





ComfyUI용 Qwen Image Edit 2511: 지시 기반 단일 이미지 편집 및 다중 이미지 참조#
이 워크플로우는 Qwen Image Edit 2511을 ComfyUI에 도입하여 원본 이미지의 구조와 정체성을 유지하면서 정밀한 지시 기반 편집을 제공합니다. 단일 이미지 편집과 다중 이미지 참조 사용 사례를 지원하며 스타일 전환, 재료 또는 객체 교체, 속성 변경 및 자연스럽고 일관된 결과로 깨끗한 시각적 향상을 가능하게 합니다.
비전-언어 인코더와 확산 변환기를 기반으로 하여, 그래프는 평범한 영어 지시를 일관된 이미지 편집으로 변환합니다. 선택적인 Lightning LoRA는 Qwen Image Edit 2511 생성 속도를 빠르게 하여 정렬을 희생하지 않으므로, 아티스트와 제품 팀이 창의적 이미지 편집, 캐릭터 재스타일링 및 전문 콘텐츠 개선을 빠르게 반복할 수 있습니다.
더 간단하고 노드 없는 경험을 원하십니까? Qwen Image Edit 2511 Playground를 탐색하여 ComfyUI 노드를 사용하지 않고 이미지를 업로드하고 텍스트 지시로 편집해 보세요.
ComfyUI Qwen Image Edit 2511 워크플로우의 주요 모델#
- Qwen-Image-Edit-2511. 2509보다 개선된 일관성을 제공하는 코어 확산 변환기로, 지시를 따르면서 정체성과 기하학적 안정성을 유지하도록 설계되었습니다. Hugging Face: Qwen/Qwen-Image-Edit-2511
- Qwen2.5-VL-7B-Instruct. 텍스트/이미지 이해의 백본으로 사용되는 비전-언어 인코더로, 지시를 시각적 문맥과 정렬하여 지시 기반 편집을 지원합니다. Hugging Face: Qwen/Qwen2.5-VL-7B-Instruct
- Qwen Image VAE. 픽셀 공간과 모델의 잠재 공간 간의 충실한 재구성을 위한 매칭 변분 오토인코더입니다. (파일은 Comfy-Org 패키지를 통해 제공됩니다.) Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- Qwen-Image-Edit-2511-Lightning (선택 사항). 샘플러 속도를 크게 높이면서 편집을 유지하는 4단계 가속 LoRA입니다; 빠른 미리보기나 실시간 단일 이미지 편집이 필요할 때 활성화하십시오. Hugging Face: lightx2v/Qwen-Image-Edit-2511-Lightning
ComfyUI Qwen Image Edit 2511 워크플로우 사용 방법#
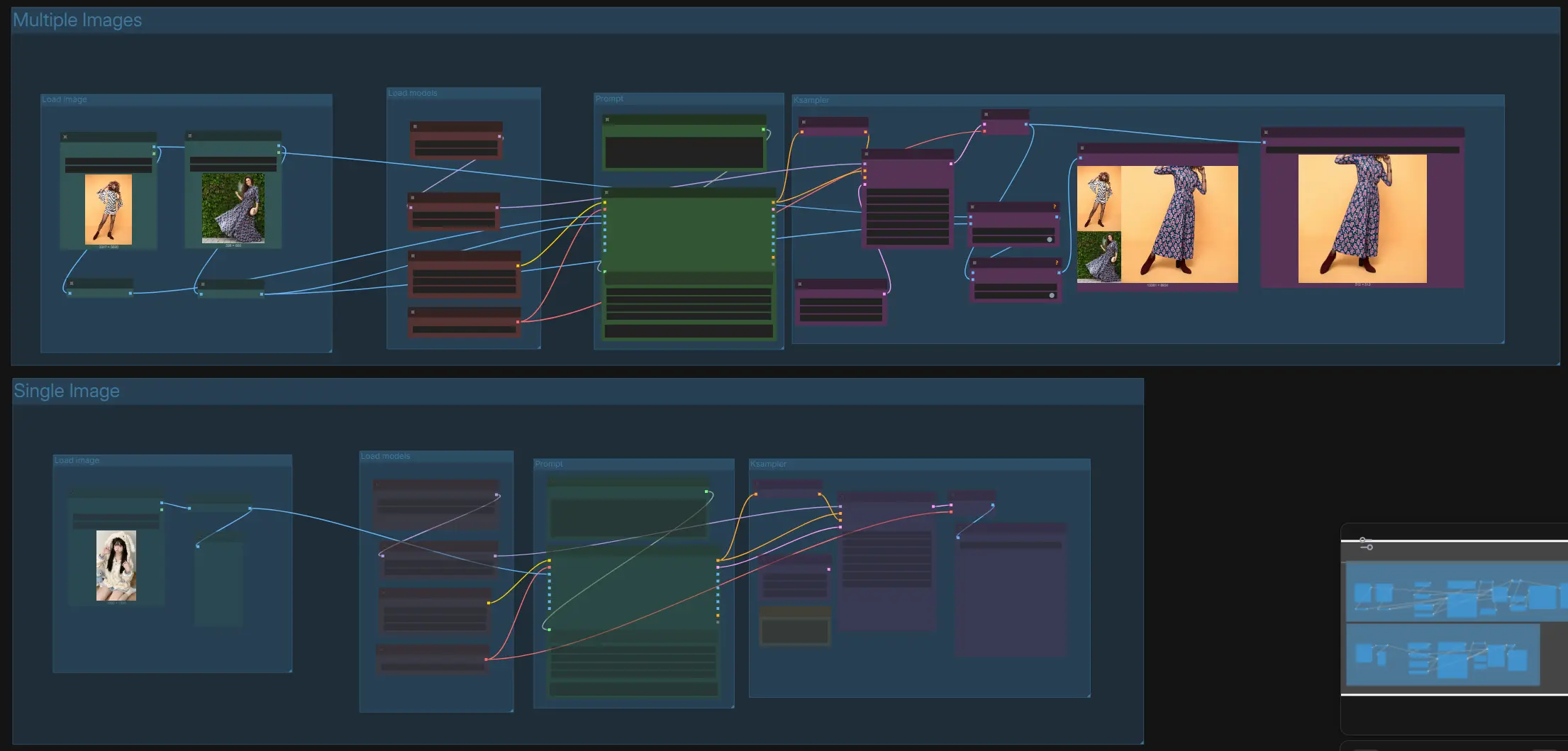
이 그래프는 두 개의 병렬 트랙을 포함합니다: "다중 이미지"는 교차 이미지 속성/재료 전환을 위한 것이고, "단일 이미지"는 직접적인 지시 기반 편집을 위한 것입니다. 두 트랙 모두 동일한 모델 로더와 샘플러 논리를 공유하며, 둘 다 미리보기와 저장 노드로 끝납니다. 작업에 맞는 트랙을 선택하고 명확한 지시를 작성한 후 실행을 대기열에 추가하십시오.
다중 이미지 › 이미지 로드#
이 그룹을 사용하여 두 개의 참조 이미지를 로드합니다: 첫 번째는 편집할 기본 이미지이고, 두 번째는 전환할 외관, 재료, 또는 속성을 제공합니다. 이미지는 확산 중 아티팩트를 피하고 레이아웃을 유지하기 위해 균형 잡힌 작업 크기로 자동 조정됩니다. 가능하면 유사한 구도나 시점을 가진 참조를 선택하여 정렬을 개선하세요. 이 경로는 "왼쪽 이미지의 의자 재료를 오른쪽 이미지의 재료로 교체"와 같은 작업을 지원하며, 모양과 구조를 유지합니다.
다중 이미지 › 프롬프트#
편집 목표를 설명하고 두 번째 이미지가 첫 번째 이미지에 어떻게 영향을 미쳐야 하는지를 설명하는 짧고 명확한 지시를 작성하세요. 예: "Figure 1의 의자 재료를 Figure 2의 가죽으로 교체하고, 프레임은 변경하지 않으며, 조명을 맞추세요." 이 지시는 Qwen2.5-VL 인코더에 전달되어 로드된 비주얼에 텍스트를 기반으로 한 신뢰할 수 있는 이미지 편집을 제공합니다. 상충되는 목표를 피하고, 변경되지 말아야 할 부분을 명시하여 정체성 안전한 결과를 보장하세요.
다중 이미지 › 모델 로드#
이 그룹은 Qwen Image Edit 2511 확산 모델, Qwen2.5-VL 인코더, 그리고 Qwen Image VAE를 로드합니다. 편집 속도를 높이면서 지시 준수를 유지하기 위해 Lightning LoRA를 선택적으로 활성화할 수 있습니다. 템플릿에서 제공하는 모델 선택을 그대로 두고, 변형을 교체할 이유가 있는 경우에만 변경하세요.
다중 이미지 › KSampler 및 출력#
샘플러는 지시의 긍정적 조건을 사용하여 요청된 편집을 실현하며, 의도치 않은 변경을 줄이기 위해 0으로 설정된 부정적 조건을 사용합니다. 결과는 VAE에 의해 디코딩되고 참조와 자동으로 병합되어 나란히 미리보기를 제공하여 단일 이미지 편집이 지시를 따랐는지 쉽게 확인할 수 있게 합니다. 필요에 따라 합성된 이미지를 저장하거나 편집된 이미지만 저장하세요.
단일 이미지 › 이미지 로드#
편집할 하나의 소스 이미지를 드롭하세요. 스케일링 단계가 대상 작업 크기에 맞게 준비하여 구성의 안정성과 작은 세부 사항의 선명함을 유지합니다. 스타일이나 재료 기부자 이미지가 필요하지 않을 때 지시 기반 편집을 위한 가장 깨끗한 경로입니다.
단일 이미지 › 프롬프트#
대상과 정확한 변경 사항을 명시하는 직접적인 지시를 작성하세요. 좋은 패턴에는 "X 유지, Y 변경", "Z 향상", 또는 "동일한 구성으로 [스타일]로 재스타일링"이 포함됩니다. 지시는 인코더에 의해 시각적 문맥과 융합되어 확산 모델이 정체성과 기하학을 유지하면서 정확한 단일 이미지 편집을 적용할 수 있게 합니다.
단일 이미지 › 모델 로드#
모델 로더는 Qwen Image Edit 2511, Qwen2.5-VL, 그리고 VAE를 초기화합니다. 더 빠른 미리보기와 빠른 반복을 위해 Lightning LoRA를 선택적으로 활성화하세요. LoRA를 비활성화하면 기본 모델이 최대 충실도와 일관성을 우선시합니다.
단일 이미지 › KSampler 및 출력#
샘플러는 인코더에서 파생된 조건으로 당신의 편집을 실행하고, 그런 다음 이미지를 디코딩합니다. 편집이 지시를 만족했는지, 원래의 모습에서 벗어나지 않았는지 평가하기 위해 미리보기를 사용하세요. 만족할 때 최종 이미지를 저장하세요.
ComfyUI Qwen Image Edit 2511 워크플로우의 주요 노드#
TextEncodeQwenImageEditPlusAdvance_lrzjason (#13, #64)
- 역할: 지시와 하나 이상의 참조 이미지를 Qwen Image Edit 2511을 안내하는 조건으로 패킹합니다. 다중 이미지 작업의 경우, 지시에서 첫 번째 및 두 번째 이미지를 명시적으로 참조하여 전환할 대상을 제어하세요. 과도한 편집이 발생하면 지시를 더 제한적으로 만들고(예: "자세나 조명을 변경하지 마세요") 이미지의 실제 객체에 설명을 고정하세요.
KSampler (#48, #72)
- 역할: 조건을 최종 편집으로 전환하는 확산 과정을 주도합니다. Lightning LoRA를 활성화하면 속도를 위해 매우 적은 단계와 낮은 가이던스를 사용하세요; 비활성화하면 최대 충실도를 위해 단계를 늘리세요. 결과가 드리프트하면 가이던스를 낮추고, 변화가 너무 미묘하면 가이던스나 단계를 조금 더 추가하세요.
LoraLoaderModelOnly (#49, #68)
- 역할: 4단계 가속을 위한 Qwen-Image-Edit-2511-Lightning LoRA를 주입합니다. 충실한 결과를 위해 기본값 주변의 무게를 유지하고, 기본 모델의 품질과 비교하거나 까다로운 편집을 다듬고 싶을 때는 비활성화하세요.
FluxKontextImageScale (#5, #6, #62)
- 역할: 인코더와 샘플러가 일관된 공간적 문맥을 보도록 입력을 안정적인 작업 크기로 조정합니다. 대부분의 경우에 켜두세요; 원본 해상도를 정확히 유지해야 하는 경우, 먼저 여기서 조정한 다음 샘플러로 다듬으세요.
선택적 추가 항목#
- 주제와 범위를 명시하는 지시를 작성하세요: "재킷 색상을 네이비로 변경하고, 직물 질감과 조명을 유지"는 모호한 스타일 프롬프트보다 더 신뢰할 수 있는 이미지 편집을 제공합니다.
- 다중 이미지 전환의 경우, 기본 이미지와 유사한 시점과 조명을 가진 기부자를 선택하세요; 이는 재료와 스타일 매칭을 개선합니다.
- 빠른 미리보기를 위해 Lightning을 활성화할 때, 절대적인 최고 충실도가 필요하면 표준 실행으로 최종 결과를 확인하세요.
- 편집이 프레임의 너무 많은 부분에 영향을 미치면 "배경을 변경하지 않음" 또는 "얼굴 특징을 유지"와 같은 제약을 추가하여 단일 이미지 편집 동작을 조여주세요.
참조
- Qwen-Image-Edit-2511 모델 카드: Hugging Face
- Qwen2.5-VL-7B-Instruct: Hugging Face
- Qwen Image VAE 및 ComfyUI용 패키지 파일: Hugging Face
- Qwen-Image-Edit-2511-Lightning LoRA: Hugging Face
- Qwen-Image 기술 보고서: arXiv
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 Qwen-Image-Edit-2511 모델에 대한 Qwen의 기여와 유지 관리에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Qwen/Qwen-Image-Edit-2511
- GitHub: QwenLM/Qwen-Image
- Hugging Face: Qwen/Qwen-Image-Edit-2511
- arXiv: 2508.02324
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 작성자와 유지 관리자가 제공하는 라이선스 및 조건에 따릅니다.

