
Stable Audio Open 1.0 テキストから音楽へのワークフロー#
このワークフローは、Stable Audio Open 1.0を使用してプレーンテキストを独自の音楽やサウンドスケープに変換します。作曲家やサウンドデザイナー、クリエイターがComfyUIを離れることなく、迅速で制御可能なオーディオ生成を望む場合に設計されています。プロンプトを書き、目標の持続時間を設定し、グラフがスタイル、ムード、テンポ、楽器編成を反映したMP3をレンダリングします。
内部では、ワークフローがT5ベースのテキストエンコーダーでテキストをエンコードし、Stable Audioの拡散プロセスを潜在オーディオ空間で実行し、波形にデコードして結果を保存します。明確なプロンプトガイダンスとシンプルな長さ制御により、Stable Audio生成はシネマティック、アンビエント、または実験的なトラックに対して予測可能で反復可能になります。
Comfyui Stable Audioワークフローの主要なモデル#
- Stable Audio Open 1.0。Stability AIによるテキストから音楽およびサウンドデザイン用のオープンウェイト潜在拡散モデル。テキストの意図をオーディオラテントにマッピングし、多様な音楽スタイルと構造をサポートします。Repository • Weights
- T5-Base Text Encoder。ここで使用される一般用途のテキストモデルで、Stable Audio生成のコンディショニングのためにプロンプトを埋め込みます。明確で記述的な入力はより一貫した音楽を導きます。Model card
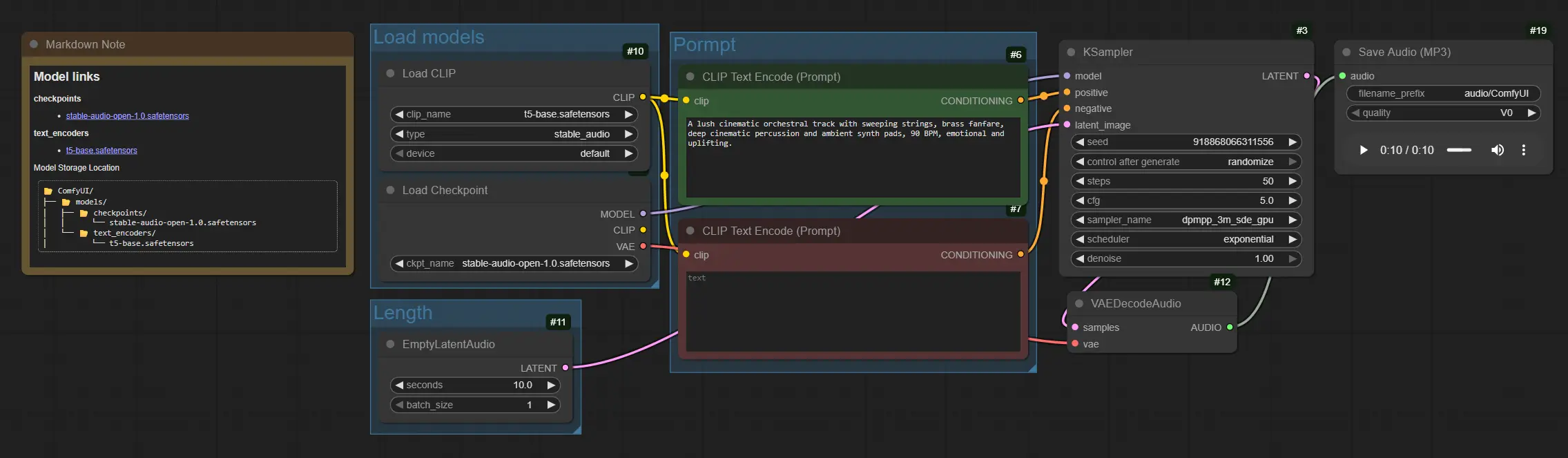
Comfyui Stable Audioワークフローの使用方法#
グラフはモデルのロードからプロンプトのコンディショニング、サンプリング、デコード、保存へと流れます。グループはモデルを一度設定し、長さを調整し、プロンプトを書いてレンダリングできるように整理されています。
モデルをロード#
このグループはコア資産を初期化します。CheckpointLoaderSimple (#4)はStable Audio Open 1.0チェックポイントをロードし、拡散モデルとそのオーディオVAEを含みます。CLIPLoader (#10)はコンディショニングに使用されるT5ベースのテキストエンコーダーをロードします。ロードされると、これらのモデルはStable Audio生成のバックボーンを提供し、後続の実行に常駐します。
長さ#
このグループはオーディオの長さを定義します。EmptyLatentAudio (#11)は選択した持続時間で空の潜在トラックを作成し、サンプラーが生成するフレーム数を知ることができます。長いクリップはより多くの時間とメモリを消費するため、控えめに開始してからスケールアップします。アイデアを探索する際にバッチ次元を増やすことで複数のバリエーションを生成することもできます。
プロンプト#
このグループはテキストを拡散プロセスのガイダンスシグナルに変換します。CLIPTextEncode (#6)を使用して、楽器、ジャンル、ムード、テンポ、プロダクションのヒントを含むポジティブプロンプトを書きます。例えば:「豪華なシネマティックオーケストラ、広がるストリングスとブラス、深いパーカッション、アンビエントパッド、90 BPM、心を揺さぶる」。CLIPTextEncode (#7)を使用して「厳しいノイズ、クリッピング、歪み」などのアーティファクトを抑制するネガティブプロンプトを書きます。これらを組み合わせて、希望するテクスチャや構造にStable Audioを導きます。
生成とエクスポート#
KSampler (#3)は、テキストエンコーディングによって導かれた音楽ラテントへの変換を行う拡散ステップを実行します。VAEDecodeAudio (#12)はラテントオーディオを波形に変換します。最後にSaveAudioMP3 (#19)がMP3ファイルを書き出し、レビューまたはタイムラインに直接ドロップできます。反復作業のために、ファイル名のプレフィックスを調整してテイクを整理します。
Comfyui Stable Audioワークフローの主要ノード#
CLIPTextEncode(#6) このノードは、Stable Audioが従うコンディショニングにポジティブプロンプトをエンコードします。明確な楽器リスト、ジャンル、ムード、テンポまたはBPM、プロダクション用語「暖かい」、「ローファイ」、「シネマティック」、「アンビエント」などを優先してください。微妙な表現の違いが作曲を大きく変えることがあります。一般的な動作はComfyUIのコアノードを参照してください。ComfyUICLIPTextEncode(#7) ネガティブプロンプトは不要な音色やミックスの問題を回避するのに役立ちます。例えば「キーキー音、金属的な鳴り、グリッチポップ、ラジオのヒス音」を取り除くための用語を追加します。これを簡潔に保つことで、よりクリーンなStable Audioのレンダリングを得ることができます。ComfyUIEmptyLatentAudio(#11) 秒単位でクリップの持続時間、オプションでバッチ数を制御します。秒数を増やして長い作品を作成し、長さに応じて計算が拡張されることに注意してください。バッチ生成を使用して単一のプロンプトから複数のStable Audioテイクを試聴します。ComfyUIKSampler(#3) オーディオラテントの拡散プロセスを駆動します。最も影響力のあるコントロールはsteps、sampler、cfg、seedです。stepsを増やして詳細を洗練し、cfgを調整してプロンプトへの適合性と創造性をバランスさせ、固定seedを設定してテイクを再現するか、新しいアイデアのために変化させます。一般的なガイダンスはComfyUIのサンプラーノートを参照してください。ComfyUISaveAudioMP3(#19) 最終波形をMP3にエクスポートします。filename_prefixを使用してバージョンをラベル付けし、反復を整理します。プロンプトやシードを比較する際、複数のテイクを並べて保存することでStable Audioの選択が速くなります。ComfyUI
オプションの追加#
- セッションブリーフのようにプロンプトを書く:楽器、ジャンル、ムード、テンポまたはBPM、ミックスの形容詞。
- 短く、焦点を絞ったネガティブプロンプトを使用して、ヒス音、厳しさ、不要な楽器を減らします。
- テキストを繰り返しながら
seedをロックし、その後seedを変更して新しいStable Audioのバリエーションを探索します。 - スタイルを調整するために短い持続時間で始め、サウンドが適切になったら長くします。
- コンセプトごとに一貫したファイル名プレフィックスを保持し、後でStable AudioテイクをA/B比較できるようにします。
より深い読み物のためのリソース:Stable Audioモデルの詳細と例こちら、ComfyUIのコアとノードの動作こちら、およびT5-Baseモデルカードこちら。
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。Stable Audio OpenのためのStability AI、ComfyUIノードとワークフローレファレンスのためのcomfyanonymous (ComfyUI)、およびStable Audio Open 1.0チェックポイントとT5-BaseテキストエンコーダーのためのComfy-OrgとComfyUI-Wikiの貢献と維持に感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Comfy-Org/Stable Audio Open 1.0 ワークフロー
- GitHub: Stability-AI/stable-audio-open
注:参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されるライセンスおよび条件に従います。