
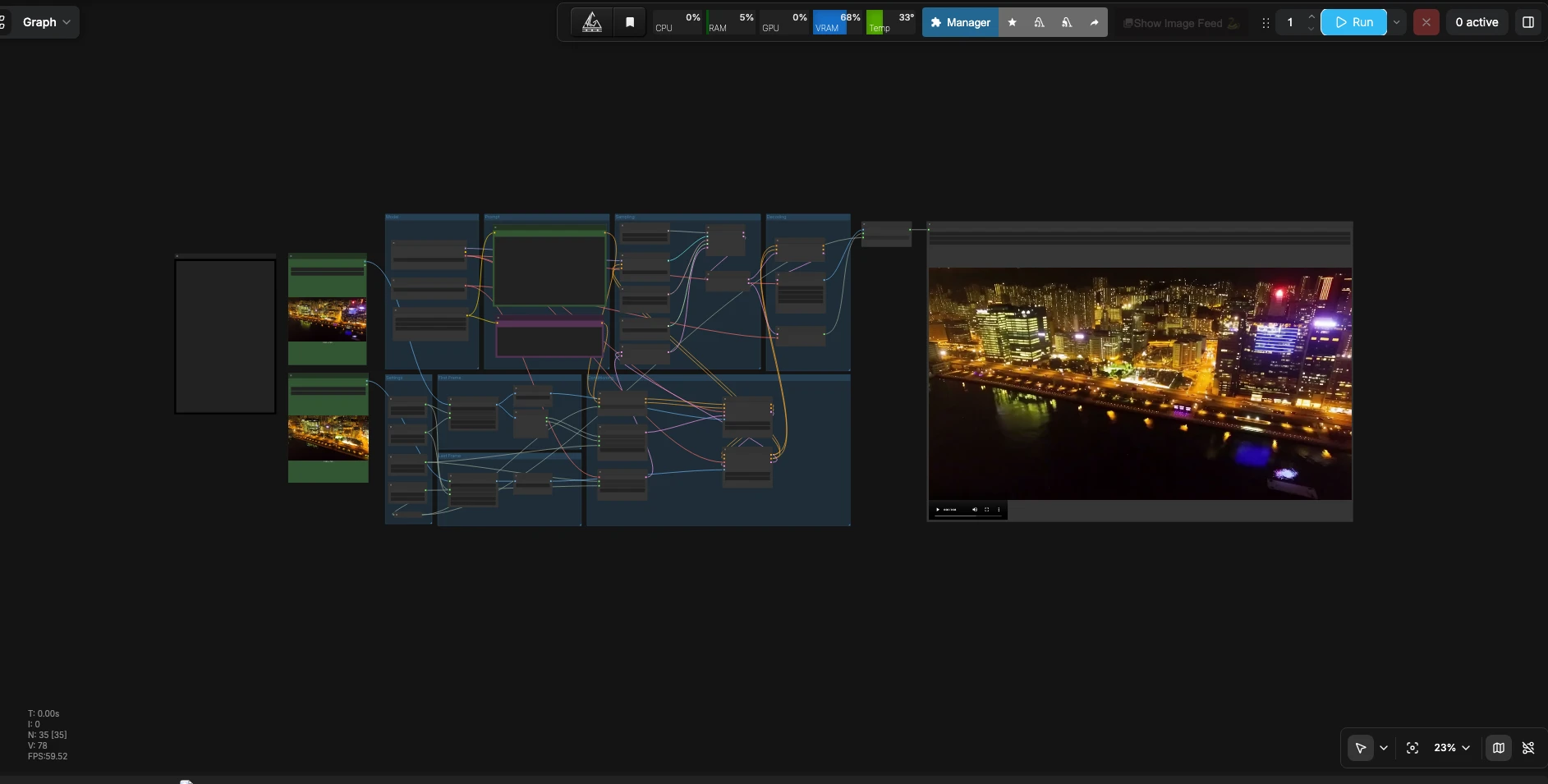
LTX 2.3 첫 번째 마지막 프레임에서 비디오로#
LTX 2.3 첫 번째 마지막 프레임에서 비디오로는 ComfyUI 워크플로로, 두 정지 이미지를 매끄럽고 연속적인 비디오로 변환하며 동기화된 오디오를 제공합니다. 첫 번째 프레임, 마지막 프레임, 움직임, 장면 세부사항 및 사운드를 설명하는 자연어 프롬프트를 제공합니다. LTX-2.3 22B Distilled FP8 체크포인트에 의해 구동되는 파이프라인은 일관된 외형과 타이밍을 유지하면서 이미지를 보간합니다. 매끄러운 전환이나 ComfyUI 내부에서 직접 생성된 짧은 루핑 클립이 필요한 편집자, 모션 디자이너 및 스토리보드 아티스트에게 이상적입니다.
이 LTX 2.3 첫 번째 마지막 프레임 워크플로는 효율적인 추론과 높은 프롬프트 충실도를 강조합니다. FP8 가중치는 VRAM 사용을 제한하며, Gemma 3 12B 텍스트 인코더는 시각적 및 오디오 지침 모두에 대한 의미 이해를 향상시킵니다. 그 결과, 첫 번째에서 마지막 프레임까지의 일관된 시각적 패시지가 귀하의 프롬프트를 존중하고 생성된 오디오와 동기화됩니다.
Comfyui LTX 2.3 첫 번째 마지막 프레임 워크플로의 주요 모델#
- LTX-2.3 22B Distilled FP8 체크포인트 by Lightricks. 두 이미지 가이드와 텍스트 프롬프트를 조건으로 사용하여 시간적으로 일관된 프레임을 합성하기 위해 효율적인 추론을 위해 증류된 핵심 비디오 생성 모델입니다. 모델 카드
- Gemma 3 12B IT 텍스트 인코더. 프롬프트의 시각적 및 오디오 측면에 대해 강력한 언어 이해를 제공하여 정확한 움직임, 장면 속성 및 사운드트랙 큐를 가능하게 합니다. 모델 카드
- LTX-2.3 잠재 VAE for 비디오 및 오디오. 디코딩 중 이미지와 파형 오디오를 압축된 잠재로 매핑하고 다시 매핑하여 품질을 유지하면서 샘플링을 효율적으로 유지합니다. LTX-2.3 FP8 릴리스와 함께 제공됩니다. 모델 카드
Comfyui LTX 2.3 첫 번째 마지막 프레임 워크플로 사용 방법#
이 워크플로는 두 참조 이미지를 가져와 프롬프트를 구성하고 첫 번째 및 마지막 프레임 가이드를 사용하여 조건을 구축하고, 동기화된 오디오와 함께 비디오 잠재를 샘플링하고, 모든 것을 재생 가능한 파일로 디코딩합니다.
설정
- 설정 그룹에서 목표 해상도, 프레임 수 및 프레임 속도를 설정합니다. 너비와 높이는 작업 캔버스를 정의하며, 입력 프레임은 모델이 깨끗하게 보간할 수 있도록 크기가 조정됩니다. 프레임 수는 전환이 얼마나 오래 지속되는지를 제어하고, 프레임 속도는 재생 속도를 설정합니다. 소스와 일치하는 종횡비를 선택하여 원하지 않는 자르기를 피하십시오. 노드
WIDTH(#113),HEIGHT(#98),Length(#102), 및Frame Rate(int)(#114)가 이러한 선택을 고정합니다.
첫 번째 프레임
Load First Frame(#31)에서 시작 이미지를 로드합니다.ResizeImageMaskNode(#124)에 의해 목표 차원으로 크기가 조정되고LTXVPreprocess(#104)에 의해 정규화됩니다. 이는 클립의 시작 부분에서 강력한 구조적 및 색상 가이드로 작용하도록 첫 번째 프레임을 준비합니다. 최상의 결과를 위해 선명하고 조명이 잘 된 이미지를 사용하십시오.
마지막 프레임
Load Last Frame(#39)에서 종료 이미지를 로드합니다. 이미지는ResizeImageMaskNode(#125)에 의해 동일한 크기로 맞춰지고LTXVPreprocess(#99)에 의해 정규화됩니다. 이는 전환의 끝에서 원하는 최종 외형과 레이아웃을 보장합니다. 루프의 경우, 마지막 프레임을 첫 번째 프레임과 시각적으로 호환되도록 만드십시오.
프롬프트
LTXAVTextEncoderLoader(#103)에서 텍스트 인코더를 제공하며, 두 개의CLIPTextEncode노드는 긍정적 및 부정적 프롬프트를 캡처합니다. 긍정적 프롬프트 (CLIPTextEncode(#128))에서는 카메라 움직임, 주제, 조명, “Music: ambient pads with soft percussion” 또는 “Dialogue: brief whisper.”와 같은 오디오 큐를 설명합니다. 부정적 프롬프트 (CLIPTextEncode(#112))에서는 억제하고 싶은 아티팩트나 특성을 나열할 수 있습니다.
조건
LTXVConditioning(#109)는 텍스트 조건을 타이밍 정보와 병합하여 움직임과 오디오가 선택한 프레임 속도와 일치하도록 합니다.EmptyLTXVLatentVideo(#108)는 해상도와 길이에 맞는 비디오 잠재를 생성합니다. 두 번의LTXVAddGuide패스는 첫 번째 프레임 (LTXVAddGuide(#115))과 마지막 프레임 (LTXVAddGuide(#111))을 차례로 연결하여 모델이 어디에서 시작하고 끝낼지를 알게 합니다.LTXVEmptyLatentAudio(#101)는 동일한 지속 시간의 오디오 잠재를 초기화하고,LTXVConcatAVLatent(#119)는 샘플링을 위해 오디오 및 비디오 잠재를 번들로 묶습니다.
모델
CheckpointLoaderSimple(#127)은 LTX-2.3 22B Distilled FP8 가중치와 비디오 VAE를 로드하며,LTXVAudioVAELoader(#126)는 오디오 VAE를 제공합니다. 이들은 사전 구성되어 있어 창의적인 입력에 집중할 수 있습니다.
샘플링
CFGGuider(#116)는 텍스트 및 가이드 프레임에 대한 모델의 준수를 균형 있게 조절합니다.RandomNoise(#100)는 재현성을 위해 시드를 설정합니다. 샘플러는SamplerEulerAncestral(#117)과ManualSigmas(#118)의 사용자 정의 일정으로SamplerCustomAdvanced(#120)에 의해 구동되어 잠재를 귀하의 움직임 및 오디오 지침을 따르는 일관된 시퀀스로 점진적으로 정제합니다.
디코딩
- 샘플링 후,
LTXVSeparateAVLatent(#121)는 결합된 잠재를 비디오 및 오디오로 다시 분리합니다.LTXVCropGuides(#106)는 이미지 디코딩 전에 가장자리 아티팩트를 줄이기 위해 공간적 지침을 정제합니다.VAEDecodeTiled(#105)는 프레임 시퀀스를 생성하고,LTXVAudioVAEDecode(#107)는 오디오 파형을 생성합니다.CreateVideo(#122)는 선택한 fps로 프레임과 사운드를 혼합하고SaveVideo(#68)는 최종 파일을 ComfyUI 출력에 저장합니다.
Comfyui LTX 2.3 첫 번째 마지막 프레임 워크플로의 주요 노드#
EmptyLTXVLatentVideo (#108)
- 클립의 작업 해상도 및 지속 시간을 정의합니다. 여기에서 너비, 높이 및 길이를 조정하여 시각적 규모와 전환 시간을 설정합니다. 더 긴 지속 시간은 프롬프트에서 더 강한 움직임 큐가 필요합니다.
LTXVAddGuide (#115)
- 시퀀스의 시작 부분에서 첫 번째 프레임을 구조적 및 색상 앵커로 삽입합니다. 시작이 소스에서 벗어날 경우, 이 가이드의 영향을 증가시키십시오; 과도하게 제약된 느낌이 들면, 더 많은 움직임을 허용하도록 약간 줄이십시오.
LTXVAddGuide (#111)
- 마지막 프레임을 사용하여 클립의 끝에서 목표 외형을 고정합니다. 전환이 과도하게 넘어가거나 마지막 프레임에 도달하지 못할 경우, 가이드 영향을 증가시키십시오; 끝에서 너무 강하게 스냅되는 경우, 약간 완화하십시오.
CFGGuider (#116)
- 모델이 텍스트 및 이미지 조건을 얼마나 강하게 따르는지를 제어합니다. 높은 가이드는 프롬프트와 가이드를 강조하지만 부드러움을 줄일 수 있습니다; 낮은 값은 자유로움을 느끼게 하지만 의도된 외형에서 벗어날 수 있습니다. 작은 단계로 조정하고 비교할 때 동일한 시드를 재사용하십시오.
SamplerCustomAdvanced (#120)와 SamplerEulerAncestral (#117) 및 ManualSigmas (#118)
- 안정적인 움직임을 위한 일관된 일정으로 디노이징을 구동합니다. 짧은 일정은 더 빠르게 렌더링되지만 거칠 수 있습니다; 더 길거나 부드러운 일정은 일관성을 개선하지만 추가 계산 비용이 필요합니다. 다른 매개변수를 A/B 테스트할 때 일정을 일관되게 유지하십시오.
CreateVideo (#122)
- 선택한 프레임 속도로 디코딩된 프레임과 오디오를 최종 클립으로 혼합합니다. 입술 모양, 발소리 또는 음악의 박동이 일치하도록 동일한 fps를 사용하십시오.
선택적 추가 기능#
- 동사 및 타이밍이 포함된 프롬프트 작성: “카메라가 앞으로 움직인다,” “접근하면서 조명이 어두워진다,” “Music: sparse piano with soft reverb.” 명확한 동사는 LTX 2.3 첫 번째 마지막 프레임 파이프라인이 움직임과 리듬을 유추하는 데 도움이 됩니다.
- 두 이미지의 종횡비 및 방향을 일치시키십시오. 큰 불일치는 원치 않는 자르기나 늘어남을 초래할 수 있습니다.
- 매끄러운 루프를 위해 마지막 프레임을 첫 번째 프레임과 거의 일치시키고 카메라 움직임을 순환적으로 유지하십시오.
RandomNoise의 시드를 재사용하여 프롬프트나 가이드 강도를 반복할 때 모양을 재현하십시오; 시드를 변경하여 새로운 변형을 탐색하십시오.- 구현 세부사항이나 사용자 정의 노드 참조가 필요한 경우, ComfyUI의 LTX 통합 및 ComfyUI-LTXTricks와 같은 유틸리티를 참조하십시오. Repository
감사의 말#
이 워크플로는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 Lightricks의 LTX-2.3 22B Distilled FP8 Checkpoint, Google의 Gemma 3 12B IT FP4 Text Encoder, logtd의 ComfyUI-LTXTricks Custom Nodes, 그리고 Comfy.org의 Comfy.org Official Workflow에 대한 기여 및 유지 관리에 감사를 표합니다. 권위 있는 세부사항은 아래에 연결된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
Note: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이선스 및 약관에 따릅니다.

