
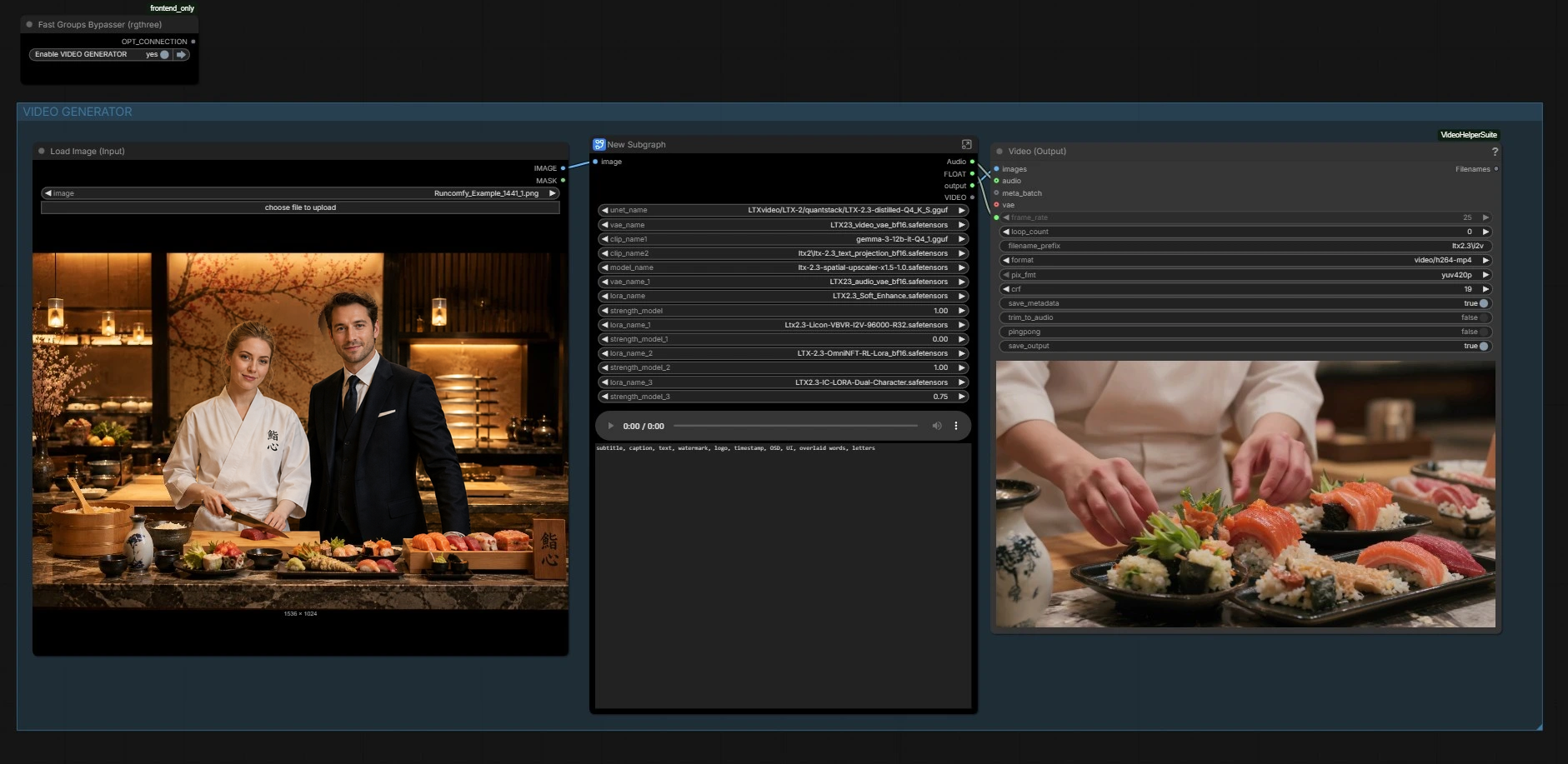
LTX 2.3 デュアルキャラクター リップシンク LoRA: 1 つの画像と 1 つのオーディオトラックから 2 キャラクターのリップシンクビデオ#
この ComfyUI ワークフローは、1 枚の静止画像と録音された 2 人のスピーカーの会話を、両方の画面上のキャラクターに同期されたスピーチを備えた一貫したアイデンティティ安定のビデオに変換します。LTX-2.3 ビデオバックボーンと LTX 2.3 デュアルキャラクター リップシンク LoRA を中心に構築されており、対話から各顔に音素とタイミングをマッピングしながら、表情、視線、シーンの一貫性をフレーム全体で保持します。
インタビュー、映画の対話、ビデオホスト付きポッドキャスト、仮想キャラクターのやり取りのために設計されたこのワークフローは、シーンレイアウトのためのテキストプロンプトとオーディオ駆動のモーションを組み合わせています。クイックな外観開発のための画像ブートストラップステージ、時間の安定性のための 2 段階の LTX サンプリング、鮮明な結果のための潜在的アップスケーラーが含まれています。最終出力は埋め込みオーディオ付きの MP4 です。
Comfyui LTX 2.3 デュアルキャラクター リップシンク LoRA ワークフローの主要モデル#
- LTX-2.3 ビデオ生成モデル。テキスト、画像、オーディオに基づいて時間的に一貫したビデオを合成するマルチモーダルディフュージョンバックボーンを提供します。 Lightricks/LTX-2.3
- LTX-2.3 ビデオ VAE とオーディオ VAE。モデルが効率的かつ同期された生成を維持するために使用するビデオおよびオーディオの潜在エンコードとデコードを行います。LTX-2.3 リリースと共に出荷されます。 Lightricks/LTX-2.3
- LTX 空間潜在アップスケーラー。基本パス後に詳細を洗練し、潜在空間でアップサンプリングしてよりクリーンなテクスチャとエッジを実現します。LTX アセットと共に利用可能なバリアントがあります。 Lightricks/LTX-2
- LTX 2.3 デュアルキャラクター リップシンク LoRA。ショット内の 2 つの顔の口の動きとタイミングを促進するトレーニングを注入し、顔のアイデンティティを保持します。
- Z-Image Turbo テキストから画像へのモデル。ビデオ合成前にアイデンティティ、フレーミング、および照明を固定する高品質の参照静止画を迅速に生成します。 Comfy-Org/z_image_turbo
このワークフローで使用される関連ノードパック: ComfyUI-KJNodes, ComfyUI-VideoHelperSuite, rgthree-comfy, および ComfyUI-PromptRelay。
Comfyui LTX 2.3 デュアルキャラクター リップシンク LoRA ワークフローの使い方#
ワークフローは、ヒーローフレームを作成する画像ジェネレーターと、見た目を保ちながらオーディオから動きとリップシンクを駆動するビデオジェネレーターの 2 つの調整された部分で構成されています。以下のグループをガイドとして使用してください。
画像ジェネレーター#
このセクションはアンカースティルを構築します。プロンプトリストのシーンプリセットを使用して、迅速に構成を下書きし、両方の人物のキャラクター説明でテキストを洗練します。コンパクトな画像拡散スタック(「Z IMG TURBO」サブグラフ)はプロンプトをエンコードし、クリーンな参照スティルをサンプリングします。画像はデコードされ、検査のために保存され、次に動画のアイデンティティとレイアウトをシードするために転送されます。
ここで触れる主な入力: シーン、衣装、2 つの異なるキャラクターの説明プロンプト; 現実感を損なうレンズやレンダリングの専門用語を避けます。
モデル#
ここでグラフは LTX-2.3 バックボーン、そのビデオとオーディオ VAE、テキストエンコーダー、および潜在アップスケーラーをロードします。また、LTX 2.3 デュアルキャラクター リップシンク LoRA、スタイルまたはエンハンスメント LoRA を有効にした場合に適用します。ここで基本モデルの機能が LoRA の 2 スピーカー リップシンク動作と組み合わされ、アイデンティティを犠牲にせずに口の動きを誘導します。重みを交換したり、LoRA の影響を調整したりしない限り、アクションは必要ありません。
カスタムオーディオ#
ここに会話トラックを供給します。オーディオファイルがロードされ、タイミングと音素のキューをパイプラインに伝えるオーディオ潜在にエンコードされます。オーディオを提供しない場合、ワークフローは空のオーディオ潜在を使用してモーションを生成できますが、LTX 2.3 デュアルキャラクター リップシンク LoRA は実際の対話で輝くように設計されています。明確なターンテイクを持つクリーンな 2 スピーカーミックスを使用して、口の動きの分離を最適化します。
ビデオパラメーター#
目標の期間とフレームレートを設定します。これらの値はサンプリング、スケジューリング、トリミングガイド、最終レンダリング全体で再利用されるため、唇、まばたき、ショットタイミングが一致したままです。提供されたオーディオと一致するビデオの長さを維持して、余分なリードインやテールを避けてください。
潜在生成#
選択した静止画が事前処理され、その寸法が検出されます。ワークフローは適切な長さのビデオ潜在を作成し、静止画をそのまま挿入して最初のフレームがデザインと一致するようにします。フルフレームノイズマスクが適用され、背景が顔に対してどれだけ進化できるかを制御します。準備されたオーディオ潜在は次にビデオ潜在とペアリングされ、両方のモダリティが条件付けの準備が整います。
注目すべきノード: LTXVPreprocess は LTX のために静止画をスケーリングし、EmptyLTXVLatentVideo はタイムラインを構築し、LTXVImgToVideoInplaceKJ (#5881) は静止画から最初のフレームをシードしてアイデンティティをロックします。
コンディショニング#
テキストプロンプトがエンコードされ、ポジティブおよびネガティブの条件として添付されます。グローバルプロンプトボックスを使用して、自然な言語でステージングと意図を説明します。短いショットリストを含めることもできます。専用のネガティブテキストエンコーダーは、フレーム上の字幕、透かし、UI を抑制し、顔をクリーンに保つようにします。クロップガイドヘルパーは潜在を分析して両方の顔に注意を向け、LTX 2.3 デュアルキャラクター リップシンク LoRA をアクティブにしてスピーカーごとの表情追跡を改善します。
代表的なコンポーネント: PromptRelayEncode (#5903) はシーンの説明を潜在コンテキストとマージし、LTXVConditioning はモダリティの両方にフレームレートに依存したガイダンスを添付します。
第 1 サンプリング#
最初のデノイジングパスは、時間的に一貫した基本ビデオを生成し、口の動きをブロックします。軽量なスケジューラーとサンプラーのペアが自動的に選択され、パラメーターは保存されたタイミング値からルーティングされます。LTX2_NAG から出てくるモデルバリアントは、ビデオとオーディオ条件のためのノイズに敏感なガイダンスを追加し、スピーチタイミングがコンテンツ形成中に固定されるようにします。
コアサンプラーパス: SamplerCustom (#5891) と KSamplerSelect、基本スケジューラー; 特定のサンプラーの好みがある場合にのみ調整します。
第 2 段階のアップスケールと洗練#
第 2 段階はシャープネスと微細表情を改善します。潜在アップスケーラーは空間の詳細を増やし、オーディオとビデオの潜在が再結合され、洗練サンプラーが微調整を行いながら既存の動きを保持します。その後、潜在は分離され、画像シーケンスとオーディオ波形にデコードされます。
重要なブロック: LTXVLatentUpsampler (#5927) は明瞭さのため、SamplerCustomAdvanced (#5929) は洗練パスのため、その後 VAEDecode と LTXVAudioVAEDecode はピクセルとオーディオスペースに戻ります。
出力#
最後に、フレームとオーディオが再生とレビューのために MP4 にパックされます。条件付けに使用されたフレームレートがここで再利用され、視覚的なリズムと音素タイミングが生成中にモデルが見たものと一致します。必要に応じて、グラフ中でオーディオをすばやく確認することもできます。
出力パス: CreateVideo (#5931) はクリップを構築します。補助的な VHS_VideoCombine (#5905) パスは、メタデータコントロールを備えた代替エクスポート用に提供されています。
Comfyui LTX 2.3 デュアルキャラクター リップシンク LoRA ワークフローの主要ノード#
LTXICLoRALoaderModelOnly(#5958) LTX 2.3 デュアルキャラクター リップシンク LoRA を LTX-2.3 バックボーンにロードします。strength_modelを増やして、より厳密な口の動きとスピーカーの分離を必要とする場合; 基本モデルの動きとスタイルが支配するようにする場合は、特に追加のスタイル LoRA をスタックする場合に下げます。PromptRelayEncode(#5903) シーンの説明と、オプションで簡単なショットプランを書くための中心的な場所。グローバルプロンプトをモデルのコンテキストと現在の潜在と融合させ、タイムライン全体でガイダンスが一貫しているようにします。言語を明確に保ち、アイデンティティと役割の分離を助けるために両方のキャラクターを明確に説明してください。LTXVImgToVideoInplaceKJ(#5881) 生成またはロードされた静止画からビデオ潜在の最初のフレームを直接シードします。これにより、アイデンティティ、衣装、照明がロックされ、時間の経過によるドリフトが減少します。両方の顔が遮られない中ショットまたは中広ショットを使用して、最良の結果を得ます。LTXVAudioVAEEncode(#5851) 提供された対話トラックをモデルが音素タイミングに使用できるオーディオ潜在に変換します。重い圧縮のないクリーンなミックスをフィードし、唇の動きのオフセットを避けるために開始時間が最初の画面上のスピーチと一致することを確認してください。SamplerCustom(#5891) とSamplerCustomAdvanced(#5929)
2 つの補完的なデノイジングステージ。ステージ間でサンプラーファミリーを一貫して保ち、望む外観がある場合、ノイズスケジューリングの急激な変更を避けてください。
LTXVLatentUpsampler(#5927) 洗練前に LTX 潜在アップスケーラーを適用して、確立された動きを不安定にすることなく鮮明さを追加します。ターゲットの解像度とテクスチャの現実感に適したアップスケーラーバリアントを選択してください。
オプションの追加#
- 背景ノイズが最小限の 2 スピーカー WAV を 24 kHz で使用し、LTX 2.3 デュアルキャラクター リップシンク LoRA がターンを分離するのを助けるために行間に短い自然なポーズを追加します。
- 両方の被写体が見える静止画を生成または供給し、一般的にカメラに向かって顔を向け、顔全体に一貫した照明を設定します。
- サンプリング中に焼き付き UI 要素を避けるために、「字幕、キャプション、ロゴ、タイムスタンプ」を除外するネガティブテキストプロンプトを保持します。
- タイミングを検証するために短いクリップから始め、動json
- タイミングを検証するために短いクリップから始め、動作が気に入ったら期間を延長したり解像度を上げたりしてください。
- スタイル LoRA を追加する場合、LTX 2.3 デュアルキャラクター リップシンク LoRA に対してバランスを取り、シーンが選択した美学を保持しながらアーティキュレーションが正確であるようにします。
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。「LTX 2.3 デュアルキャラクター リップシンク LoRA ワークフローソース」のクリエイターに感謝します。詳細については、以下のリンク先の元のドキュメントとリポジトリを参照してください。
リソース#
- LTX 2.3 デュアルキャラクター リップシンク LoRA ワークフローソース/LTX 2.3 デュアルキャラクター リップシンク LoRA ワークフローソース
- ドキュメント / リリースノート: YouTube video
注: 参照されたモデル、データセット、コードの使用は、それぞれの著者およびメンテナーによって提供されたライセンスおよび条件に従います。