
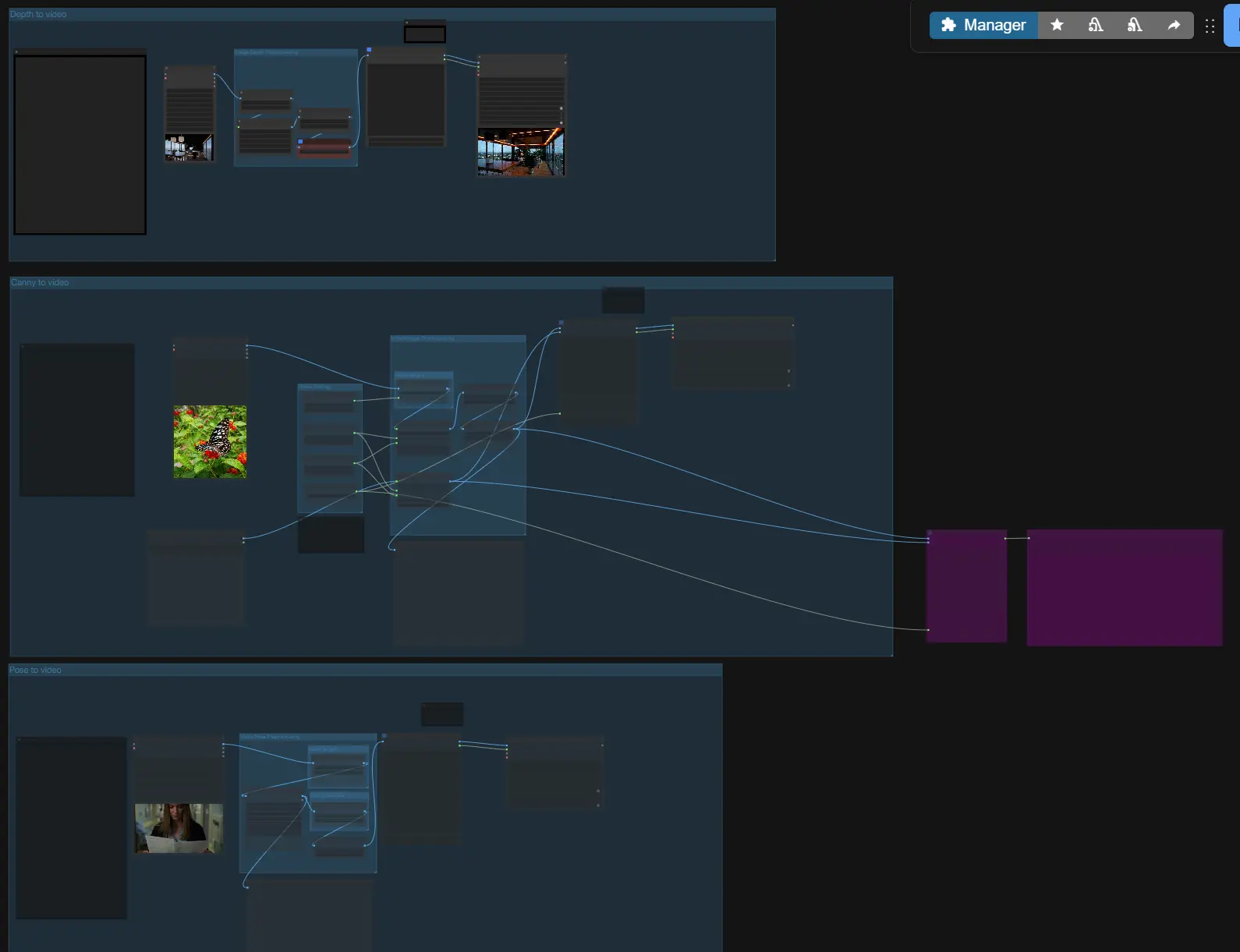
LTX-2 ControlNet: 構造誘導、音声同期ビデオ生成 in ComfyUI#
LTX-2 ControlNetは、ComfyUI-LTXVideo拡張のための制御駆動のComfyUIワークフローで、深度、キャニーエッジ、およびポーズガイダンスを使用してLTX-2ビデオ生成を操縦しながら、音声とビジュアルを同期させます。それは統一された音声-映像潜在空間で動作するため、スピーチ、フォーリー、および動きが一緒に生成され、最初のフレームから最後のフレームまで整合性を保ちます。
テキストからビデオ、画像からビデオ、およびビデオからビデオのために構築されており、IC LoRAベースのControlNetコンディショニングを追加して正確なレイアウトと動きの制御を可能にし、シーンの継続性のための初期フレーム初期化を提供し、シャープな結果を得るための潜在アップスケーリングを使用した2段階パイプラインを備えています。LTX-2 ControlNetは完全にオープンで、迅速に反復可能で、再現可能な高品質な出力が必要なクリエイター向けに制作指向です。
Comfyui LTX-2 ControlNetワークフローの主要モデル#
- LTX-2 19B (dev FP8 and distilled)。単一の潜在空間でビデオとオーディオをサンプリングするために使用されるコア音声-映像生成モデル。Model family
- Gemma 3 12B ITテキストエンコーダー。LTX-2が使用するパッケージ化されたエンコーダーを介して、プロンプトとネガティブに対する堅牢な言語理解を提供します。Encoder file
- LTX-2 Spatial Upscaler x2。ステージ2で空間詳細を洗練するために使用される潜在アップスケーリングモデル。Upscaler
- LTX-2 Audio VAE。生成された音をフレームに合わせて整合させる専門のオーディオデコーダー-エンコーダー。LTX-2チェックポイントに含まれています。Checkpoints
- IC LoRA control family for LTX-2。ControlNetスタイルのコンディショニングを追加します:
- Depth control LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- Canny control LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- Pose control LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- Distilled LoRA for quality/efficiency trade-offs: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1。深度制御パスで使用される深度推定器。Model
- SD VAE FT MSE (Stability AI)。深度の事前計算とタイルデコードに使用される画像VAE。VAE
- ComfyUI-LTXVideo extension。LTX-2サンプラー、AV潜在、オーディオVAE、および全体で使用されるガイダーノードを提供します。Repository
Comfyui LTX-2 ControlNetワークフローの使用方法#
大まかに言えば、LTX-2 ControlNetはプロンプトとオプションの参照を取得し、ControlNetスタイルのガイダンスで音声-映像潜在を構築し、最初のパスをサンプリングし、その後、潜在をアップスケールして鮮明なビデオと同期された音声を生成します。3つのガイドパス(深度、キャニー、ポーズ)のいずれかを選択して使用するか、それらを独立して使用し、長さとサイズを設定してからエクスポートします。
- 画像/ビデオの前処理
- 画像からビデオ、またはビデオからビデオを行う場合は、ローダーを使用して参照メディアを取り込みます。
VHS_LoadVideo(#196, #197, #198)は分析のためにフレームを分割し、LoadImage(#189)は静止画を処理します。グループは下流のガイドが一貫したフレームサイズを確認できるように便利なスケーリングを提供します。 - "初期フレーム"画像をシーン初期化のために前方に渡すことができ、生成グループで後で有効にします。
- 画像からビデオ、またはビデオからビデオを行う場合は、ローダーを使用して参照メディアを取り込みます。
- 画像の深度前処理
- 深度ガイダンスのために、"Image to Depth Map (Lotus)"サブグラフは入力を正規化された深度マップに変換します。これにより、LTX-2が追従できる単一フレームまたはマルチフレームの深度表現が準備されます。
- パスには、広範な構造をエンコードしつつ小さなアーティファクトに過適合しないようにするためのオプションのリサイズと強度制御が含まれています。
- ビデオポーズ前処理
- ポーズガイダンスのために、
DWPreprocessor(#158)は入力ビデオから全身のキーポイントを検出し、安定したコンディショニングのためにスケーリングします。これにより、スケルトンと四肢の方向を強調するクリーンなポーズ画像シーケンスが得られます。 - プレビューノードは、生成前に検出とアスペクト比が正しいことをすばやく確認するのに役立ちます。
- ポーズガイダンスのために、
- キャニーからビデオへ
- この制御パスは
Canny(#169)でエッジを抽出し、制御画像シーケンスと共にAV潜在を構築します。シルエット、主要な輪郭、または参照からのタイポグラフィエッジを保存したいときに使用します。 - 一貫した初期化のための初期フレーム画像入力が利用可能で、特定の静止画に一致するオープニングフレームが必要な場合にのみ有効にします。
- この制御パスは
- 深度からビデオへ
- このパスは制御画像としてLotus深度マップを供給します。深度制御は、カメラの幾何学、大規模レイアウト、および被写体の距離を強制しながら、ジェネレーターがテクスチャと照明を選択できるようにするのに理想的です。
- 初期フレームを提供して初期構図を固定し、その後、深度の指標に従って動きを進化させることができます。
- ポーズからビデオへ
- ポーズパスはプリプロセッサからのキーポイントレンダリングを使用し、体の方向と動きのタイミングを誘導します。特にキャラクターブロッキング、手の持ち上げタイミング、歩行サイクルに効果的です。
- 他のモードと同様に、継続性のためにオプションの初期フレームコンディショニングとプロンプトタイミングを組み合わせることができます。
- ビデオ設定と長さ
- "Video Settings"と"video length"グループで作業する幅、高さ、およびフレーム数を設定します。ワークフローは、LTX-2の潜在グリッドとストライドに最も近い互換サイズに無効な値を自動調整するため、安全に反復できます。
- ターゲットフレームレートをノード全体で一貫して保ちます。コンディショニングノードと最終的な多重化は、それを尊重して音声-映像の同期を維持します。
- 生成、アップスケーリング、エクスポート
- サンプリング中に、
LTXVAddGuideは選択した制御画像とともにポジティブ/ネガティブコンディショニングを統合し、SamplerCustomAdvancedはビデオとオーディオ潜在のためのLTXVSchedulerからのスケジュールを実行します。オプションの初期フレームは、LTXVImgToVideoInplaceで有効にされた場合に注入されます。 - 第二段階では、
LTXVLatentUpsamplerがx2潜在アップスケーラーで詳細を洗練します。最終デコードは、フレームのタイルVAEDecodeTiledとオーディオのLTXVAudioVAEDecodeで行われ、その後選択したブランチに応じてVHS_VideoCombineまたはCreateVideoでビデオが書き出されます。
- サンプリング中に、
Comfyui LTX-2 ControlNetワークフローの主要ノード#
LTXVAddGuide(#132)- テキストコンディショニングとIC LoRAコントロールをAV潜在にマージし、LTX-2 ControlNetガイダンスの中心として機能します。重要なコントロールのみを調整してください:あなたのパス(深度、キャニー、またはポーズ)に一致する制御LoRAを選択し、可能な場合はモデルがガイドにどれだけ厳密に従うかを調整する
image_strengthを選択します。LTXVideo拡張によって提供されるリファレンス実装とノードの動作。Docs/Code
- テキストコンディショニングとIC LoRAコントロールをAV潜在にマージし、LTX-2 ControlNetガイダンスの中心として機能します。重要なコントロールのみを調整してください:あなたのパス(深度、キャニー、またはポーズ)に一致する制御LoRAを選択し、可能な場合はモデルがガイドにどれだけ厳密に従うかを調整する
LTXVImgToVideoInplace(#149, #155)- AV潜在に初期フレーム画像を注入して、一貫したシーン初期化を提供します。初期フレームへの忠実度と進化の自由をバランスするために
strengthを使用してください。より多くの動きが必要な場合は低く、より厳しいアンカーが必要な場合は高く保ちます。純粋にテキストまたは制御駆動のオープニングを望む場合はバイパスしてください。Docs/Code
- AV潜在に初期フレーム画像を注入して、一貫したシーン初期化を提供します。初期フレームへの忠実度と進化の自由をバランスするために
LTXVScheduler(#95)- 統一された潜在の脱ノイズ軌道を駆動し、音声とビデオが一緒に収束するようにします。複雑なシーンや細かいディテールにはステップを増やし、ドラフトや迅速な反復には短縮してください。スケジュール設定はガイダンスの強さと相互作用するため、ガイダンスが強い場合は極端な値を避けてください。Docs/Code
LTXVLatentUpsampler(#112)- LTX-2 x2空間アップスケーラーで第二段階の潜在アップスケーリングを実行し、VRAMの増加を最小限に抑えながらシャープネスを向上させます。反復を応答性のあるものに保つために、基礎解像度を増やすのではなく、最初のパスの後に使用してください。Upscaler model
DWPreprocessor(#158)- ポーズ制御パスのためにクリーンなヒューマンポーズキーポイントを生成します。プレビューで検出を確認してください。手や小さな四肢がノイズの多い場合は、前処理前に入力を適度な最大寸法にスケールしてください。ControlNet補助スイートによって提供されます。Repo
VHS_VideoCombine/CreateVideo(#195, #106)- 選択したフレームレートとピクセル形式でデコードフレームとオーディオをMP4に多重化します。プレビューでオーディオデコードが整列していることを確認した後にのみ使用してください。Video Helper Suiteによって提供されます。Repo
オプションのエクストラ#
- LTX-2 ControlNetのプロンプト
- 静的属性だけでなく、時間の経過に伴うアクションを説明してください。
- 必要な音声キューまたはダイアログを含め、音声がビートに合わせて生成されるようにします。
- 繰り返し見られるアーティファクトを抑制するために、簡潔なネガティブプロンプトを使用してください。
- サイズと長さ
- 幅/高さの形式32k + 1の画像サイズを使用してください。グラフが自動修正しますが、正確な値は反復を速めます。
- 形式8k + 1のフレーム数は、スケジューリングに最も安定しています。
- 初期フレームの一貫性
- 初期フレームが必要な場合にのみ有効にし、適度な
image_strengthとペアリングして過度な制約を避けてください。
- 初期フレームが必要な場合にのみ有効にし、適度な
- VRAMとスループット
- ワークフローには、json
シーケンス並列およびトーチコンパイルオプションがLTXVideoパッチャーに含まれており、マルチGPUまたはメモリ制約のあるセットアップのために使用できます。長いクリップの際にはオンにし、ノードの動作をデバッグする際にはオフにします。Extension
謝辞#
このワークフローは以下の作品とリソースを実装および構築しています。ComfyUI-LTXVideoの寄与とメンテナンスに対してLightricksに感謝いたします。権威ある詳細については、以下のリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- ComfyUI-LTXVideo GitHubリポジトリ: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
注: 参照するモデル、データセット、コードの使用は、それぞれの作者およびメンテナによって提供されたライセンスおよび条件に従います。