
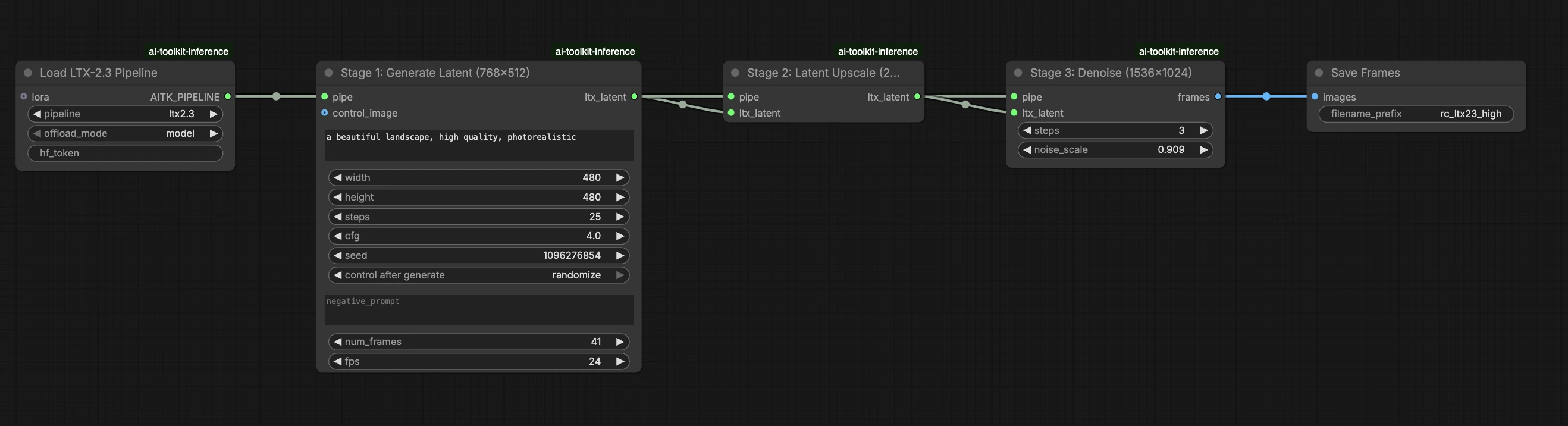
LTX 2.3 LoRA ComfyUI 추론: LTX 2.3 파이프라인을 통한 훈련 일치 AI Toolkit LoRA 출력#
이 생산 준비된 RunComfy 워크플로우는 RC LTX 2.3 (LTX2Pipeline) (파이프라인 레벨 조정, 일반 샘플러 그래프가 아님)을 통해 ComfyUI에서 LTX 2.3 LoRA 추론을 실행합니다. RunComfy는 이 커스텀 노드를 구축하고 오픈 소스화했습니다—runcomfy-com 저장소를 참조하세요—그리고 lora_path와 lora_scale로 어댑터 적용을 제어합니다.
참고: 이 워크플로우는 2X Large 이상의 머신이 필요합니다.
왜 LTX 2.3 LoRA ComfyUI 추론이 ComfyUI에서 다르게 보이는가#
AI Toolkit 훈련 미리보기는 모델별 LTX 2.3 파이프라인을 통해 렌더링되며, 텍스트 인코딩, 스케줄링, LoRA 주입이 함께 작동하도록 설계되었습니다. ComfyUI에서 LTX 2.3을 다른 그래프(또는 다른 LoRA 로더 경로)로 재구성하면 이러한 상호 작용이 달라질 수 있으므로 동일한 프롬프트, 단계, CFG, 시드를 복사해도 여전히 눈에 띄는 드리프트가 발생합니다. RunComfy RC 파이프라인 노드는 LTX 2.3을 LTX2Pipeline에서 처음부터 끝까지 실행하고 그 파이프라인 내에서 LoRA를 적용하여 추론을 미리보기 동작과 일치시킵니다. 출처: RunComfy 오픈 소스 저장소.
LTX 2.3 LoRA ComfyUI 추론 워크플로우 사용법#
1단계: LoRA 경로를 가져와 워크플로우에 로드하세요 (2가지 옵션)#
옵션 A — RunComfy 훈련 결과 → 로컬 ComfyUI로 다운로드:
- Trainer → LoRA Assets로 이동하세요
- 사용하려는 LoRA를 찾으세요
- 오른쪽의 ⋮ (세 점) 메뉴를 클릭 → Copy LoRA Link를 선택하세요
- ComfyUI 워크플로우 페이지에서 복사한 링크를 UI의 오른쪽 상단에 있는 Download 입력 필드에 붙여넣으세요
- Download를 클릭하기 전에, 대상 폴더가 ComfyUI > models > loras로 설정되어 있는지 확인하세요 (이 폴더가 다운로드 대상이어야 함)
- Download를 클릭하세요 — 이것은 LoRA 파일이 올바른
models/loras디렉토리에 저장되도록 합니다 - 다운로드가 완료되면, 페이지를 새로 고침하세요
- 이제 LoRA가 워크플로우의 LoRA 선택 드롭다운에 나타납니다 — 그것을 선택하세요
옵션 B — 직접 LoRA URL (옵션 A를 무시):
path / url입력 필드에 직접.safetensors다운로드 URL을 붙여넣으세요- URL이 이곳에 제공되면, 옵션 A를 무시합니다 — 워크플로우는 런타임에 URL에서 직접 LoRA를 로드합니다
- 로컬 다운로드나 파일 배치가 필요하지 않습니다
팁: URL이 실제 .safetensors 파일로 해결되는지 확인하세요 (랜딩 페이지나 리디렉션이 아님).
2단계: 추론 매개변수를 훈련 샘플 설정과 맞추세요#
LoRA 노드에서, lora_path에 어댑터를 선택하세요 (옵션 A), 또는 path / url에 직접 .safetensors 링크를 붙여넣으세요 (옵션 B가 드롭다운을 무시). 그런 다음 훈련 미리보기에서 사용한 강도로 lora_scale을 설정하고 거기서부터 조정하세요.
나머지 매개변수는 Generate 노드에 있습니다 (그리고 그래프에 따라 Load Pipeline 노드에도):
prompt: 텍스트 프롬프트 (훈련 시 사용했다면 트리거 단어 포함)width/height: 출력 해상도; 가장 깨끗한 비교를 위해 훈련 미리보기 크기에 맞추세요 (LTX 2.3의 경우 32의 배수가 권장됨)num_frames: 출력 비디오 프레임 수sample_steps: 추론 단계 수 (30이 일반적인 기본값)guidance_scale: CFG/가이던스 값 (5.5가 일반적인 기본값; 7을 초과하지 마세요)seed: 재현을 위한 고정 시드; 변화를 탐색하기 위해 변경하세요seed_mode(존재하는 경우에만):fixed또는randomize선택frame_rate: 출력 FPS; 모션 정렬을 위해 훈련 설정과 일관되게 유지하세요
훈련 정렬 팁: 훈련 중에 샘플링 값을 커스터마이즈했다면 (seed, guidance_scale, sample_steps, 트리거 단어, 해상도), 여기서 정확한 값을 반영하세요. RunComfy에서 훈련했다면, Trainer → LoRA Assets > Config로 이동하여 해결된 YAML을 보고 미리보기/샘플 설정을 워크플로우 노드에 복사하세요.
3단계: LTX 2.3 LoRA ComfyUI 추론 실행#
Queue/Run을 클릭하세요 — SaveVideo 노드가 결과를 ComfyUI 출력 폴더에 씁니다.
빠른 체크리스트:
- ✓ LoRA는 다음 중 하나:
ComfyUI/models/loras에 다운로드 (옵션 A), 또는 직접.safetensorsURL을 통해 로드 (옵션 B) - ✓ 로컬 다운로드 후 페이지 새로 고침 (옵션 A만 해당)
- ✓ 추론 매개변수가 훈련
샘플구성과 일치 (커스터마이즈된 경우)
위의 모든 것이 올바르다면, 여기서의 추론 결과는 훈련 미리보기와 밀접하게 일치해야 합니다.
LTX 2.3 LoRA ComfyUI 추론 문제 해결#
대부분의 LTX 2.3 "훈련 미리보기 vs ComfyUI 추론" 갭은 파이프라인 레벨 차이 (모델이 로드되는 방식, 스케줄링 및 LoRA가 병합되는 방식)에서 발생하며, 단일 잘못된 노브에서 발생하는 것이 아닙니다. 이 RunComfy 워크플로우는 RC LTX 2.3 (LTX2Pipeline)을 통해 추론을 처음부터 끝까지 실행하고 lora_path / lora_scale을 통해 그 파이프라인 내에서 LoRA를 적용하여 가장 가까운 "훈련 일치" 기준선을 복원합니다.
(1) LoRA 모양 불일치 또는 "키가 로드되지 않음" 경고#
이유 LoRA가 다른 모델 패밀리 또는 다른 LTX 변형을 위해 훈련되었습니다. 여러 lora key not loaded 라인과 잠재적인 모양 불일치 오류가 발생할 수 있습니다.
해결 방법 (권장)
- LoRA가 AI Toolkit으로 LTX 2.3을 위해 훈련되었는지 확인하세요 (LTX 2.0 / 2.1 / 2.2 LoRA는 상호 교환할 수 없음).
- 그래프를 LoRA에 대해 "단일 경로"로 유지하세요: 어댑터를 워크플로우의
lora_path입력을 통해서만 로드하고 LTX2Pipeline이 병합을 처리하도록 하세요. 추가적인 일반 LoRA 로더를 병렬로 스택하지 마세요. - 이미 불일치에 도달했고 ComfyUI가 이후에 관련 없는 CUDA/OOM 오류를 생성하기 시작하면, ComfyUI 프로세스를 재시작하여 GPU + 모델 상태를 완전히 리셋한 후 호환되는 LoRA로 다시 시도하세요.
(2) 추론 결과가 훈련 미리보기와 일치하지 않음#
이유 LoRA가 로드되더라도, ComfyUI 그래프가 훈련 미리보기 파이프라인과 일치하지 않으면 (기본값이 다르거나, LoRA 주입 경로가 다르거나, 스케줄링이 다름) 결과가 여전히 드리프트할 수 있습니다.
해결 방법 (권장)
- 이 워크플로우를 사용하고,
lora_path에 직접.safetensors링크를 붙여넣으세요. - AI Toolkit 훈련 구성에서 샘플링 값을 복사하세요 (또는 RunComfy Trainer → LoRA Assets Config):
width,height,num_frames,sample_steps,guidance_scale,seed,frame_rate. - "추가 속도 스택"을 비교에서 제외하세요, 훈련/샘플링 시 사용하지 않았다면.
(3) LoRAs 사용이 추론 시간을 크게 증가시킴#
이유 LoRA 경로가 추가 패칭/디퀀타이제이션 작업을 강제하거나 기본 모델보다 느린 코드 경로로 가중치를 적용할 때 LTX 2.3이 훨씬 느려질 수 있습니다.
해결 방법 (권장)
- 이 워크플로우의 RC LTX 2.3 (LTX2Pipeline) 경로를 사용하고
lora_path/lora_scale을 통해 어댑터를 전달하세요. 이 설정에서는 파이프라인 로드 중 한 번 병합 (AI Toolkit 스타일)되어, 단계당 샘플링 비용이 기본 모델에 가깝게 유지됩니다. - 미리보기 일치 동작을 추구할 때, 여러 LoRA 로더를 스택하거나 로더 경로를 혼합하지 마세요. 하나의
lora_path+ 하나의lora_scale로 기준선이 맞을 때까지 유지하세요.
(4) 큰 해상도나 긴 비디오에서 OOM 오류#
이유 LTX 2.3은 22B 파라미터 모델이며, 비디오 생성은 VRAM 집약적입니다. 높은 해상도나 많은 프레임은 특히 LoRA 오버헤드와 함께 GPU 메모리를 초과할 수 있습니다.
해결 방법 (권장)
- 2X Large (80 GB VRAM) 이상의 머신을 사용하세요. 이 워크플로우는 Medium, Large, 또는 X Large 머신과 호환되지 않습니다.
- 빠르게 반복해야 한다면 해상도나 프레임 수를 줄이고, 최종 렌더링 시 확장하세요.
- 가능하다면 VAE 타일링을 활성화하세요 — 최소한의 품질 손실로 ~3 GB VRAM을 절약할 수 있습니다.
지금 LTX 2.3 LoRA ComfyUI 추론 실행#
워크플로우를 열고 lora_path를 설정한 후 Queue/Run을 클릭하여 AI Toolkit 훈련 미리보기에 가까운 LTX 2.3 LoRA 결과를 얻으세요.
