
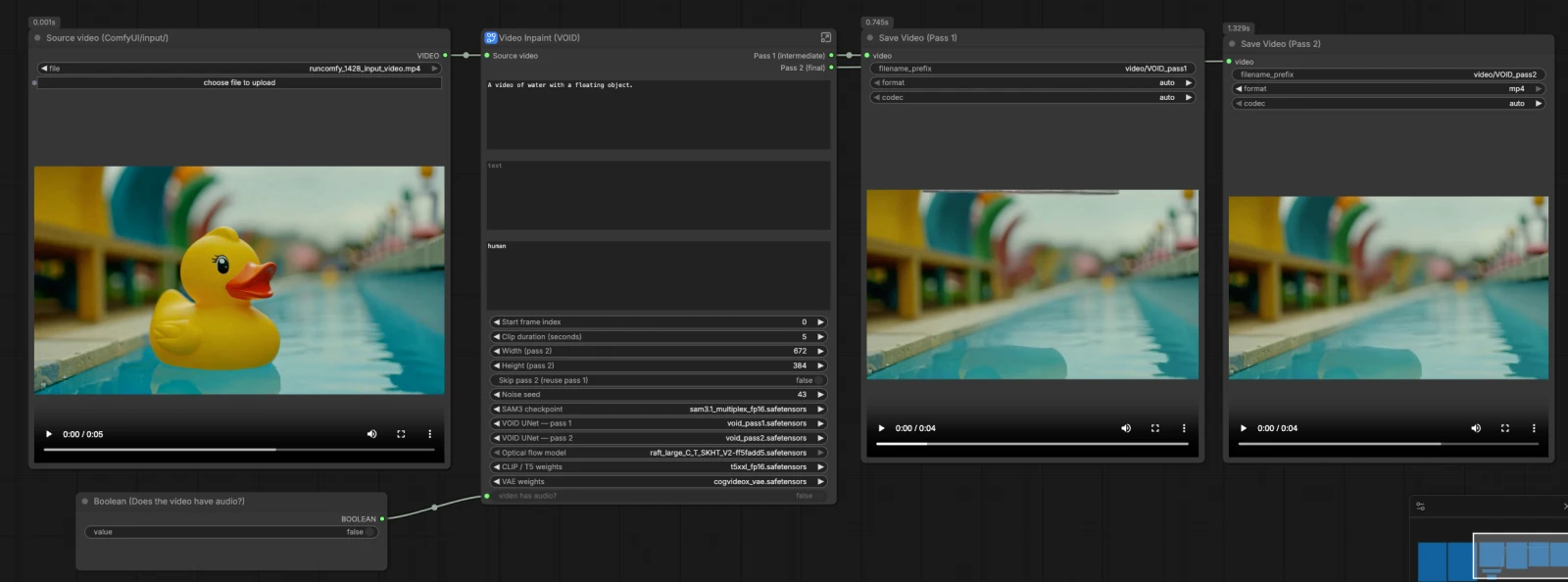
VOID Video Inpainting ComfyUI: 상호작용 인식 객체 제거로 깨끗하고 일관된 비디오#
이 VOID Video Inpainting ComfyUI 워크플로우는 클립에서 객체와 그 시각적 상호작용을 시간적 일관성으로 제거합니다. Meta의 SAM3 텍스트 기반 세분화를 사용하여 마스크를 정의하고 Netflix VOID의 이중 패스 비디오 인페인팅을 결합하여 시간이 지남에 따라 구멍을 채워 원치 않는 객체와 그 주변 효과가 없었던 것처럼 보이는 결과를 제공합니다.
창작자, 편집자 및 VFX 팀은 단일 프레임 정리가 깜빡이거나 움직임을 따라 깨질 때 VOID Video Inpainting ComfyUI에 의존할 수 있습니다. 워크플로우는 Pass 1을 빠른 중간 단계로, Pass 2를 더 강력한 시간적 안정성을 가진 정제된 결과로 출력합니다. 소스 비디오, 제거할 객체를 설명하는 짧은 SAM3 문구, 유지하고 싶은 장면을 설명하는 인페인트 프롬프트를 제공하세요.
ComfyUI VOID Video Inpainting ComfyUI 워크플로우의 주요 모델#
- VOID: Video Object and Interaction Deletion. 시간적 추론을 사용한 비디오 객체 제거를 위한 이중 확산; 참조 구현 및 체크포인트는 Netflix에서 제공합니다. GitHub 및 Hugging Face
- Segment Anything Model 3.1 Multiplex (SAM3.1). 객체 마스크 생성을 안내하는 텍스트 및 프롬프트 가능 이미지 세분화. Hugging Face
- RAFT: Recurrent All-Pairs Field Transforms. Pass 1의 노이즈를 Pass 2로 왜곡하여 프레임 간 움직임을 일관되게 유지하는 데 사용되는 광학 흐름. arXiv 및 VOID 모델 팩의 가중치 Hugging Face
- CogVideoX VAE. 인페인팅 중 비디오 프레임 인코딩 및 디코딩을 위한 잠재 코덱. Hugging Face
- T5-XXL 텍스트 인코더 (fp16). 확산 모델에 대한 조건화를 위해 긍정 및 부정 프롬프트를 변환하는 언어 백본. Hugging Face
ComfyUI VOID Video Inpainting ComfyUI 워크플로우 사용 방법#
이 VOID Video Inpainting ComfyUI 그래프는 명확한 경로를 따릅니다: 모델과 소스 클립을 로드하고, SAM3으로 객체 마스크를 만들고, 프롬프트와 마스크에서 공유 조건을 구축하고, Pass 1을 실행하여 콘텐츠를 설정한 다음, 안정적인 움직임을 위한 왜곡된 노이즈로 Pass 2를 실행합니다. 오디오는 처리된 세그먼트에 맞게 선택적으로 잘립니다. 워크플로우는 Pass 1과 Pass 2 비디오를 모두 저장하므로 비교하거나 빠르게 이동할 수 있습니다.
모델#
이 그룹은 VOID Video Inpainting ComfyUI에 필요한 모든 구성 요소를 로드합니다. CLIPLoader (#2)는 T5-XXL 텍스트 인코더를 가져오고, VAELoader (#3)는 CogVideoX VAE를 제공합니다. UNETLoader (#144)는 Pass 1을 위한 VOID UNet을 초기화하고 UNETLoader (#143)는 Pass 2를 위한 VOID UNet을 설정합니다. OpticalFlowLoader (#142)는 나중에 패스 간 노이즈 왜곡을 구동하는 RAFT 모델을 로드합니다.
입력 비디오 (ComfyUI/input/에 파일 배치)#
Source video (ComfyUI/input/) 로더를 클립에 지정한 다음 GetVideoComponents (#166)가 이를 프레임, 오디오 및 fps로 분할합니다. ImageFromBatch (#145)는 마스크를 미리보기 위한 대표 프레임을 선택합니다. GetImageSize (#43) 및 간단한 수학 노드는 일관된 슬라이싱을 위한 클립 길이와 인덱스를 계산합니다. 처리할 섹션만 타겟팅하기 위해 시작 프레임과 지속 시간을 제공하세요.
마스크 생성#
Image Segmentation (SAM3) 서브그래프는 VOID Video Inpainting ComfyUI를 위한 프레임별 객체 마스크를 생성합니다. SAM3_Detect (#75)는 선택한 프레임에서 객체를 세분화하기 위해 SAM3 텍스트 프롬프트를 사용하고 CLIPTextEncode (#78)는 문구를 인코딩합니다. 마스크는 MaskPreview (#132)에서 미리보기되므로 커버리지를 확인하고 필요한 경우 문구를 수정할 수 있습니다. "테이블 위의 빨간 컵" 또는 "파란 재킷을 입은 사람"과 같은 깨끗하고 구체적인 문구는 SAM3이 올바른 대상을 격리하는 데 도움이 됩니다.
공유: 텍스트 및 마스크 조건화#
Positive Prompt (CLIPTextEncode (#6))는 제거 후 장면이 어떻게 보여야 하는지 설명해야 하며, 제거 행위는 설명하지 마세요. Negative Prompt (CLIPTextEncode (#7))는 원하지 않는 아티팩트를 선택적으로 나열합니다. VOIDInpaintConditioning (#10)은 프롬프트, VAE, 들어오는 프레임, SAM3 마스크 및 목표 치수를 모두 결합하여 두 패스에서 사용되는 잠재 조건화 팩을 생성합니다. 이를 통해 VOID에 제거 후 유지할 것과 움직임 및 외관이 어떻게 느껴져야 하는지를 알려줍니다.
Pass 1: 샘플 (랜덤 노이즈 → DDIM)#
VOID Video Inpainting ComfyUI의 Pass 1은 표준 랜덤 노이즈를 사용하여 그럴듯한 채우기를 설정합니다. RandomNoise (#141)가 프로세스를 시드하고, BasicScheduler (#138) 및 VOIDSampler (#133)는 확산 일정을 정의하며, CFGGuider (#140)는 모델에 프롬프트를 혼합합니다. SamplerCustomAdvanced (#49)는 잠재 클립을 합성하고, VAEDecode (#45)는 이를 다시 프레임으로 변환합니다. CreateVideo (#46)는 선택적으로 오디오를 첨부하고 중간 Pass 1 비디오를 작성하여 정제 전에 검사할 수 있습니다.
Pass 2: 샘플 (왜곡된 노이즈 → DDIM)#
Pass 2는 새로운 무작위성 대신 Pass 1에서 왜곡된 노이즈로 초기화하여 시간적 안정성을 개선합니다. VOIDWarpedNoise (#31)는 RAFT 광학 흐름을 사용하여 Pass 1 프레임에서 시간에 맞춰 정렬된 노이즈를 생성한 다음 VOIDWarpedNoiseSource (#32)가 이를 샘플링에 공급합니다. CFGGuider (#136), BasicScheduler (#137), 및 VOIDSampler (#134)는 두 번째 샘플러를 설정하고, SamplerCustomAdvanced (#35)는 인페인팅된 콘텐츠를 정제합니다. VAEDecode (#36)는 최종 프레임을 생성합니다. 스킵을 토글하면 ComfySwitchNode (#150)가 Pass 1 프레임을 출력으로 직접 라우팅하여 빠른 미리보기를 제공합니다.
출력 비디오 크기#
너비 및 높이 컨트롤은 Pass 2 및 왜곡된 노이즈 생성기의 잠재 해상도를 구동합니다. 이러한 값은 VOID Video Inpainting ComfyUI에서 선명도, 안정성 및 컴퓨팅 부하에 영향을 미칩니다. 콘텐츠 목표 및 사용 가능한 메모리에 맞는 치수를 선택하세요. 동일한 크기가 파이프라인 전반에 걸쳐 일관되게 사용되어 움직임과 마스크가 정렬되도록 유지합니다.
Pass 2 건너뛰기#
빠른 확인이 필요할 때 스킵 컨트롤을 사용하여 VOID Video Inpainting ComfyUI가 Pass 1을 재사용하고 Pass 2를 실행하지 않습니다. ComfySwitchNode (#150)는 최종 출력에 대해 Pass 1과 Pass 2 이미지 중에서 자동으로 선택합니다. 이는 러프 컷이나 마스크 문구 또는 프롬프트를 조정할 때 유용합니다. 최종 렌더링을 위해 시간적 일관성을 잠그려면 Pass 2를 다시 켜세요.
오디오 트림#
클립에 오디오가 있는 경우 VOID Video Inpainting ComfyUI는 처리된 세그먼트에 맞게 오디오를 잘라 다시 첨부합니다. TrimAudioDuration (#158)은 사운드를 동기화 상태로 유지하고, ComfySwitchNode (#174)는 무음 클립을 안전하게 처리합니다. GetVideoComponents (#166)에서 가져온 fps는 드리프트를 피하기 위해 Pass 1 및 Pass 2 CreateVideo 노드를 모두 구동합니다. "비디오에 오디오가 있습니까?" 스위치를 올바르게 설정하여 예상 결과를 얻으세요.
ComfyUI VOID Video Inpainting ComfyUI 워크플로우의 주요 노드#
SAM3_Detect (#75)#
짧은 SAM3 문구에서 객체 마스크를 생성합니다. 마스크가 너무 느슨하거나 타이트한 경우 대상을 더 잘 설명하고 그 맥락을 설명하는 문구를 수정하세요. 필요한 경우 내부 세부 조정 컨트롤을 조정하여 가장자리를 선명하게 만드세요. 강력한 마스크는 후속 인페인팅을 더 안정적으로 만듭니다.
VOIDInpaintConditioning (#10)#
긍정 프롬프트, 부정 프롬프트, VAE, 프레임 및 SAM3 마스크에서 조건화 번들을 생성합니다. 긍정 프롬프트는 남아있는 장면을 설명해야 하며, "X 제거"와 같은 표현은 피하세요. 일관된 아티팩트가 나타날 때만 부정 프롬프트를 사용하세요. 결과적인 잠재 및 조건화 신호는 두 패스에 공급됩니다.
SamplerCustomAdvanced (#49) - Pass 1#
랜덤 노이즈로 첫 번째 패스에 대해 VOID 샘플링을 실행합니다. 노이즈 시드는 반복 가능성을 제어하며, 다른 채우기 패턴을 원할 때 변경하세요. 샘플러와 스케줄러를 Pass 1 UNet과 짝지어 유지하세요. 정제 전에 구성 및 기본 움직임을 검증하려면 이 패스를 검사하세요.
VOIDWarpedNoise (#31)#
Pass 1 프레임에서 계산된 RAFT 광학 흐름을 사용하여 시간에 맞춰 정렬된 노이즈를 생성합니다. 이는 Pass 2로의 움직임 단서를 보존하고 깜빡임을 줄입니다. 움직임이 불안정해 보이면 마스크 품질을 다시 확인하거나 Pass 1에서 다른 시드를 시도하여 더 나은 왜곡 기반을 생성하세요.
SamplerCustomAdvanced (#35) - Pass 2#
왜곡된 노이즈에서 시작하여 인페인팅된 영역을 정제합니다. 이를 사용하여 텍스처를 고정하고 시간에 걸쳐 세부 사항을 안정화하세요. 이미 안정적인 출력일 경우 Pass 2를 건너 시간 절약이 가능합니다; 그렇지 않으면 최종 배송을 위해 활성화 상태로 유지하세요.
ComfySwitchNode (#150) - 스킵 컨트롤#
최종 출력에 대해 Pass 1과 Pass 2 프레임을 전환합니다. 이를 사용하여 품질을 A/B 검사하거나 SAM3 마스크 및 프롬프트를 조정하는 동안 반복 속도를 높이세요. 최종 VOID Video Inpainting ComfyUI 결과를 위해 비활성화하세요.
선택적 추가 기능#
- 제거 후 보고 싶은 세계에 대한 긍정 프롬프트를 작성하세요. 예를 들어 "빈 주방 카운터, 낮, 깨끗한 타일" 대신 "머그컵 제거"라고 하지 마세요.
- SAM3 문구를 구체적으로 유지하고, "파란 재킷을 입은 사람" 또는 "테이블 위의 빨간 컵"과 같이 구체적으로 작성한 후 작은 수정 후에 마스크 미리보기에서 커버리지를 확인하세요.
- 시작 프레임과 지속 시간을 사용하여 관련 섹션으로 처리를 제한하세요; 긴 클립은 세그먼트로 처리하는 것이 가장 좋습니다.
- 초안에서는 Pass 2를 건너뛰고, VOID Video Inpainting ComfyUI에서 최종 안정화를 위해 활성화하세요.
- 너비와 높이를 조정하여 GPU 메모리에 따라 세부 사항을 균형 있게 조정하세요; 해상도가 높을수록 선명하게 보이지만 더 많은 컴퓨팅 비용이 듭니다.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 Netflix의 VOID 모델, Comfy-Org의 VOID 및 SAM3.1 모델 파일, RunComfy의 Cloud Save 워크플로우 소스에 대한 기여 및 유지보수에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- Netflix/void-model
- GitHub: netflix/void-model
- Comfy-Org/void-model
- Hugging Face: Comfy-Org/void-model
- Comfy-Org/sam3.1
- Hugging Face: Comfy-Org/sam3.1
- RunComfy/Cloud Save source
- Docs / Release Notes: Cloud Save source
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지보수자가 제공한 라이선스 및 조건에 따릅니다.
