
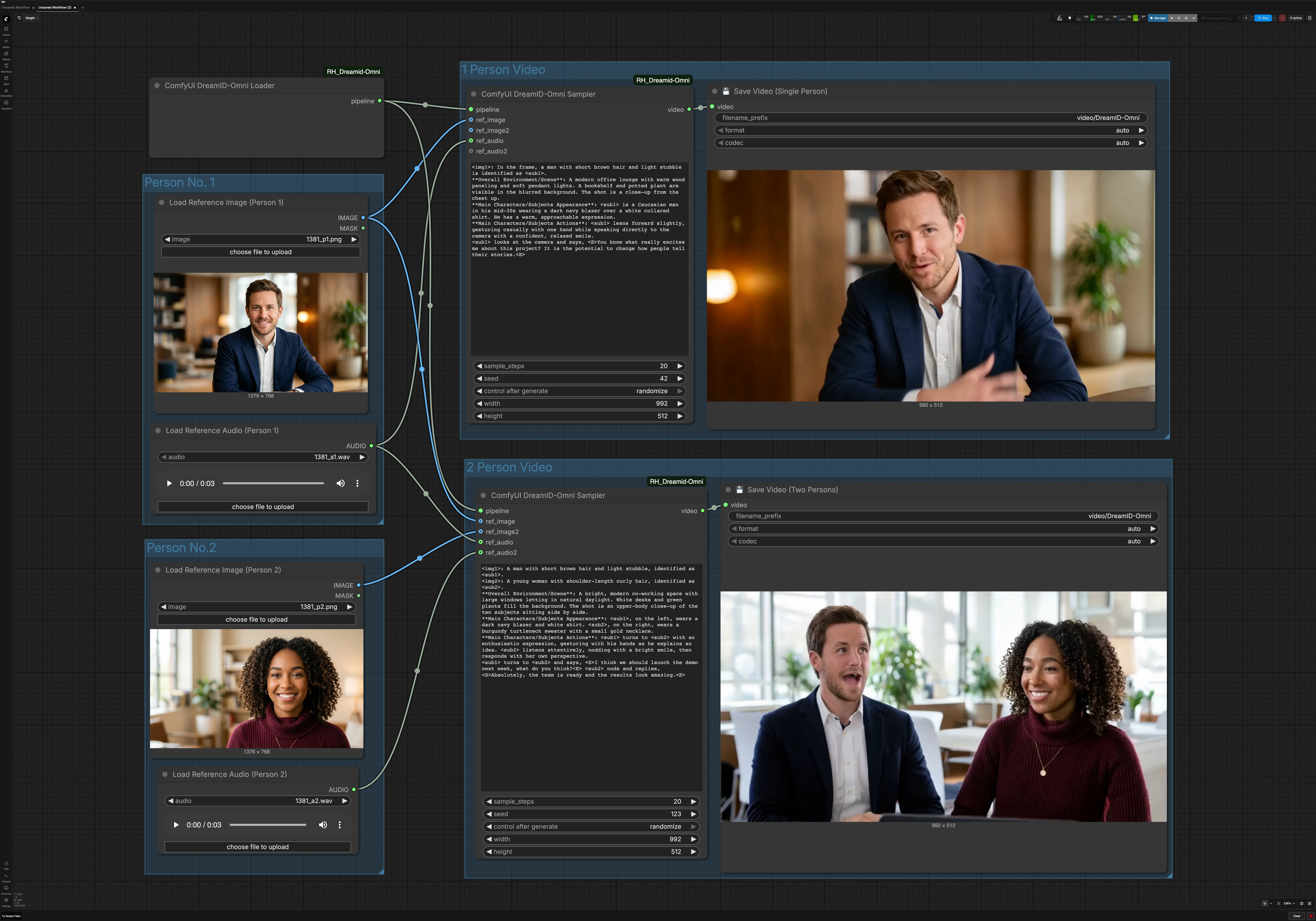
ComfyUI용 DreamID-Omni 단일 및 이중 캐릭터 대화 비디오 워크플로우#
이 워크플로우는 단일 참조 사진과 오디오 클립을 정체성을 유지하는 대화형 비디오로 변환합니다. DreamID-Omni 모델에 의해 구동되며, 현대 비디오 백본과 MMAudio 기반의 입술 움직임을 결합하여 주제가 자연스럽게 말하면서도 이미지 속 얼굴을 유지할 수 있습니다. 두 캐릭터도 지원하여 두 목소리로 구동되는 나란히 대화하는 클립을 가능케 합니다.
크리에이터, 제품 팀, 연구자를 위해 설계된 DreamID-Omni 워크플로우는 ComfyUI에서 디지털 아바타, 개인화된 발표, 튜토리얼 소개 및 AI 대화 장면에 이상적입니다. 사진과 오디오를 제공하고, 짧은 프롬프트로 샷을 설명하면 그래프가 공유할 준비가 된 정교한 비디오를 렌더링합니다.
Comfyui DreamID-Omni 워크플로우의 주요 모델#
- DreamID-Omni. 오디오에 반응하여 현실적인 입술 움직임을 위해 프레임 전체에서 참조 이미지의 인물을 보존하는 핵심 정체성 모듈입니다. 공식 레포 및 가중치에 대한 자세한 내용은 다음을 참조하세요: DreamID-Omni 및 DreamID-Omni on Hugging Face.
- Wan 2.2 비디오 생성. DreamID-Omni가 얼굴 정체성을 조정하는 동안 일관된 움직임, 조명 및 샷 구성을 합성하는 고용량 비디오 확산 백본입니다.
- MMAudio. 제공된 음성과 일치하도록 입 모양과 미세한 얼굴 신호를 조건화하여 입술 동기화의 현실성을 향상시키는 오디오 표현 모델입니다.
Comfyui DreamID-Omni 워크플로우 사용 방법#
이 그래프는 두 개의 병렬 경로를 가지고 있습니다. 단일 인물 경로는 하나의 이미지와 하나의 오디오를 사용합니다. 이인 경로는 두 개의 이미지와 두 개의 오디오를 사용하여 대화형 클립을 생성합니다. 공유된 DreamID-Omni 로더가 두 경로 모두를 위한 파이프라인을 초기화합니다.
인물 번호 1#
Load Reference Image (Person 1) (#6)를 사용하여 조명과 차폐가 최소화된 명확한 정면 초상화를 선택합니다. Load Reference Audio (Person 1) (#7)를 사용하여 캐릭터가 말할 내용을 제공하세요. 음악이나 강한 배경 소음이 없는 깨끗한 오디오가 더 나은 입술 동기화를 제공합니다. 이 쌍은 단일 인물 모드와, 활성화된 경우, 이인 모드의 왼쪽 또는 첫 번째 주제에 공급됩니다.
인물 번호 2#
대화를 만들 때 Load Reference Image (Person 2) (#9) 및 Load Reference Audio (Person 2) (#11)를 사용하세요. 인물 1의 구도와 일치하는 사진을 선택하여 구성을 균형 있게 유지하세요. 두 번째 오디오는 첫 번째와 비슷한 소음 수준이어야 갑작스러운 인지적 변화를 피할 수 있습니다. 단일 인물 클립만 만들고 있다면 이 그룹은 무시해도 됩니다.
1인 비디오#
단일 화자 경로는 ComfyUI DreamID-Omni Sampler (#21)에 의해 구동됩니다. DreamID-Omni 파이프라인을 인물 1의 사진과 오디오와 결합한 후 노드의 프롬프트 영역에서 간결한 장면 설명과 일관된 샷을 렌더링합니다. 배경, 카메라 거리 및 태도를 설명하는 등 프롬프트를 간결하고 실용적으로 유지하세요. 결과는 💾 Save Video (Single Person) (#4)에 의해 작성되며, 파일을 저장하고 내보냅니다.
2인 비디오#
대화 경로는 ComfyUI DreamID-Omni Sampler (#22)를 사용하여 한 프레임에 두 정체성을 구성하고 각 입을 쌍의 오디오로 구동합니다. 환경 및 상호작용 스타일을 설정하기 위해 짧은 프롬프트를 제공하세요. 예를 들어 협업 공간, 캐주얼한 톤, 누가 먼저 말하는지 등을 설정할 수 있습니다. 이는 카메라 위치와 제스처를 안정화하는 데 도움이 되며 DreamID-Omni와 MMAudio가 정체성과 입술 정렬을 유지합니다. 클립은 💾 Save Video (Two Persons) (#5)에 의해 내보내집니다.
공유 DreamID-Omni 파이프라인#
ComfyUI DreamID-Omni Loader (#23)는 두 경로에서 사용되는 DreamID-Omni 구성 요소를 초기화합니다. 일반적으로 여기서 조정할 필요는 없습니다. 가중치와 ComfyUI 노드가 사용 가능한 한, 로더는 샘플러가 렌더링할 수 있도록 파이프라인을 준비합니다.
Comfyui DreamID-Omni 워크플로우의 주요 노드#
ComfyUI DreamID-Omni Loader (#23)#
DreamID-Omni 파이프라인을 초기화하고 가중치를 다운스트림 샘플러에 사용할 수 있게 합니다. 여기에는 일반적인 사용자 입력이 없습니다. 여러 모델 변형을 유지하는 경우, 렌더링을 대기열에 넣기 전에 올바른 가중치가 설치되어 있는지 확인하세요.
ComfyUI DreamID-Omni Sampler (#21)#
단일 인물 렌더링. 이 노드는 로더 파이프라인과 첫 번째 참조 이미지 및 오디오를 결합하여 정체성을 유지하는 대화형 머리를 합성합니다. 프롬프트 필드는 장면과 태도를 정의하는 곳입니다; 시드는 반복 가능성을 제어합니다; 해상도는 구도 및 얼굴 세부 사항을 결정합니다; 단계는 속도를 정밀도로 교환합니다. 테이크 간 일관된 결과를 위해 동일한 시드를 재사용하고 프롬프트 변경을 최소화하세요.
ComfyUI DreamID-Omni Sampler (#22)#
이인 렌더링. 이 인스턴스는 두 사진과 두 오디오를 수락하여 각 목소리를 주제와 짝지어 동기화된 입 움직임을 제공합니다. 대화와 카메라 레이아웃을 설정하기 위해 프롬프트를 사용할 수 있습니다. 단일 인물 모드에서처럼 시드 및 해상도를 조정하고, 렌더링 전에 두 오디오가 원하는 타이밍에 맞도록 자르세요.
💾 Save Video (Single Person) (#4)#
단일 화자 출력을 디스크에 기록합니다. 버전을 정리하기 위해 폴더 또는 기본 이름을 설정하세요. 가능하면, 코덱 및 프레임 속도를 자동으로 둬서 확실성을 유지하세요.
💾 Save Video (Two Persons) (#5)#
대화 출력을 디스크에 기록합니다. 단일 및 이중 인물 클립을 쉽게 구분하기 위해 구별되는 기본 이름을 사용하세요. 특별한 전달 요구 사항이 없는 한 자동 내보내기 설정을 유지하여 신뢰성을 확보하세요.
선택적 추가 사항#
- 참조 이미지에서 얼굴이 프레임의 의미 있는 부분을 차지할 만큼 충분히 크게 유지하여 정체성 잠금을 강화하세요.
- 깨끗하고 잘 조정된 음성 오디오를 사용하세요. 초기 동결 입술을 피하기 위해 시작 부분의 침묵을 잘라내세요.
- 프롬프트나 의상을 반복할 때 동일한 시드를 재사용하여 더 안정적인 외관을 얻으세요.
- 이인 간격이 좁게 느껴지면 프롬프트를 재구성하여 카메라를 넓히거나 어깨 공간을 늘리세요. 얼굴을 자르지 마세요.
- 자산 및 업데이트에 대해서는 공식 모델 및 노드를 참조하세요: DreamID-Omni, ComfyUI_RH_Dreamid-Omni, 및 DreamID-Omni weights.
감사의 말#
이 워크플로우는 다음 작업 및 리소스를 구현하고 확장합니다. DreamID-Omni 모델/워크플로우를 제공한 Guoxu1233, DreamID-Omni ComfyUI 노드를 제공한 HM-RunningHub, DreamID-Omni 모델 가중치를 제공한 XuGuo699에게 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- DreamID-Omni 공식 저장소 - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- DreamID-Omni ComfyUI 노드 (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- DreamID-Omni 모델 가중치 (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
참고: 참조된 모델, 데이터셋 및 코드는 작성자 및 유지 관리자가 제공한 해당 라이선스 및 조건에 따릅니다.