
ACE-Step 1.5XL Turbo Texto para Música ComfyUI Workflow#
Transforme sugestões compactas em música MP3 polida com este workflow comfyui focado em velocidade e repetibilidade. Ele combina o gerador ACE-Step 1.5XL Turbo com seu VAE oficial e codificadores de texto duplos Qwen, exportando diretamente para MP3 para fácil pré-visualização e reutilização. Produtores, designers de som e artistas de sugestões podem iterar rapidamente enquanto mantêm os resultados consistentes entre as execuções.
Modelos principais neste workflow comfyui#
- ACE-Step 1.5XL Turbo (bf16). O modelo de difusão central que sintetiza música a partir de condicionamento de texto, otimizado para denoising rápido e latentes de áudio de alta qualidade. Model file
- ACE-Step 1.5 VAE. O decodificador que transforma latentes de áudio em uma forma de onda final enquanto preserva o timbre e a dinâmica esperados pela família ACE-Step. Model file
- Qwen 0.6B ACE 1.5 text encoder. Codificador leve que converte sua sugestão descritiva em vetores de condicionamento usados pelo gerador. Model file
- Qwen 4B ACE 1.5 text encoder. Codificador companheiro maior que enriquece semântica, dicas de estilo, instrumentos e sugestões vocais para renderizações mais fiéis. Model file
Como usar este workflow comfyui#
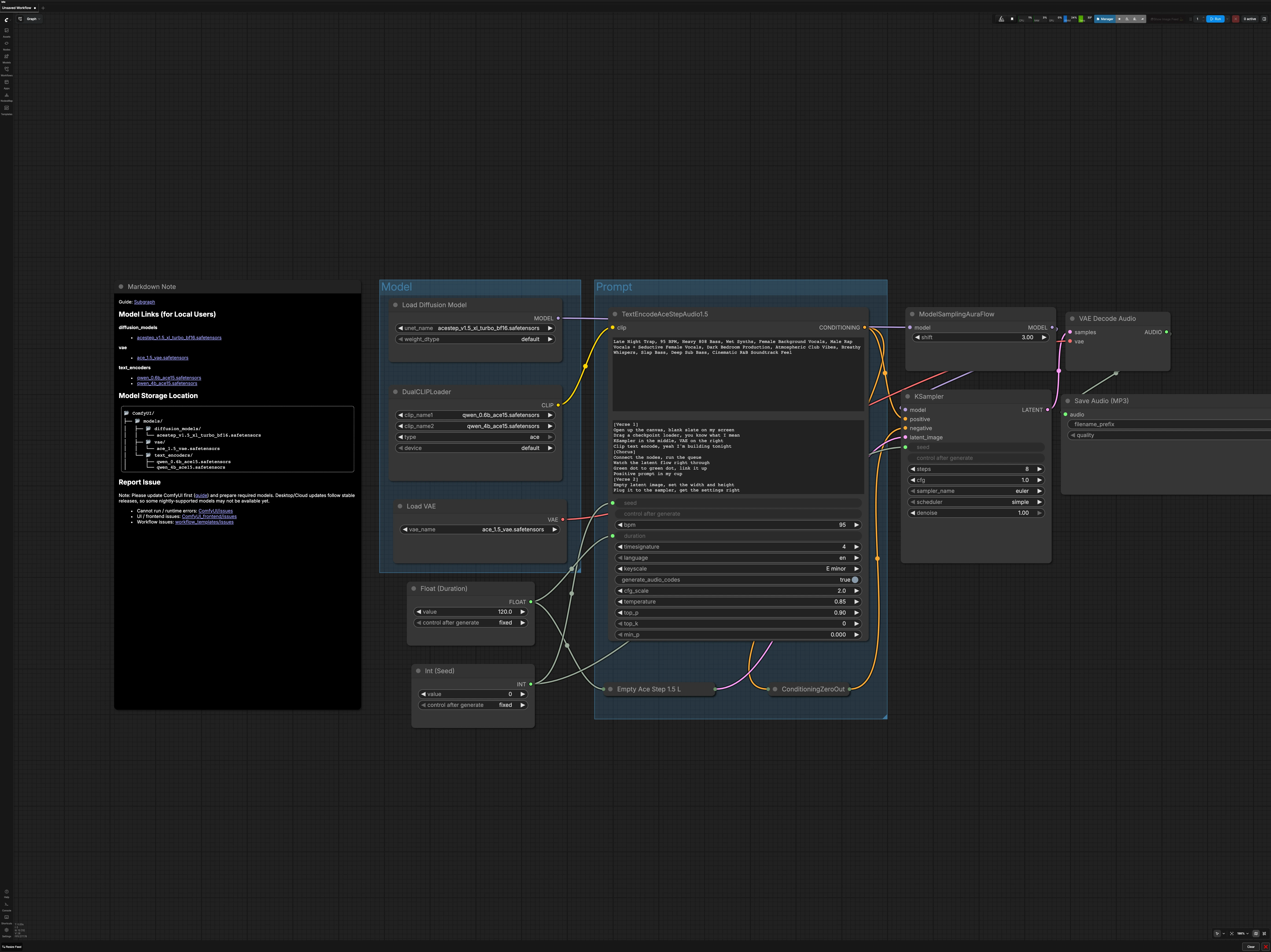
O gráfico está organizado em dois grupos principais mais controles globais. Você carrega a pilha de modelos ACE-Step, descreve a música que deseja, define a duração da música e a seed, depois amostra, decodifica e exporta para MP3.
Grupo de modelos#
Esta seção inicializa a pilha de modelos que o gerador espera. UNETLoader (#104) carrega o ACE-Step 1.5XL Turbo, e VAELoader (#106) traz o ACE-Step 1.5 VAE correspondente para que a decodificação permaneça fiel. DualCLIPLoader (#105) combina os codificadores de texto Qwen 0.6B e 4B para preparar embeddings de sugestões. O UNet é roteado através de ModelSamplingAuraFlow (#78), que aplica a configuração do sampler necessária pelo modelo antes de começar o denoising.
Grupo de sugestões#
Escreva uma descrição concisa de gênero, humor, instrumentos, vocais, tempo e estilo de produção em TextEncodeAceStepAudio1.5 (#94). Se você usar letras ou notas estruturais, forneça-as na caixa de texto secundária para que os codificadores possam condicionar a fraseologia e a dinâmica. O condicionamento negativo é intencionalmente desativado via ConditioningZeroOut (#47) para manter os resultados focados e simplificar as iterações iniciais. O nó também aceita a duração global e a seed, garantindo que o condicionamento permaneça alinhado com o comprimento da faixa e suas configurações de reprodutibilidade.
Duração e seed#
Defina o comprimento da faixa em segundos usando Float (Duration) (#99). Escolha uma seed em Int (Seed) (#109) para tornar as execuções reproduzíveis tanto no codificador quanto no sampler. Manter a mesma seed enquanto altera apenas a sugestão é uma maneira confiável de testar direções criativas A/B. Para uma exploração ampla, varie a seed após estar satisfeito com a sugestão.
Configuração de áudio latente#
EmptyAceStep1.5LatentAudio (#98) constrói um áudio latente vazio que corresponde à duração escolhida. Isso atua como a tela que o sampler preencherá durante o denoising. Durações mais longas requerem mais computação, então considere começar mais curto para validar uma sugestão antes de escalar. O workflow conecta a duração globalmente para que seu latente e condicionamento estejam sempre em sincronia.
Denoising e amostragem#
KSampler (#3) realiza o processo de difusão usando o modelo ACE-Step 1.5XL Turbo e seu condicionamento de sugestão. O caminho do sampler é executado através de ModelSamplingAuraFlow (#78) para corresponder às configurações do scheduler esperadas pelo modelo para uma convergência estável e rápida. Use a mesma seed para comparar alterações de palavras ou estilo, e ajuste as configurações do sampler apenas quando sua sugestão estiver ajustada. Quando o sampler terminar, você terá um áudio latente pronto para decodificação.
Decodificar e exportar#
VAEDecodeAudio (#18) converte o latente em uma forma de onda com o ACE-Step 1.5 VAE para preservar o timbre pretendido. SaveAudioMP3 (#107) grava um MP3 com um nome de arquivo base e uma tag de versão opcional para que você possa manter as tomadas organizadas. MP3 é ideal para revisão rápida e compartilhamento, e você sempre pode re-renderizar ou re-exportar para um formato diferente mais tarde. O resultado aparece em seu local padrão de saída ComfyUI.
Nós principais neste workflow comfyui#
TextEncodeAceStepAudio1.5 (#94)#
Este nó traduz sua descrição musical e letras opcionais em condicionamento para o gerador usando os codificadores Qwen emparelhados. Mantenha as sugestões específicas sobre gênero, instrumentação, presença vocal, tempo, humor e caráter de mixagem. Certifique-se de que a duração do nó corresponde ao comprimento global da música para que a estrutura e a fraseologia estejam alinhadas. Use uma seed fixa enquanto itera nas palavras para entender como os termos influenciam o arranjo e o timbre.
EmptyAceStep1.5LatentAudio (#98)#
Controla a tela de tempo que o modelo preencherá. Aumentar a duração aumenta a memória e o tempo de renderização, então itere em rascunhos mais curtos antes de se comprometer com peças mais longas. Mantenha as alterações de duração deliberadas porque elas podem alterar o tempo percebido e o ritmo das seções mesmo com a mesma sugestão e seed.
KSampler (#3)#
Conduz a qualidade, velocidade e textura geral controlando como o ruído é removido do latente. Comece com o caminho do scheduler fornecido e ajuste as configurações do sampler apenas depois que a sugestão parecer certa. Para rascunhos rápidos, reduza o esforço de amostragem; para maior fidelidade, aumente gradualmente enquanto mantém a seed constante para tornar as diferenças fáceis de ouvir. Veja o comportamento do sampler principal no repositório ComfyUI para orientação geral. ComfyUI on GitHub
SaveAudioMP3 (#107)#
Lida com a exportação e nomeação de arquivos para que você possa catalogar as tomadas. Defina um nome base claro e uma tag de versão para rastrear iterações. Se você planeja masterizar ou editar mais, mantenha a seed do projeto e a sugestão em suas notas para que você possa re-renderizar com configurações de exportação alternativas quando necessário.
Extras opcionais#
- Escreva sugestões como frases curtas e ordenadas: gênero, humor, sensação chave, tempo, instrumentos, tipo vocal, estilo de produção.
- Mantenha as letras concisas e alinhadas à duração escolhida para evitar fraseologia apressada perto do final.
- Trave a seed enquanto refina a sugestão, depois varie a seed para explorar arranjos alternativos com o mesmo briefing.
- Comece com durações mais curtas para validar a direção, depois escale quando o som principal funcionar.
- O condicionamento negativo é desativado por design; habilite e ajuste uma sugestão negativa verdadeira apenas se precisar de exclusões estritas após a exploração inicial.
Agradecimentos#
Este workflow implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos sinceramente à Comfy.org pelo workflow Audio ACE Step 1.5 XL Turbo, e à Comfy-Org pelo modelo de difusão ACE-Step 1.5XL Turbo, ACE-Step 1.5 VAE, ACE-Step 1.5 text encoder 0.6B e ACE-Step 1.5 text encoder 4B por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Comfy.org/Audio ACE Step 1.5 XL Turbo workflow
- Docs / Release Notes: Workflow page
- Comfy-Org/ACE-Step 1.5XL Turbo diffusion model
- Hugging Face: acestep_v1.5_xl_turbo_bf16.safetensors
- Comfy-Org/ACE-Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/ACE-Step 1.5 text encoder 0.6B
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/ACE-Step 1.5 text encoder 4B
- Hugging Face: qwen_4b_ace15.safetensors
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.
