
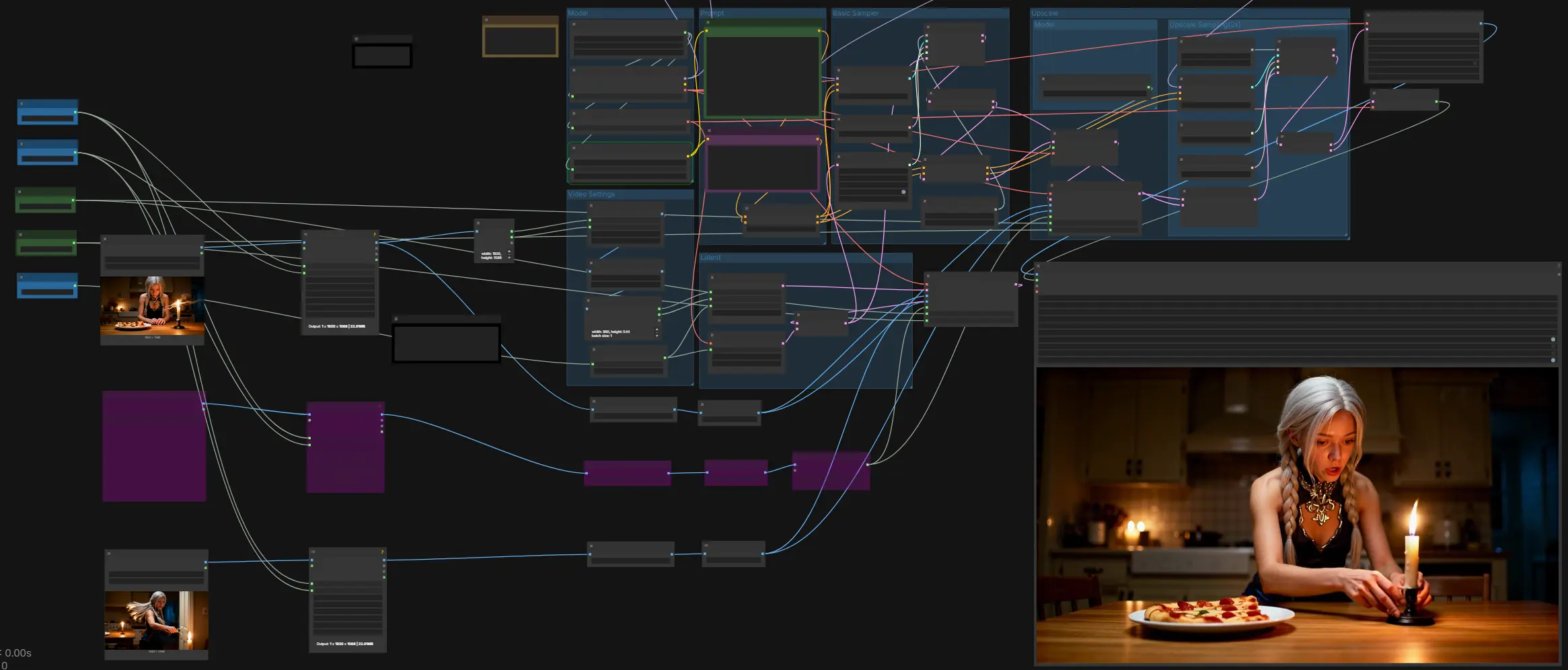
LTX-2 First Last Frame: 시작에서 종료까지 제어된, 오디오 동기화 비디오 생성 in ComfyUI#
LTX-2 First Last Frame은 ComfyUI에서 시작 프레임과 종료 프레임 간의 정밀하고 영화적인 모션을 원하는 크리에이터를 위한 워크플로우로, 하나의 패스로 동기화된 오디오와 비주얼을 생성합니다. 이미지(선택적으로 가이드 중간 프레임 포함)를 조건으로 하여, 파이프라인은 샷 전반의 정체성, 프레이밍 및 조명을 보존한 다음 모션을 조정하여 마지막 프레임에 정확히 도달하도록 합니다. 내러티브 비트, 타이틀 또는 씬 전환, 카메라 이동, 그리고 시간적 연속성과 오디오 정렬이 중요한 모든 순간을 위해 설계되었습니다.
LTX-2 실시간 모델에 의해 구동되는 워크플로우는 프롬프트, LoRAs를 통한 카메라 동작 및 첫/마지막 프레임 강도에 대한 세밀한 제어를 제공하면서 빠른 반복을 유지합니다. 결과는 첫 프레임에서 마지막 프레임까지의 지시를 따르는 부드럽고 일관된 시퀀스로, 타이밍, 외형 및 사운드를 포함합니다.
참고: 2x Large 이하의 머신 타입에서는 "ltx-2-19b-dev-fp8.safetensors" 모델을 사용하시기 바랍니다!
Comfyui LTX-2 First Last Frame 워크플로우의 주요 모델#
- LTX-2 19B (dev). 텍스트 및 프레임 컨트롤에서 조인트 오디오-비디오 잠재를 생성하는 핵심 비디오 생성 모델; 실시간 반복 및 카메라 인식 LoRAs를 지원합니다. 공식 리포지토리 및 가중치 참조: Lightricks/LTX-2 on GitHub 및 Lightricks/LTX-2 on Hugging Face.
- Gemma 3 12B Instruct 텍스트 인코더 for LTX-2. 이 파이프라인에서 비주얼 및 오디오 프롬프트를 위한 견고한, 인스트럭션 튜닝된 언어 이해를 제공합니다; ComfyUI에 LTX 호환 텍스트 인코더로 패키지화되었습니다. 가중치 참조: Comfy-Org/ltx-2 split text encoders.
- LTXV Audio VAE (24 kHz vocoder). 사운드트랙이 비디오와 함께 생성되고 화면상의 액션과 동기화되도록 오디오 잠재를 인코딩하고 디코딩합니다. 모델 패밀리 컨텍스트 보기: Lightricks/LTX-2.
- LTX-2 Spatial Upscaler x2. 기본 패스 후 더 깨끗한 고해상도 결과를 위해 사용되는 잠재 업스케일러로, 업스케일 샘플링 단계에서 사용됩니다. 가중치는 Lightricks/LTX-2에서 제공됩니다.
- LTX-2 LoRA pack for 카메라 컨트롤 및 디테일. 카메라 모션 및 세부 사항을 형성하는 Dolly In/Out/Left/Right, Jib Up/Down, Static 및 이미지 조건화 디테일러와 같은 선택적 LoRAs. 공식 컬렉션 탐색: Lightricks LTX-2 LoRAs.
Comfyui LTX-2 First Last Frame 워크플로우 사용 방법#
이 워크플로우는 입력 및 프롬프트에서 기본 오디오-비디오 샘플로 이동한 후, 오디오와 함께 MP4로 디코딩 및 멀티플렉싱하기 전에 2x 업스케일 패스를 수행합니다. 기본 및 업스케일 단계 모두에서 첫/마지막 프레임 컨트롤을 사용하며, 궤도를 안정화하기 위해 중간 프레임을 선택적으로 사용할 수 있습니다.
모델#
모델 그룹은 LTX-2 체크포인트, Gemma 3 12B Instruct 텍스트 인코더 및 LTXV Audio VAE를 로드합니다. ckpt_name 패널을 사용하여 GPU에 따라 표준 및 FP8 버전 중 선택할 수 있습니다. 텍스트 인코더는 LTXAVTextEncoderLoader에 의해 제공되며 긍정적 및 부정적 프롬프트에 모두 피드됩니다. 오디오 VAE는 조인트 오디오-비디오 생성을 가능하게 하여 프롬프트에 설명된 대화, 효과 또는 분위기가 비주얼과 함께 나타나게 합니다.
프롬프트#
긍정적 프롬프트에 장면을 작성하고 부정적 프롬프트에 바람직하지 않은 특성을 나열합니다. 시간이 지남에 따라 액션, 주요 비주얼 세부 사항 및 사운드 이벤트를 발생 순서대로 설명합니다. LTXVConditioning 블록은 선택한 프레임 속도와 함께 프롬프트를 적용하여 타이밍과 모션이 일관되게 해석되도록 합니다. 대화, 효과 또는 분위기가 필요할 때 오디오를 프롬프트의 일부로 취급하십시오.
비디오 설정#
Width, Height 및 총 Video Frames를 설정한 다음, 필요에 따라 첫/마지막 컨트롤 간격을 위한 Length를 선택합니다. 워크플로우는 모델 요구 사항에 맞게 차원을 보장하고 입력을 적절히 스케일링합니다. 입력 이미지가 더 큰 경우, 그래프는 잠재 캔버스를 초기화하기 위해 크기를 읽고 제공된 프레임을 맞추기 위해 크기를 조정합니다. 의도한 전달에 맞는 프레임 속도를 선택하십시오.
잠재#
이 그룹은 빈 비디오 잠재와 일치하는 오디오 잠재를 빌드한 후, 모델이 오디오와 비디오를 함께 샘플링할 수 있도록 이를 연결합니다. 기본 패스에서 첫/마지막 프레임 가이드가 처음 주입되는 곳입니다. 중간 프레임을 제공하는 것은 선택 사항이지만 중간 샷의 정체성 또는 키 포즈를 안정화하는 데 유용합니다. 결과는 기본 샘플링을 위한 단일 AV 잠재입니다.
기본 샘플러#
기본 패스는 랜덤 노이즈, 스케줄러 및 구성된 가이더를 사용하여 프롬프트를 일관된 AV 잠재로 해결합니다. 가이더는 긍정적 및 부정적 조건화와 함께 LoRA 수정 모델을 받습니다. 샘플링 후, 잠재는 비디오와 오디오로 다시 분할되어 비디오는 업스케일되는 동안 오디오는 정렬된 상태로 유지됩니다. 이 단계는 업스케일 패스가 다듬을 전역 모션, 페이싱 및 오디오 리듬을 설정합니다.
업스케일#
업스케일러는 두 번째 샘플링 패스 전에 잠재를 더 높은 공간 해상도로 끌어올립니다. 첫/마지막 프레임 컨트롤은 이 높은 해상도에서 다시 적용되어 시작과 종료 프레임을 정확히 고정합니다. 여기에서 중간 프레임을 피드하여 업스케일을 통해 기능을 안정적으로 유지할 수도 있습니다. 결과는 계획된 모션을 보존하는 더 선명한 AV 잠재입니다.
모델#
이 모델 그룹은 업스케일 그룹에서 사용되는 LTX-2 잠재 업스케일러를 로드합니다. 특정 x2 공간 모델을 준비하고 이를 잠재 업샘플러 노드에 노출합니다. 여러 업스케일러를 유지하는 경우 여기에서 모델을 전환하십시오. 기본 x2 동작에 만족하는 경우 이 그룹은 그대로 두십시오.
업스케일 샘플링(2x)#
두 번째 패스는 별도의 샘플러와 시그마 스케줄을 사용하여 업스케일된 잠재에서 가이드 샘플링을 수행합니다. 크롭 인식 가이드는 새로운 해상도에 조건화를 맞춰 세부 사항이 일관되게 유지되도록 합니다. 출력은 다시 비디오와 오디오로 분할되어 디코딩됩니다. 이 패스는 주로 가장자리를 선명하게 하고, 작은 텍스트나 질감을 개선하며, 첫/마지막 프레임 일치를 유지합니다.
LTX-2-19b-IC-LoRA-Detailer#
이 그룹은 LTX-2의 이미지-조건화 경로에 맞춰 튜닝된 디테일 지향 LoRA를 적용합니다. 실제 이미지에 조건화한 후 더 많은 미세 디테일이나 더 타이트한 텍스처가 필요할 때 활성화하십시오. 프롬프트나 프레임 제약 조건을 과도하게 압도하지 않도록 강도를 적절히 유지하십시오. 입력이 이미 선명하고 잘 조명된 경우 이 LoRA를 우회할 수 있습니다.
카메라-컨트롤-Dolly-In#
시간이 지남에 따라 카메라가 피사체로 밀어야 할 때 이 LoRA를 사용하십시오. 첫/마지막 목표를 존중하면서 모델을 앞으로의 모션으로 편향시킵니다. 이동을 설명하는 텍스트 큐와 함께 사용하여 가장 강력한 효과를 얻으십시오. 모션이 의도한 프레이밍을 초과하는 경우 강도를 줄이십시오.
카메라-컨트롤-Dolly-Out#
샷이 피사체에서 멀어져야 할 때 선택하십시오. 시퀀스가 진행됨에 따라 음의 시차와 넓어지는 컨텍스트를 생성하는 데 도움이 됩니다. 마지막 프레임이 출구 구성과 일치하여 이동이 깔끔하게 끝나도록 유지하십시오. 영화적 공개를 위한 분위기 오디오 프롬프트와 결합하십시오.
카메라-컨트롤-Dolly-Left#
왼쪽으로의 측면 이동을 적용하여 돌리나 트럭으로 읽힙니다. 대화 비트 또는 세트를 가로지르는 공개에 적합합니다. 객체가 번지거나 이동하는 경우 첫/마지막 강도를 약간 증가시키거나 중간 프레임을 추가하십시오. LoRA를 보완하기 위해 "천천히 왼쪽으로 이동"과 같은 작은 텍스트 힌트와 균형을 맞추십시오.
카메라-컨트롤-Dolly-Right#
Dolly-Left의 반대편으로, 모션을 오른쪽으로 편향시킵니다. 캐릭터를 따르거나 새로운 피사체로 패닝할 때 잘 작동합니다. 푸시 인을 요청하는 경우 LoRA 강도를 적당히 유지하여 상충되는 신호를 피하십시오. 마지막 프레임의 구성이 원하는 끝점과 일치하는지 확인하십시오.
카메라-컨트롤-Jib-Up#
수직 상승을 생성하여 공개를 들어 올리거나 설정 샷에 유용합니다. 시점 변경 및 지평선 이동에 대한 얕은 프롬프트와 결합하여 명확성을 제공합니다. 이동이 강할 때 천장이나 하늘 노출을 주시하십시오; 불투명 하이라이트를 피하기 위해 부정적 프롬프트를 조정하십시오. 필요한 경우 중간 상승 프레이밍을 보여주는 중간 프레임을 추가하십시오.
카메라-컨트롤-Jib-Down#
종종 디테일이나 캐릭터에 정착하기 위해 사용되는 제어된 하강을 생성합니다. 강조를 위해 조용한 오디오 베드와 결합할 수 있습니다. 마지막 프레임에 타겟 객체나 얼굴이 포함되어 모션이 결정적으로 해결되도록 하십시오. 하강이 너무 빠르게 느껴지면 LoRA 강도를 조정하십시오.
카메라-컨트롤-Static#
카메라가 모션 없이 가상으로 고정되어 피사체만 움직이는 액션이 필요할 때 사용합니다. 대화나 제품 샷에 유용하며, 첫/마지막 프레임 컨트롤과 결합하여 구성을 완벽하게 안정적으로 유지합니다. 카메라 LoRA 대신 텍스트 프롬프트를 통해 미세한 모션을 추가하십시오.
Comfyui LTX-2 First Last Frame 워크플로우의 주요 노드#
LTXVFirstLastFrameControl_TTP (#227)#
기본 AV 잠재에 첫 번째 및 마지막 이미지 제약을 주입합니다. first_strength를 조정하여 첫 번째 프레임이 얼마나 엄격히 일치하는지를 제어하고 last_strength를 조정하여 시퀀스가 최종 프레임에 얼마나 강하게 도달하는지를 결정합니다. 클립 중간이 드리프트하는 경우, LTXVMiddleFrame_TTP를 통해 중간 프레임을 제공하고 모션을 과도하게 제약하지 않도록 강도를 적절히 유지하십시오.
LTXVMiddleFrame_TTP (#181)#
시작과 끝 사이의 선택한 position에서 가이드 프레임을 삽입하여 정체성이나 포즈를 안정화합니다. 피사체가 중간 샷에서 너무 많이 변경될 때 strength를 증가시키십시오. 신중하게 사용하십시오; 많은 경쟁 제약보다는 단일, 잘 선택된 중간 참조에서 최상의 결과가 나옵니다.
LTXVLatentUpsampler (#217)#
LTX-2 공간 업스케일러를 사용하여 잠재 공간에서 x2 공간 업스케일을 수행합니다. 더 높은 해상도 세부 사항이 모델에 의해 정제되도록 2x 샘플링 패스 전에 이것을 사용하십시오. 메모리가 부족한 경우, 이 단계에서 LoRA 사용을 최소화하십시오.
LTXVFirstLastFrameControl_TTP (#223)#
2x 업스케일 후 시작/종료(및 선택적 중간) 가이드를 재적용합니다. 이것은 최종 디코딩된 프레임이 전달 해상도에서 첫 번째 및 마지막 참조와 정확히 일치하도록 보장합니다. 업스케일이 미세한 이동을 도입할 경우, 기본 단계에서가 아니라 여기에서 last_strength를 약간 높이십시오.
LTXVSpatioTemporalTiledVAEDecode (#230)#
공간-시간 타일링을 사용하여 고해상도 비디오 잠재를 프레임으로 디코딩합니다. 이음새나 시간적 깜박임이 보일 때만 타일 및 중첩 설정을 조정하십시오; 더 큰 중첩은 더 많은 VRAM을 소모하지만 일관성을 개선합니다. 마지막 프레임이 미세한 드리프트를 보이는 경우 last_frame_fix를 유지하십시오.
VHS_VideoCombine (#254)#
디코딩된 프레임과 생성된 오디오를 단일 MP4로 멀티플렉싱합니다. 출력 format, pix_fmt, 및 crf를 전달 목표에 맞게 설정하고, 조건화와 일치하는 frame_rate를 선택하십시오. 각 렌더링과 함께 재현 가능성 기록을 유지하기 위해 메타데이터 저장을 활성화하십시오.
선택적 추가 사항#
- GPU가 제한된 경우 LTX-2의 FP8 가중치를 사용하십시오; VRAM이 허용할 때 전체 정밀도로 전환하여 최고의 충실도를 얻으십시오. 가중치는 Lightricks/LTX-2에서 제공됩니다.
- 너비와 높이가 32n + 1 형식일 때 치수가 가장 잘 작동합니다; 총 프레임은 8n + 1 형식일 때 가장 잘 작동합니다. 워크플로우는 필요한 경우 가장 가까운 유효 값으로 자동 수정합니다.
- 긍정적 프롬프트에 직접 오디오 큐를 설명하십시오(대화, 효과, 분위기). 모델의 조인트 AV 잠재는 입술json
, 행동 및 소리를 정렬된 상태로 유지합니다.
- 첫 번째/마지막 강도를 중간으로 시작하십시오; 최종 포즈를 고정하려면 마지막 강도를 높이거나 정체성을 안정화하기 위해 중간 프레임을 추가하십시오.
- 명확한 의도를 위해 한 번에 하나의 카메라 LoRA만 적용하십시오. Lightricks LTX-2 LoRA collection에서 공식 옵션을 탐색하십시오.
감사의 말#
이 워크플로우는 다음의 작업 및 리소스를 구현하고 구축합니다. 우리는 LTX-2 First Last Frame Workflow Reference의 기여와 유지보수에 대해 @AIKSK에게 감사를 표합니다. 권위 있는 세부 사항은 아래에 연결된 원본 문서 및 리포지토리를 참조하십시오.
리소스#
- RunningHub/LTX-2 First Last Frame Workflow Reference
- 문서 / 릴리스 노트: LTX-2 First Last Frame Workflow Reference from AIKSK
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이선스 및 조건에 따릅니다.

