
Hunyuan Videoは、最先端のテキストから動画生成機能を提供することにより、クローズドソースシステムの支配に挑むオープンソースの基盤モデルです。大規模データのキュレーション、適応的なアーキテクチャ設計、最適化されたインフラストラクチャの革新に基づいて構築されたHunyuan Videoは、視覚品質の新たな基準を設定します。
Hunyuan Videoは主にテキストから動画への生成に焦点を当てていますが、Hunyuan IP2Vワークフローは同じモデルを使用して画像とテキストプロンプトを動的な動画に変換することで、この機能を拡張します。このアプローチにより、ビジュアルリファレンスを使用してコンテンツ作成を誘導することができ、AI駆動のコンテンツ制作のための代替方法を提供します。
画像とプロンプトを組み合わせることで、Hunyuan IP2Vは入力の主要な特性を保ちながら動きを生成し、AIアニメーション、コンセプトビジュアライゼーション、および芸術的なストーリーテリングのための有用なツールとなります。動的なシーン、スタイライズされた動き、または静的なビジュアルをアニメーションシーケンスに拡張する場合でも、Hunyuan Videoのフレームワークは高品質の結果への効率的な経路を提供します。
Hunyuan Video - IP2Vワークフローの使用方法#
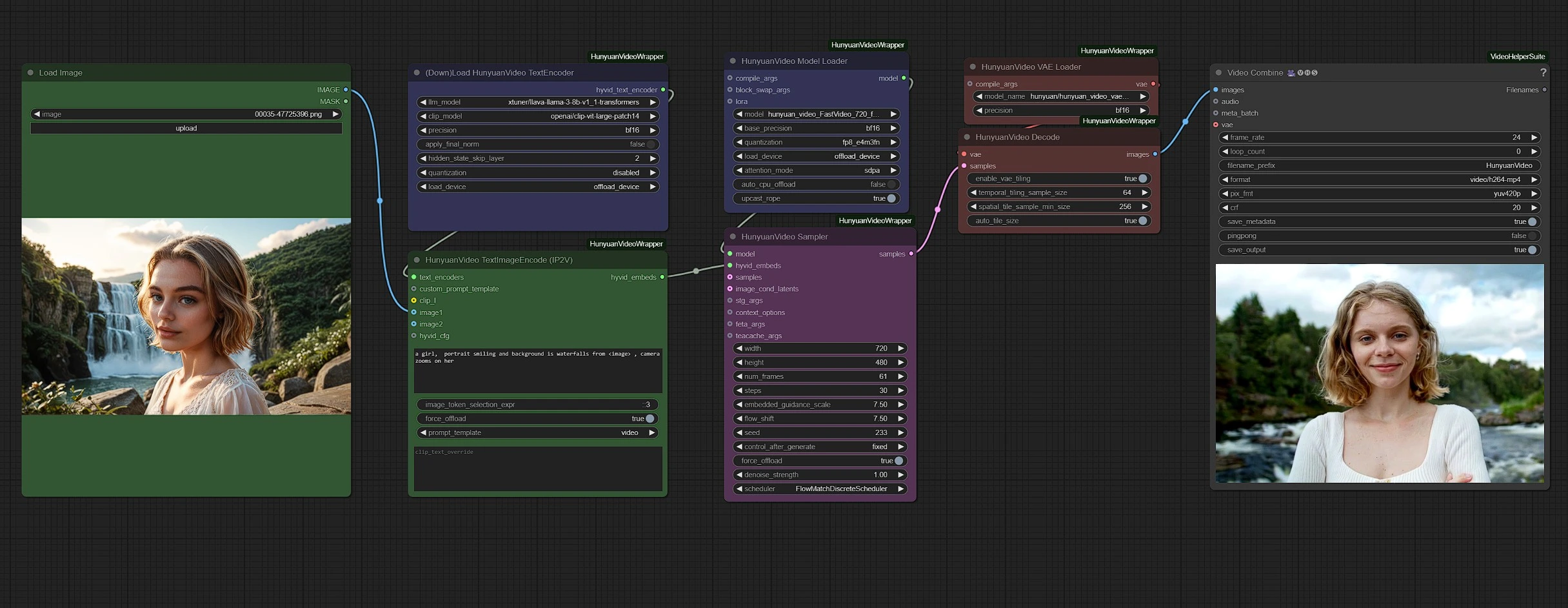
グループは明確にするために色分けされています:
- 緑 - 入力
- 紫 - モデル
- ピンク - Hunyuan Sampler
- 赤 - VAE + デコード
- 灰色 - 出力
緑のノードに画像とテキストを入力し、ピンクのサンプラーノードで動画設定(例えば持続時間と解像度)を調整します。
入力1 - 画像#
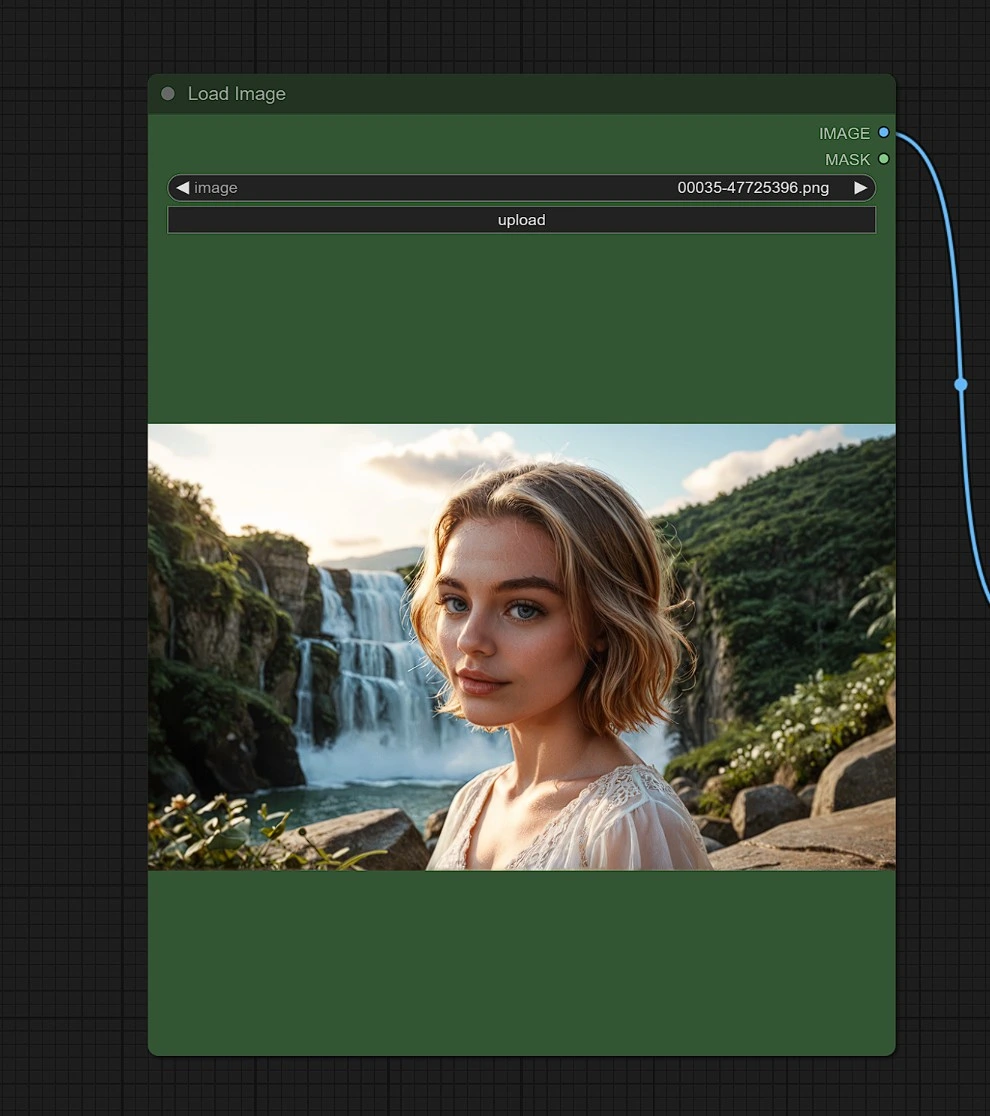
求める類似結果の場所、人物、または物体の参照として画像をアップロードします。
入力2 - テキスト#
最初のテキストボックスにプロンプトを入力し、キーワード"<image>"を使用して画像を含めます。
例えば、入力が"empty street"で女性を追加したい場合、プロンプトは次のようになります:"A portrait of a woman, background is <image>."
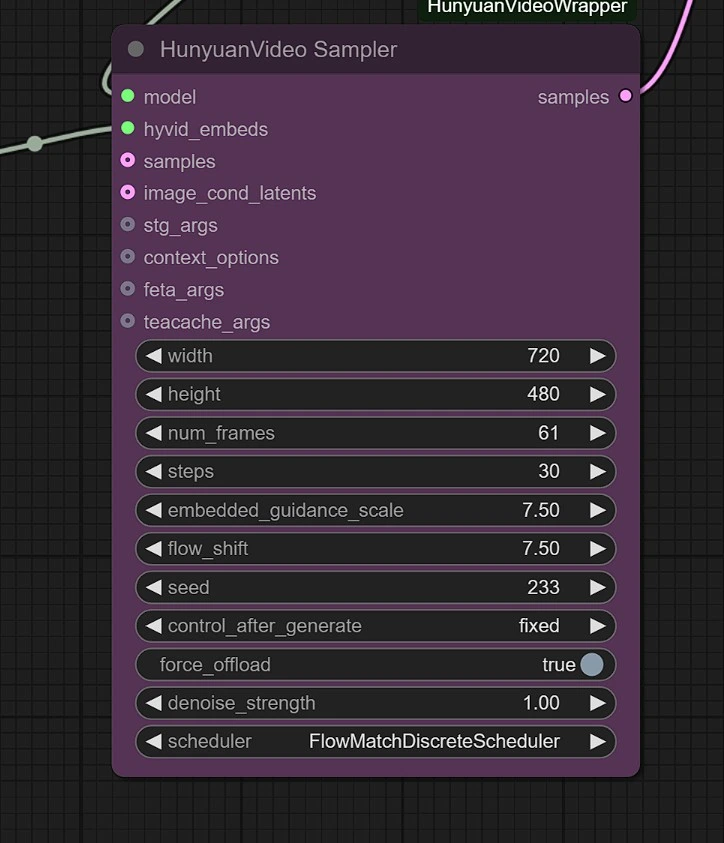
サンプラー#
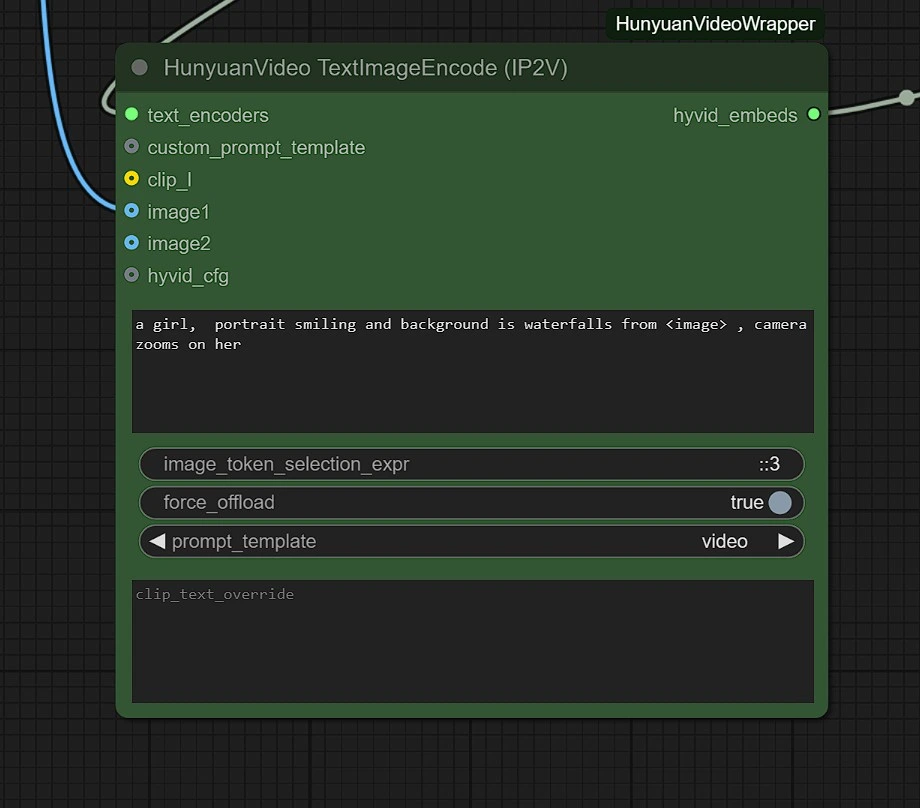
次の項目を調整できます:
- 画像解像度 - 最大1280px 720pxで、より多くのVRAMを必要とします。
- フレーム - フレーム数を設定します(24フレーム = 1秒)。
モデル#
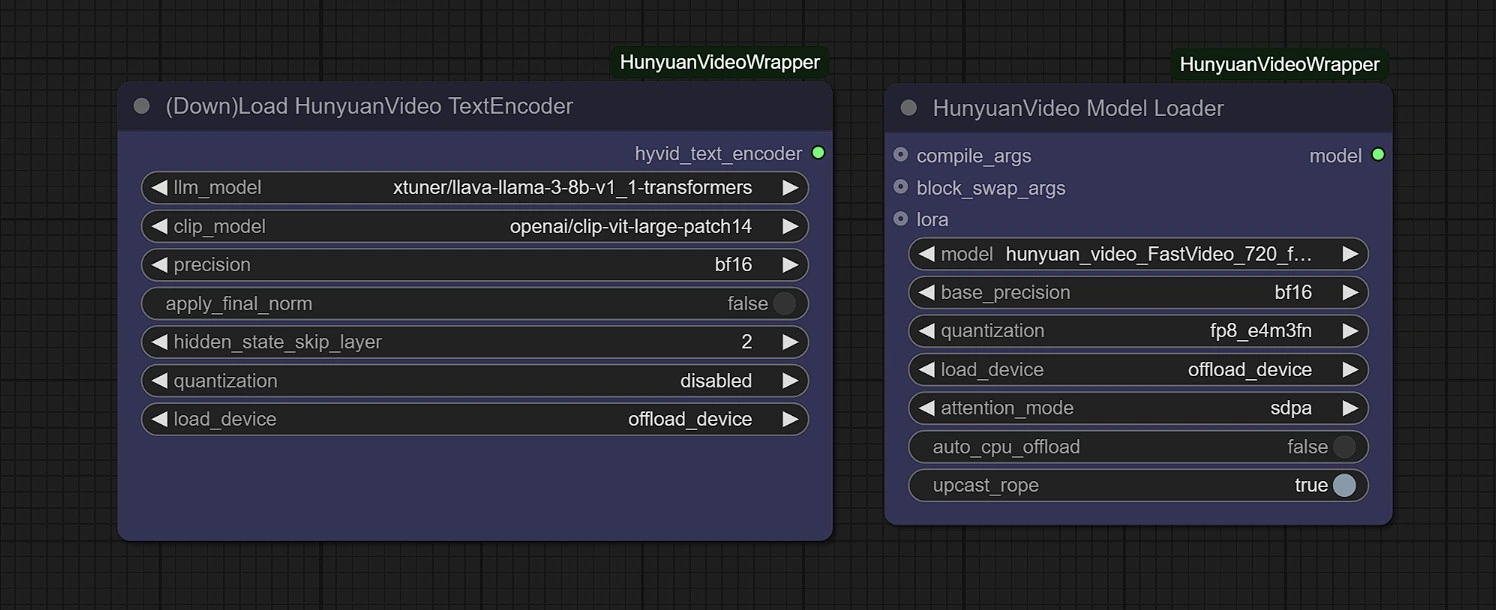
このグループでは、初回実行時にモデルが自動的にダウンロードされます。ダウンロードが完了するまでに3〜5分かかる場合があります。
リンク:
- Diffusion: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
- ComfyUI > models > diffusion_models
- Vae: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensors
- ComfyUI > models > vae
出力#
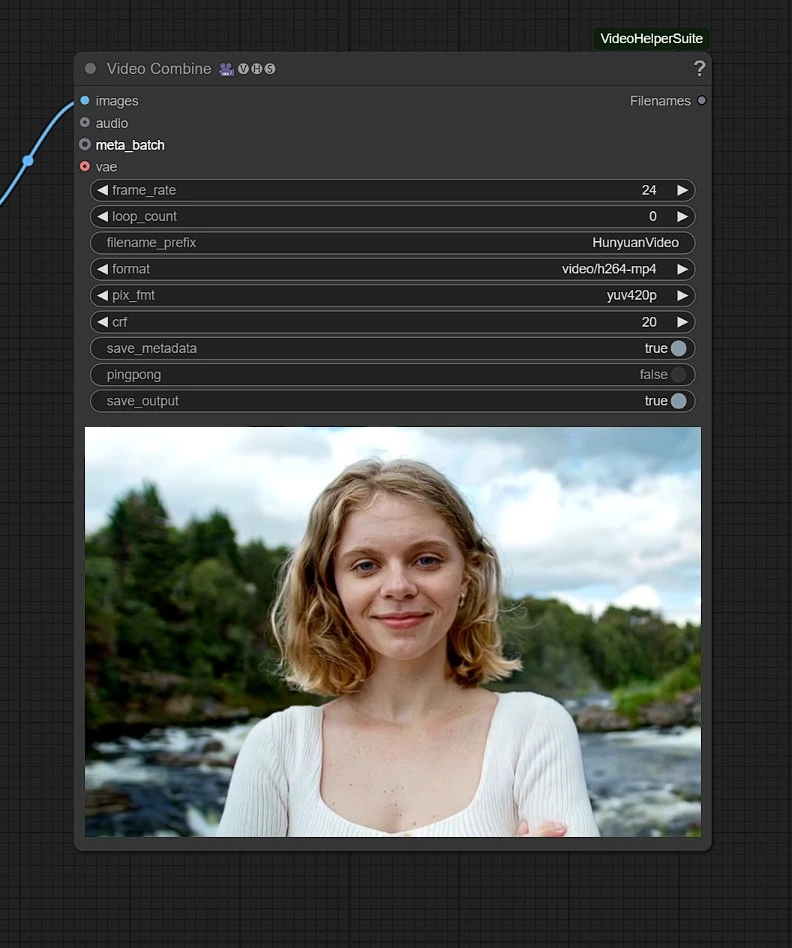
レンダリングされた動画はComfyuiの出力フォルダに保存されます。
Hunyuan IP2Vワークフローを使用すると、テキストベースの動画生成に限定されず、画像に動きとスタイルを与えることができます。AI映画制作、デジタルアート、またはクリエイティブなストーリーテリングにおいて、このワークフローはこれまで以上に制御できる力を提供します。