
ComfyUI MOSS TTS: 텍스트-음성 변환, 음성 클로닝, SFX, 대화를 하나의 워크플로우로#
이 ComfyUI MOSS TTS 워크플로우는 OpenMOSS MOSS-TTS 패밀리를 사용하여 텍스트를 생생한 24 kHz 음성으로 변환합니다. 빠른 단일 화자 합성, 짧은 참조 클립에서의 제로샷 음성 클로닝, 서술적 음성 설계, 절차적 사운드 효과 및 선택적 화자별 참조가 포함된 다화자 대화를 다룹니다.
공식 MOSS-TTS 노드 스택 및 모델 패밀리를 기반으로 하여 속도와 품질의 균형을 맞춥니다. Local 1.7B 경로는 단일 GPU에서의 실용적인 빠른 경로이며, 더 큰 Delay 8B 모델은 속도를 희생하여 더 넓은 기능과 표현력을 제공합니다. 재사용 가능한 프롬프트, 클론된 음성 또는 ComfyUI 내부의 대화가 필요하다면 이 ComfyUI MOSS TTS 워크플로우가 설계되었습니다.
Comfyui ComfyUI MOSS TTS 워크플로우의 주요 모델#
- OpenMOSS MOSS-TTS Local 1.7B. 일상적인 제작 작업을 위한 빠르고 자연스러운 24 kHz 음성을 제공하는 단일 GPU 친화적 텍스트-음성 변환기. 모델 카드: MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. 속도와 메모리를 희생하고 품질, 화자 유사성 및 운율을 중시하는 더 큰 모델 라인. 모델 카드: MOSS-TTS.
- MOSS Audio Tokenizer. MOSS-TTS 모델용 파형과 이산 토큰을 연결하는 학습된 코덱으로 고품질 디코딩을 가능하게 합니다. 모델 카드: MOSS-Audio-Tokenizer.
구현 세부 정보 및 업데이트는 공식 리포지토리를 참조하세요: OpenMOSS/MOSS-TTS 및 이 워크플로우를 구동하는 노드 스택 richservo/comfyui-moss-tts.
Comfyui ComfyUI MOSS TTS 워크플로우 사용 방법#
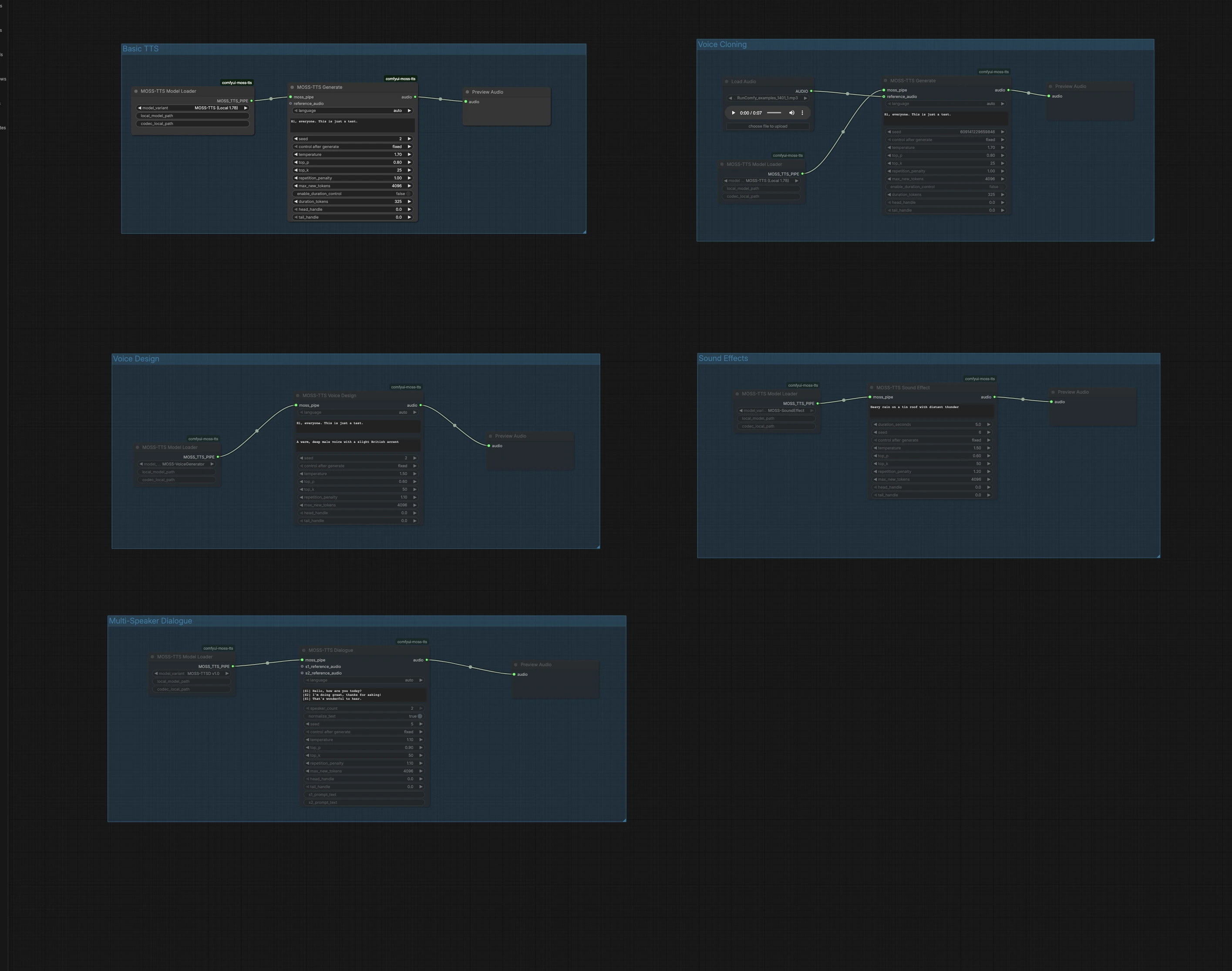
이 그래프는 다섯 개의 독립적인 그룹으로 구성되어 있습니다. 목표에 맞는 그룹을 선택하여 실행한 다음 캔버스에서 오디오를 미리 봅니다. 여러 그룹을 병렬로 실행하여 다양한 접근 방식을 시도할 수 있습니다.
기본 TTS#
기본 TTS 그룹은 Local 1.7B 빠른 경로를 사용하여 일반 텍스트를 음성으로 변환합니다. MossTTSModelLoader (#1)에서 모델을 로드하고, MossTTSGenerate (#2)에 텍스트를 입력한 후 PreviewAudio (#3)에서 들어봅니다. 생성기는 프롬프트에 따라 발음과 운율을 조정하므로, 속도를 위해 자연스럽게 문장 부호를 사용하여 작성하세요. 반복 가능한 테이크를 원할 때는 시드를 고정하고, 전달 변형을 탐색할 때는 무작위로 설정하세요.
음성 클로닝#
음성 클로닝 그룹은 짧은 참조 오디오 클립에서 제로샷 음성 클로닝을 수행합니다. LoadAudio (#4)를 사용하여 깨끗한 음성 샘플을 가져오고, MossTTSModelLoader (#5)에 의해 구동되는 MossTTSGenerate (#6)에 연결한 후 목표 텍스트를 제공합니다. 모델은 참조에서 화자 음색과 스타일을 추출하고 그 음성으로 새 스크립트를 렌더링합니다. 유사성을 개선하려면 중립적인 콘텐츠와 최소한의 배경 소음을 참조로 사용하고, 가장 빠른 결과를 위해 지속 시간을 적당히 유지하세요.
음성 디자인#
음성 디자인은 예시 클립 대신 자연 언어 설명에서 새로운 음성을 만듭니다. MossTTSVoiceDesign (#9)은 "따뜻하고 깊은 남성 목소리, 약간의 영국식 억양"과 같은 텍스트 설명과 스크립트를 결합하여 24 kHz 음성을 합성합니다. 노드는 MossTTSModelLoader (#8)를 통해 로드된 전용 음성 생성 경로에 의해 구동됩니다. 실제 녹음을 소싱하는 것이 실용적이지 않을 때 일관되고 재현 가능한 페르소나를 원할 때 이상적입니다. 소리를 조정하기 위해 나이, 음색, 억양 및 에너지와 같은 특성으로 설명을 세밀하게 조정하세요.
사운드 효과#
사운드 효과는 텍스트 프롬프트에서 비언어적 오디오를 생성하여 배경 트랙, 전환 또는 환경 레이어에 유용합니다. MossTTSSoundEffect (#12)와 MossTTSModelLoader (#11)에서 모델 파이프를 사용하여 "멀리서 들리는 천둥과 함께 양철 지붕 위에 내리는 폭우"와 같은 프롬프트로 풍부하고 반복 가능한 텍스처를 생성합니다. 장면을 정의하기 위해 간결한 명사와 동작을 사용한 다음, 강도나 거리를 정확히 맞추기 위해 몇 가지 형용사를 추가하세요. PreviewAudio (#13)에서 미리 보고 믹스에 맞게 빠르게 반복하세요.
다화자 대화#
다화자 대화 그룹은 선택적 화자별 참조 클립이 있는 스크립트 대화를 렌더링합니다. 예를 들어 [S1] 안녕하세요. 및 [S2] 안녕!과 같은 대괄호로 묶인 화자 태그를 사용하여 스크립트를 작성한 다음 MossTTSDialogue (#15)에 MossTTSModelLoader (#14)에서 모델 파이프를 통해 전달합니다. 각 역할에 대해 특정 음성을 클론하기 위해 S1 및 S2에 참조 오디오 입력을 연결하거나, 텍스트 컨텍스트에서 모델이 고유한 화자를 선택하도록 비워둘 수 있습니다. 콜 앤 리스폰스, 캐릭터 대사의 내레이션 또는 음성 UI 목업에 적합합니다.
Comfyui ComfyUI MOSS TTS 워크플로우의 주요 노드#
MossTTSModelLoader (#1)#
선택한 OpenMOSS 모델 패밀리를 로드하고 내부 TTS 파이프라인을 구성합니다. 단일 GPU에서 빠른 반복을 위해 Local 1.7B 변형을 선택하거나, 표현력과 유사성을 중시할 때 더 큰 Delay 8B 모델로 전환하세요. 각 작업 패밀리에 하나의 로더를 유지하여 각 하위 브랜치가 독립적으로 유지되도록 합니다.
MossTTSGenerate (#2)#
텍스트 프롬프트와 선택적 참조 오디오를 소비하여 24 kHz 음성을 생성하는 주요 단일 화자 합성기입니다. 명확한 속도를 위해 깨끗하고 잘 구두점이 찍힌 텍스트를 제공하고, 제로샷 클로닝이 필요할 때 짧은 음성 클립을 연결하세요. 재현성과 탐색의 균형을 맞추기 위해 시드 설정을 고정과 무작위로 전환하세요.
MossTTSVoiceDesign (#9)#
설명적 프롬프트와 함께 말할 텍스트에서 새로운 음성을 생성합니다. 음색, 나이, 억양 및 에너지를 설명에 집중하여 정체성을 조정하면서 간결하게 유지하세요. 실제 음성을 라이선싱하거나 소싱하는 것이 실용적이지 않을 때 강력한 선택입니다.
MossTTSSoundEffect (#12)#
짧은 텍스트 설명에서 비언어적 오디오를 합성합니다. 소스, 동작 및 공간을 고정하는 간결한 프롬프트를 작성한 다음 장면에 맞추기 위해 반복하세요. 대화에 사용한 ComfyUI MOSS TTS 그래프 내에서 환경 및 단발에 적합합니다.
MossTTSDialogue (#15)#
대괄호로 묶인 화자 태그를 구문 분석하고 멀티 턴 대화를 단일 오디오 출력으로 렌더링합니다. 각 줄을 표시하기 위해 [S1], [S2] 등을 사용하고, 각 턴에서 정체성을 유지하기 위해 선택적으로 화자별 참조 클립을 연결하세요. 화자 간의 가장 신뢰할 수 있는 전달을 위해 줄을 간결하게 유지하세요.
선택적 추가#
- 빠른 초안 작성을 위해 Local 1.7B 모델로 시작한 후, 더 강한 유사성 또는 풍부한 운율이 필요할 때 Delay 8B 체크포인트로 전환하세요.
- 제로샷 클로닝의 경우, 최소한의 리버브와 소음이 있는 깨끗한 5–15초 음성 클립을 사용하여 음색 전송을 개선하세요.
- 대화에서는
[S1]과 같이 화자 태그를 일관되고 구두점 없이 유지하여 구문 분석 오류를 피하세요. - 예측 가능한 결과를 위해 3–6가지 특성(음색, 나이, 억양, 스타일, 에너지)으로 음성 디자인 프롬프트를 제작하세요.
- ComfyUI MOSS TTS 출력에서 일시 정지와 속도를 제어하기 위해 텍스트에 구두점과 줄 바꿈을 사용하세요.
- 배치 렌더링을 위한 자동 파일 내보내기가 필요할 경우, 미리 보기 후
SaveAudio노드를 추가하세요.
참조: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
감사의 말#
이 워크플로우는 다음의 작업 및 리소스에 대한 구현 및 확장을 포함합니다. ComfyUI MOSS-TTS 커스텀 노드를 제공한 richservo, MOSS-TTS 리포지토리를 제공한 OpenMOSS, MOSS-TTS 모델 (Delay 8B 및 Local 1.7B)과 MOSS Audio Tokenizer를 제공한 OpenMOSS-Team의 기여 및 유지 관리에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 리포지토리를 참조하세요.
리소스#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
참고: 참조된 모델, 데이터 세트 및 코드는 저자 및 유지 관리자가 제공하는 해당 라이선스 및 조건에 따라 사용해야 합니다.