
일관된 장면 생성 (Qwen Image Edit & Wan 2.2)#
일관된 장면 생성 (Qwen Image Edit & Wan 2.2)은 캐릭터, 조명 및 구성이 샷마다 일관되게 유지되는 스토리 중심의 다중 샷 비디오를 제작하기 위한 제작 준비가 된 ComfyUI 워크플로우입니다. Qwen Image Edit를 사용하여 정밀하고 참조 기반의 스틸을 생성하고, Wan 2.2 이미지‑투‑비디오를 사용하여 시네마틱 모션을 구현한 후, 장면을 연결하고 프레임 보간으로 모션을 부드럽게 하며 생성된 폴리 오디오를 추가하여 마무리합니다. 내러티브 아트, 애니메이션, 프리비즈 및 컨셉 릴에 이상적이며, 최소한의 수작업 수정으로 단일 설정 키프레임에서 일관된 시퀀스로 이동하는 데 도움을 줍니다.
파이프라인은 세 부분으로 구성됩니다: Part 1은 일관된 키프레임을 생성하고 편집하며, Part 2는 각 샷을 Wan 2.2로 애니메이션하고 하나의 컷으로 결합하며, Part 3은 장면 인식 폴리 오디오를 생성합니다. 이 README에서 "일관된 장면 생성 (Qwen Image Edit & Wan 2.2)"를 볼 때마다 전체 프로세스를 의미합니다.
Comfyui 일관된 장면 생성 (Qwen Image Edit & Wan 2.2) 워크플로우의 주요 모델#
- Wan 2.2 Image‑to‑Video 14B (고잡음 및 저잡음 변형). 공간 레이아웃과 스타일을 유지하면서 장면 이미지를 애니메이션하는 데 사용되는 핵심 비디오 생성기. ComfyUI용으로 텍스트 인코더 및 VAE 자산과 함께 패키징됨. 참조: Comfy‑Org/Wan_2.2_ComfyUI_Repackaged.
- Qwen‑Image‑Edit 2509 + Qwen 2.5 VL 텍스트 인코더 + Qwen Image VAE. 참조 인식 이미지 편집으로 다음 장면의 키프레임을 생성하여 내러티브를 유지하면서 캐릭터와 장면의 연속성을 유지합니다. 참조: Comfy‑Org/Qwen‑Image‑Edit_ComfyUI 및 Comfy‑Org/Qwen‑Image_ComfyUI.
- FLUX.1 dev (텍스트‑투‑이미지). 편집 전 첫 설정 키프레임을 위한 선택적 기초 모델. 참조: Comfy‑Org/FLUX.1‑Krea‑dev_ComfyUI.
- RIFE Video Frame Interpolation. 결합된 컷에서 프레임 속도를 높이고 모션을 부드럽게 하는 데 사용됩니다. 참조: hzwer/Practical‑RIFE.
- HunyuanVideo‑Foley. 이미지나 비디오 및 짧은 텍스트 큐에서 동기화된 폴리를 생성하는 생성 오디오 모델로, 각 장면이나 최종 컷에 다이제틱 사운드를 추가하는 데 사용됩니다. 참조: phazei/HunyuanVideo‑Foley.
- 선택적 도우미. MiniCPM‑V 4.5는 컷에서 오디오 프롬프트를 자동 초안하여 폴리 아이데이션을 가속화할 수 있습니다: OpenBMB/MiniCPM‑V.
Comfyui 일관된 장면 생성 (Qwen Image Edit & Wan 2.2) 워크플로우 사용 방법#
전체 논리
- Part 1은 설정 키프레임을 생성한 후 Qwen Image Edit를 사용하여 스타일적으로 정렬된 "다음 장면" 스틸을 생성합니다.
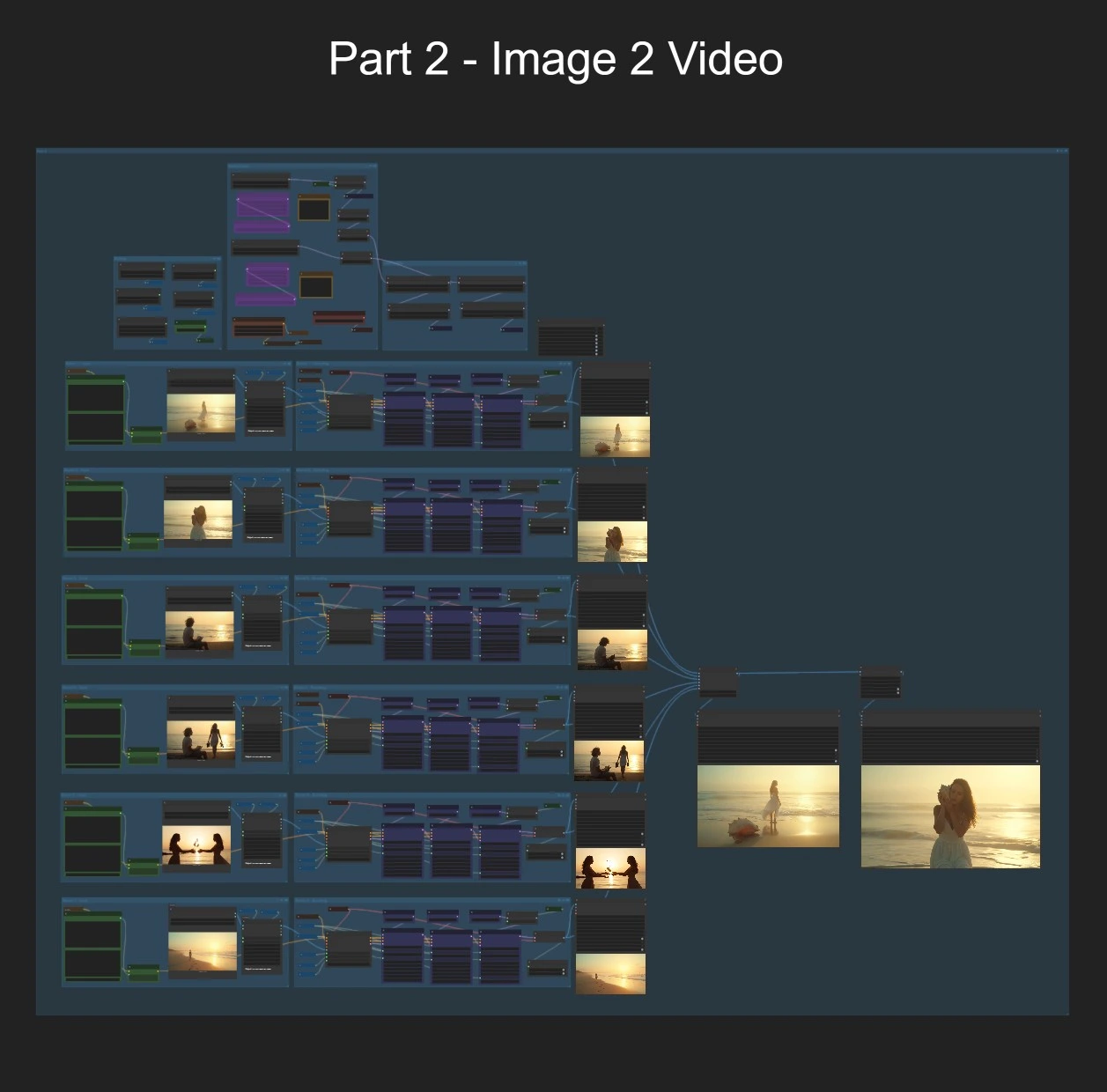
- Part 2는 각 장면 이미지를 Wan 2.2로 짧은 클립으로 애니메이션한 다음 모든 클립을 하나의 컷으로 결합하고, 선택적으로 프레임을 보간하여 부드러운 모션을 만듭니다.
- Part 3은 선택적으로 각 장면이나 결합된 컷에 폴리 오디오를 생성하고 최종 비디오에 믹스합니다.
모델 로더
- 모델 영역은 Wan 2.2 고잡음 및 저잡음 변형과 그 VAE/CLIP을 한 번 로드하며, torch 컴파일을 통해 가속화 옵션이 있습니다. VRAM이 적은 GPU에서도 동일한 일관된 장면 생성 (Qwen Image Edit & Wan 2.2) 프로세스를 실행할 수 있도록 양자화된 GGUF UNETs와 블록 스왑을 사용하는 저VRAM 경로도 제공합니다.
- Wan 2.2 및 Qwen Image Edit Lightning LoRA의 LoRAs는 모션 스타일과 편집 속도에 영향을 미치도록 사전 연결되어 있으며 그래프를 복잡하게 만들지 않습니다.
- 모델을 변경할 경우, 잠재 공간 불일치를 피하기 위해 텍스트 인코더/UNET/VAE 계열을 일관되게 유지하십시오.
설정
- 글로벌 컨트롤은 작업 폭, 높이, 씨드 및 장면 길이를 설정하여 모든 장면이 동일한 캔버스 기하학과 시간적 리듬을 상속하도록 합니다. 이는 일관된 장면 생성 (Qwen Image Edit & Wan 2.2) 일관성의 핵심입니다.
- 포괄적인 네거티브 프롬프트가 제공되며 전역적으로 라우팅됩니다; 아트 방향에 맞게 언제든지 재정의할 수 있습니다.
Part 1 — 텍스트‑투‑이미지 설정 키프레임
- 오프닝 샷을 설명하는 것으로 시작하십시오. 프롬프트는 프로젝트를 위한 "Start_" 프레임을 출력하는 기본 텍스트‑투‑이미지 샘플러에 공급됩니다.
- 그 이미지는 캐시되며 Qwen 트랙에서 다음 장면의 참조가 됩니다. 워크플로우는 이미지를 편집 친화적인 해상도로 확장하고 잠재에 인코딩합니다.
Part 1 — Qwen Image Edit 다음 장면 키프레임
- 각 후속 샷에 대해 짧은 "다음 장면" 지시를 작성하십시오. 편집기는 이전 장면 이미지에 조건을 걸어 캐릭터 정체성, 의상, 조명 및 팔레트를 일관되게 유지합니다.
- 편집 결과는 디코딩되어 미리보기되고 "Scene_1_…", "Scene_2_…" 등으로 저장됩니다. 이것들이 당신의 일관된 스틸입니다. 또한 나중에 프롬프트에서 참조할 수 있도록 공유 이미지 슬롯에 저장됩니다.
장면 입력 (1–6)
- 이미 컨셉 프레임이 있는 경우, 여섯 개의 "LoadImage" 노드에 넣으십시오. 그렇지 않으면 Part 1에서 생성된 Qwen 스틸을 시작 이미지로 사용하십시오.
- 각 장면마다 레이블이 붙은 프롬프트 노드를 통해 짧은 텍스트 프롬프트를 추가하십시오. 이를 전체 환경을 재설명하기보다는 모션 스타일을 안내하는 촬영 노트로 생각하십시오.
장면 샘플링 (1–6)
- 각 장면은 시작 이미지를 잠재 클립으로 변환하기 위해 Wan 2.2 이미지‑투‑비디오 패스를 실행합니다. 세 단계 샘플러 경로가 고잡음 경로, 저잡음 경로 및 안정성을 위한 No‑LoRA 경로를 사용하여 잠재 시퀀스를 정제합니다.
- 디코딩된 프레임은 각 장면 비디오 작성기에 피드되어 빠른 검토를 위한 MP4로 저장됩니다. 각 렌더링 후 메모리 정리 노드가 다음 장면이 시작되기 전에 VRAM을 해제합니다.
- 모든 장면이 동일한 씨드, 크기 및 길이를 공유하기 때문에 모션 리듬과 구성이 일관되게 유지되어 일관된 장면 생성 (Qwen Image Edit & Wan 2.2)이 하나의 연속적인 작품처럼 느껴집니다.
장면 결합
- 렌더링된 6개의 이미지 시퀀스가 순서대로 연결되어 "Combined" 컷을 생성합니다. 배치 노드를 재배선하여 장면을 재정렬하거나 생략할 수 있습니다.
선택적 프레임 보간
- 보간 패스는 RIFE를 사용하여 겉보기 프레임 속도를 증가시킵니다. 이는 카메라와 피사체 모션을 부드럽게 하며 동일한 외관을 유지합니다.
Part 3 — 비디오‑투‑오디오 폴리
- 오디오 섹션에 결합된 컷 또는 개별 장면을 로드하십시오. 내장된 비전‑언어 도우미가 텍스트 장면 설명을 자동 초안할 수 있으며, 리듬, 분위기 및 주요 동작을 반영하도록 편집할 수 있습니다.
- 폴리 모델은 동기화된 오디오를 합성하고 믹스 노드는 프레임과 결합하여 오디오가 포함된 MP4를 생성합니다. 최상의 결과를 위해 각 장면에 대해 오디오를 생성한 후 스티칭하십시오.
Comfyui 일관된 장면 생성 (Qwen Image Edit & Wan 2.2) 워크플로우의 주요 노드#
WanImageToVideo(#111) 단일 참조 프레임을 일관된 잠재 비디오로 변환하며 긍정적 및 부정적 텍스트를 존중합니다. 각 샷의 지속 시간과 캔버스 크기를 설정하고 애니메이션할 시작 이미지를 공급하는 데 사용됩니다. Wan 2.2 I2V 14B 모델이 백업하며 여기에서 패키징됨: Comfy‑Org/Wan_2.2_ComfyUI_Repackaged.TextEncodeQwenImageEditPlus(#360) "다음 장면" 지시를 참조 이미지와 함께 인코딩하여 편집이 스토리를 따르면서도 정체성과 조명을 일치시킵니다. 명사와 스타일 태그를 장면 간 일관되게 유지하여 연속성을 강화하십시오. 모델 참조: Comfy‑Org/Qwen‑Image‑Edit_ComfyUI 및 Comfy‑Org/Qwen‑Image_ComfyUI.KSamplerAdvanced(#159) 각 애니메이션 장면의 핵심 디노이저. 이 워크플로우는 서로 다른 잡음 체제와 LoRA 혼합을 타겟으로 하는 세 개의 샘플러를 연결하여 시간적 안정성을 향상시킵니다. 스텝이나 씨드를 변경할 경우, 체인 샘플러 전반에 걸쳐 균일하게 수행하여 모션 동작을 예측 가능하게 유지하십시오.ImageBatchMulti(#308) 장면 프레임 배치를 하나의 긴 타임라인으로 모읍니다. 내보내기 전에 샘플링 경로를 건드리지 않고 장면을 재정렬, 삭제 또는 교환하는 데 사용하십시오.RIFE VFI(#94) 프레임 보간을 수행하여 인지되는 프레임 속도를 증가시킵니다. 특히 느린 카메라 이동과 부드러운 피사체 모션에 효과적입니다. 참조: hzwer/Practical‑RIFE.HunyuanFoleySampler(#331) 프레임과 짧은 텍스트 프롬프트에서 동기화된 폴리를 생성한 후 오디오를 비디오 믹서로 전달합니다. 모델 세부 정보 및 파일은 phazei/HunyuanVideo‑Foley를 참조하십시오.
선택적 추가 기능#
- 가장 빠른 반복을 위해 VRAM이 부족할 때는 양자화된 GGUF Wan 2.2 경로와 블록 스왑을 사용하십시오; 최종 렌더링을 위해 전체 정밀도로 다시 전환하십시오.
- 프로젝트 전체에 걸쳐 폭, 높이 및 장면 길이를 동일하게 유지하여 리듬과 프레이밍 연속성을 강화하십시오.
- Qwen 프롬프트에서 핵심 식별자(이름, 의상, 소품) 및 조명 용어를 보존하십시오; 장면 간 액션과 카메라 언어만 다양화하십시오.
- 프로젝트의 전반적인 "느낌"을 고정하기 위해 글로벌 씨드를 사용하십시오. 모든 장면에 걸쳐 다른 모션 캐릭터를 원할 때만 변경하십시오.
- 타이밍에 만족한 후에만 보간하고, 각 장면에 대해 오디오 버전을 렌더링한 후 결합하십시오; 장면별 폴리가 더 자연스럽게 들리는 경향이 있습니다.
- FLUX.1 dev는 첫 번째 키프레임의 좋은 기초입니다; 설정이 완료되면 Qwen 편집을 통해 스토리를 진행하면서 외관을 유지하십시오: Comfy‑Org/FLUX.1‑Krea‑dev_ComfyUI.
감사#
이 워크플로우는 다음 작업 및 리소스를 구현하고 이를 기반으로 구축합니다. 우리는 모델을 위한 Qwen Image Edit의 제작자, 모델을 위한 Wan 2.2의 개발자, 그리고 "일관된 장면 생성 (Qwen Image Edit & Wan 2.2) Youtube Tutorial"의 저자(@Benji’s AI Playground)에게 그들의 기여와 유지보수에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- YouTube/Create Coherent Scenes (Qwen Image Edit & Wan 2.2)
- 문서 / 릴리스 노트 @Benji’s AI Playground: Create Coherent Scenes (Qwen Image Edit & Wan 2.2) Youtube Tutorial
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지보수자가 제공한 라이선스 및 조건에 따릅니다.
