da imagem são passados adiante para preservar detalhes de identidade e vestuário à medida que o vídeo é animado.
Áudio para MultiTalk#
Carregue sua fala em LoadAudio (#125); corte-a com AudioCrop (#159) para pré-visualizações rápidas. DownloadAndLoadWav2VecModel (#137) busca Wav2Vec2, e MultiTalkWav2VecEmbeds (#194) transforma o clipe em recursos de movimento conscientes de fonemas. Cortes curtos de 4–8 segundos são ótimos para iteração; você pode executar takes mais longos uma vez que goste da aparência. Faixas de voz limpa e seca funcionam melhor; música de fundo forte pode confundir a sincronização labial.
Imagem para vídeo, amostragem e saída#
WanVideoImageToVideoMultiTalk (#192) funde sua imagem, incorporações CLIP Vision e MultiTalk em incorporações de imagem quadro a quadro dimensionadas pelas constantes Width e Height. WanVideoSampler (#128) gera os quadros latentes usando o modelo WanVideo de Get_wanmodel e seus embeds de texto. WanVideoDecode (#130) converte latentes para quadros RGB. Finalmente, VHS_VideoCombine (#131) mistura quadros e áudio em um MP4 a 25 fps com uma configuração de qualidade equilibrada, produzindo o clipe InfiniteTalk final.
Nós principais no fluxo de trabalho Comfyui InfiniteTalk#
WanVideoImageToVideoMultiTalk (#192)#
Este nó é o coração do InfiniteTalk: ele condiciona a animação da cabeça falante mesclando a imagem inicial, recursos CLIP Vision e orientação MultiTalk na sua resolução alvo. Ajuste width e height para definir aspecto; 832×480 é um bom padrão para velocidade e estabilidade. Use-o como o principal local para alinhar identidade com movimento antes da amostragem.
MultiTalkWav2VecEmbeds (#194)#
Converte recursos Wav2Vec2 em embeddings de movimento MultiTalk. Se o movimento labial for muito sutil, aumente sua influência (escalonamento de áudio) nesta etapa; se for exagerado, diminua a influência. Certifique-se de que o áudio seja dominante em fala para timing de fonema confiável.
WanVideoSampler (#128)#
Gera os latentes de vídeo dados as incorporações de imagem, texto e MultiTalk. Para primeiras execuções, mantenha o agendador e os passos padrão. Se você notar cintilação, aumentar o total de passos ou habilitar CFG pode ajudar; se o movimento parecer muito rígido, reduza CFG ou a força do amostrador.
WanVideoTextEncodeCached (#241)#
Codifica prompts positivos e negativos com UMT5-XXL. Use linguagem concisa e concreta como "luz de estúdio, pele suave, cor natural" e mantenha os prompts negativos focados. Lembre-se de que prompts refinam enquadramento e estilo, enquanto a sincronização labial vem do MultiTalk.
Extras opcionais#
- Mantenha MultiTalk e WanVideo na mesma família de implantação (todos GGUF ou todos não-GGUF) para evitar incompatibilidades.
- Itere com um corte de áudio de 5–8 segundos e o tamanho padrão de 480p; aumente a escala posteriormente, se necessário.
- Se a identidade oscilar, experimente uma foto de origem mais limpa ou um LoRA mais suave. LoRAs fortes podem sobrepor a semelhança.
- Grave a fala em um quarto silencioso e normalize os níveis; o InfiniteTalk rastreia fonemas melhor com voz clara e seca.
Agradecimentos#
O fluxo de trabalho InfiniteTalk representa um grande avanço na geração de vídeo impulsionada por IA ao combinar o sistema de nós flexível do ComfyUI com o modelo de IA MultiTalk. Esta implementação foi possível graças à pesquisa original e lançamento da MeiGen-AI, cujo projeto MultiTalk impulsiona a sincronização natural de fala do InfiniteTalk. Agradecimentos especiais também vão para a equipe do projeto InfiniteTalk por fornecer a referência de origem, e para a comunidade de desenvolvedores do ComfyUI por permitir a integração perfeita do fluxo de trabalho.
Além disso, o crédito vai para Kijai, que implementou o InfiniteTalk no nó Wan Video Sampler, tornando mais fácil para os criadores produzirem retratos falantes e cantantes de alta qualidade diretamente no ComfyUI. O link do recurso original para InfiniteTalk está disponível aqui: InfiniteTalk Example Workflow.
Juntas, essas contribuições tornam possível para criadores transformarem retratos simples em avatares falantes contínuos e realistas, desbloqueando novas oportunidades para narrativas, dublagens e conteúdo de performance impulsionados por IA.