






Nunchaku Qwen Image マルチイメージ編集と合成用 ComfyUI#
Nunchaku Qwen Imageは、ComfyUI用のプロンプト駆動のマルチイメージ編集と合成ワークフローです。最大3つの参照画像を受け入れ、それらがどのようにブレンドまたは変換されるべきかを指定し、自然言語によって導かれる統一された結果を生成します。典型的な使用例には、被写体のマージ、背景の置換、またはある画像から別の画像へのスタイルやディテールの転送が含まれます。
Qwenイメージファミリーを基に構築されたこのワークフローは、アーティスト、デザイナー、クリエイターに正確なコントロールを提供しながら、迅速かつ予測可能です。また、シングルイメージ編集ルートとピュアテキストからイメージへのルートも含まれているため、1つのNunchaku Qwen Imageパイプライン内で生成、洗練、合成が可能です。
注: Mediumから2XLargeの範囲内のマシンタイプを選択してください。2XLarge Plusまたは3XLargeマシンタイプの使用はサポートされておらず、実行に失敗します。
ComfyUI Nunchaku Qwen Imageワークフローの主要モデル#
- Nunchaku Qwen Image Edit 2509. プロンプトに基づく画像編集と属性転送に最適化された編集調整拡散/DiTウェイト。ローカライズされた編集、オブジェクトの交換、背景の変更に優れています。 モデルカード
- Nunchaku Qwen Image (base). ソース写真なしでクリエイティブな合成を行うためのテキストからイメージへのブランチで使用されるベースジェネレーター。 モデルカード
- Qwen2.5‑VL 7B テキストエンコーダー。プロンプトを解釈し、視覚的特徴と一致させるマルチモーダル言語モデル。 モデルページ
- Qwen Image VAE. ソース画像を潜在にエンコードし、忠実な色とディテールで最終結果をデコードするために使用される変分オートエンコーダー。 アセット
ComfyUI Nunchaku Qwen Imageワークフローの使用方法#
このグラフには、同じ視覚言語とサンプリングロジックを共有する3つの独立したルートが含まれています。複数画像の編集、単一画像の洗練、またはテキストからの生成のいずれかに応じて1つのブランチを使用します。
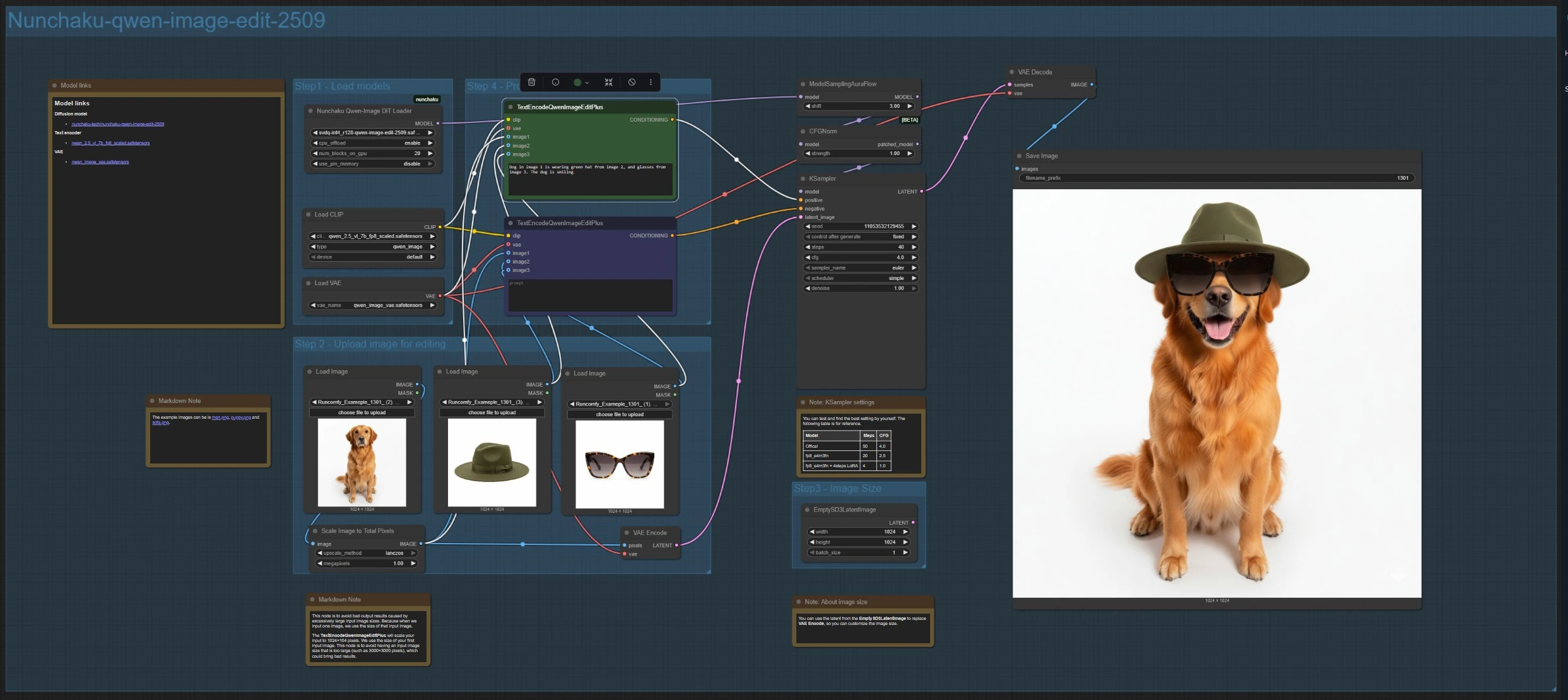
Nunchaku-qwen-image-edit-2509 (マルチイメージ編集と合成)#
このブランチは、NunchakuQwenImageDiTLoader (#115)で編集モデルをロードし、ModelSamplingAuraFlow (#66)とCFGNorm (#75)を通してルーティングし、KSampler (#3)で合成します。LoadImage (#78, #106, #108)を使用して最大3つの画像をアップロードします。メイン参照はVAEEncode (#88)でエンコードされてキャンバスを設定し、ImageScaleToTotalPixels (#93)で入力を安定したサイズ範囲内に保ちます。
指示をTextEncodeQwenImageEditPlus (#111)に書き込み、必要に応じて削除や制約をペアのTextEncodeQwenImageEditPlus (#110)に配置します。たとえば、「画像1の犬が画像2の緑の帽子と画像3の眼鏡をかけている」といった具合にソースを明示的に参照してください。カスタム出力サイズが必要な場合は、エンコードされた潜在をEmptySD3LatentImage (#112)に置き換えることができます。結果はVAEDecode (#8)でデコードされ、SaveImage (#60)で保存されます。
Nunchaku-qwen-image-edit (単一画像の洗練)#
1つの画像にターゲットを絞ったクリーンアップ、背景変更、またはスタイル調整を行いたい場合に選択します。モデルはNunchakuQwenImageDiTLoader (#120)でロードされ、ModelSamplingAuraFlow (#125)とCFGNorm (#123)で調整され、KSampler (#127)でサンプリングされます。LoadImage (#129)で写真をインポートし、ImageScaleToTotalPixels (#130)で正規化され、VAEEncode (#131)でエンコードされます。
指示をTextEncodeQwenImageEdit (#121)に提供し、要素の保持または削除のためにオプションのカウンターガイダンスをTextEncodeQwenImageEdit (#122)に提供します。ブランチはVAEDecode (#124)でデコードされ、SaveImage (#128)でファイルを書き込みます。
Nunchaku-qwen-image (テキストから画像へ)#
ベースモデルを使用してゼロから新しい画像を作成するためにこのブランチを使用します。NunchakuQwenImageDiTLoader (#146)がModelSamplingAuraFlow (#138)を供給します。CLIPTextEncode (#143)とCLIPTextEncode (#137)にポジティブおよびネガティブのプロンプトを入力します。EmptySD3LatentImage (#136)でキャンバスを設定し、KSampler (#141)で生成し、VAEDecode (#142)でデコードし、SaveImage (#147)で保存します。
ComfyUI Nunchaku Qwen Imageワークフローの主要ノード#
NunchakuQwenImageDiTLoader (#115) ブランチで使用されるQwenイメージウェイトとバリアントをロードします。写真ガイド付き編集には編集モデルを、テキストから画像への合成にはベースモデルを選択します。VRAMが許す場合、高精度または高解像度のバリアントがより詳細な結果をもたらすことがあります。軽量バリアントはスピードを優先します。
TextEncodeQwenImageEditPlus (#111) 指示を解析し、最大3つの参照にバインドすることでマルチイメージ編集を駆動します。どの画像がどの属性を提供するかを明示的に指示してください。簡潔な表現を使用し、矛盾する目標を避けて編集を集中させます。
TextEncodeQwenImageEditPlus (#110) マルチイメージブランチのペアのネガティブまたは制約エンコーダーとして機能します。表示したくないオブジェクト、スタイル、またはアーティファクトを除外するために使用します。これにより、UIオーバーレイや不要なプロップを削除しながら構成を保持するのに役立ちます。
TextEncodeQwenImageEdit (#121) 単一画像編集ブランチのポジティブ指示。希望する結果、表面の質、構成を明確に記述します。シーンと変更を指定する1~3文を目指します。
TextEncodeQwenImageEdit (#122) 単一画像編集ブランチのネガティブまたは制約プロンプト。避けるべき項目や特徴をリストするか、ソース画像から削除する要素を記述します。これは、迷子のテキスト、ロゴ、またはインターフェース要素をクリーンアップするのに便利です。
ImageScaleToTotalPixels (#93) 過剰な入力が結果を不安定にしないように、目標とする総画素数にスケーリングします。合成前に異なるソース解像度を調和させるために使用します。ソース間でシャープネスが不一致の場合、ここで効果的なサイズを近づけます。
ModelSamplingAuraFlow (#66) Qwenイメージモデルに調整されたDiT/フローマッチングサンプリングスケジュールを適用します。出力が暗く、ぼやけて、構造がない場合は、スケジュールのシフトを増やしてグローバルトーンを安定させます。平坦に見える場合は、シフトを減らして詳細を追求します。
KSampler (#3) スピード、忠実度、確率的多様性をバランスさせるメインサンプラーです。ステップとガイダンススケールを調整して、一貫性と創造性を比較し、サンプラーメソッドを選択し、正確な再現性を望む場合はシードを固定します。
CFGNorm (#75) 高いガイダンススケールで飽和度過剰やコントラストの爆発を防ぐために、分類器フリーガイダンスを正規化します。提供されたパスにそのまま残してください。プロンプトの反復中に安定した色と露出を維持するのに役立ちます。
オプションのエクストラ#
- 最良のマルチイメージ結果を得るには、類似の視点と照明のソースを選択してください。Nunchaku Qwen Image編集モデルは、その場合、ジオメトリの修正ではなくコンテンツに集中します。
- ソースを順番で参照し("画像1"、"画像2"、"画像3")、どの属性がどこに転送されるかを明確に指示してください。
- 出力が暗くぼやけている場合は、
ModelSamplingAuraFlowシフトを上げ、追加のテクスチャを望む場合は、少し低いシフトを試してください。 - 特定の解像度を設定するには、使用しているブランチでエンコードされた潜在を
EmptySD3LatentImageに交換します。 - 詳細なスタイリングに投資する前に、UIテキスト、透かし、不要なオブジェクトをネガティブプロンプトで削除してください。これにより、Nunchaku Qwen Image編集が最初からクリーンになります。
謝辞#
このワークフローは、以下の作品とリソースを実装し、それに基づいて構築されています。Nunchakuに感謝し、Qwen-Imageワークフロー(ComfyUI-nunchaku)への貢献とメンテナンスに感謝します。権威ある詳細については、以下のリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナによって提供されたライセンスおよび条件に従います。



