
Hunyuan Video 1.5 ComfyUIワークフロー: 高速テキストからビデオ、画像からビデオへ、1080pの超高解像度#
このワークフローはHunyuan Video 1.5をComfyUIに組み込み、消費者向けGPUで高速かつ一貫性のあるビデオ生成を提供します。テキストからビデオ、画像からビデオの両方をサポートし、専用の潜在アップサンプラーと蒸留された超高解像度モデルを使用してオプションで1080pにアップスケールします。Hunyuan Video 1.5は、画質、動きの忠実性、速度のバランスを取るために、Diffusion Transformerと3D因果VAE、選択的スライディングタイルアテンション戦略を組み合わせています。
クリエイター、製品チーム、研究者は、このComfyUI Hunyuan Video 1.5ワークフローを使用して、プロンプトまたは単一の静止画像から迅速に反復し、720pでプレビューし、必要に応じてクリーンな1080p出力で仕上げることができます。
Comfyui Hunyuan Video 1.5ワークフローの主要モデル#
- HunyuanVideo 1.5 720p Image-to-Video UNet。開始画像から動きと時間的一貫性を生成します。重みはHugging FaceのComfy-Orgリパッケージに提供されています。Comfy-Org/HunyuanVideo_1.5_repackaged。
- HunyuanVideo 1.5 720p Text-to-Video UNet。同じコアアーキテクチャを使用してプロンプトから直接ビデオを生成し、プロンプトファーストのワークフローに調整されています。上記のリパッケージリポジトリをご覧ください。
- HunyuanVideo 1.5 1080p Super-Resolution UNet (distilled)。720pの潜在をより高い詳細に精緻化しながら、動きとシーン構造を保持します。同じリパッケージに含まれています。
- HunyuanVideo 1.5 3D VAE。効率的な生成とタイル化デコードのためにビデオ潜在をエンコードおよびデコードします。
- HunyuanVideo 1.5 Latent Upsampler 1080p。潜在シーケンスを1920×1080にリスケールし、速度とメモリ効率を向上させます。
- Qwen 2.5 VL 7BテキストエンコーダーとByT5 Smallテキストエンコーダー。多様なプロンプトのための堅牢な指示フォローとトークナイゼーションを提供し、このワークフローのためにHugging Faceバンドルでリパッケージされています。ByT5のオリジナルモデルカード: google/byt5-small。
- SigCLIP Vision (ViT-L/14, 384)。開始画像から高品質な視覚的特徴を抽出し、画像からビデオへのコンディショニングをガイドします。Comfy-Org/sigclip_vision_384。
Comfyui Hunyuan Video 1.5ワークフローの使用方法#
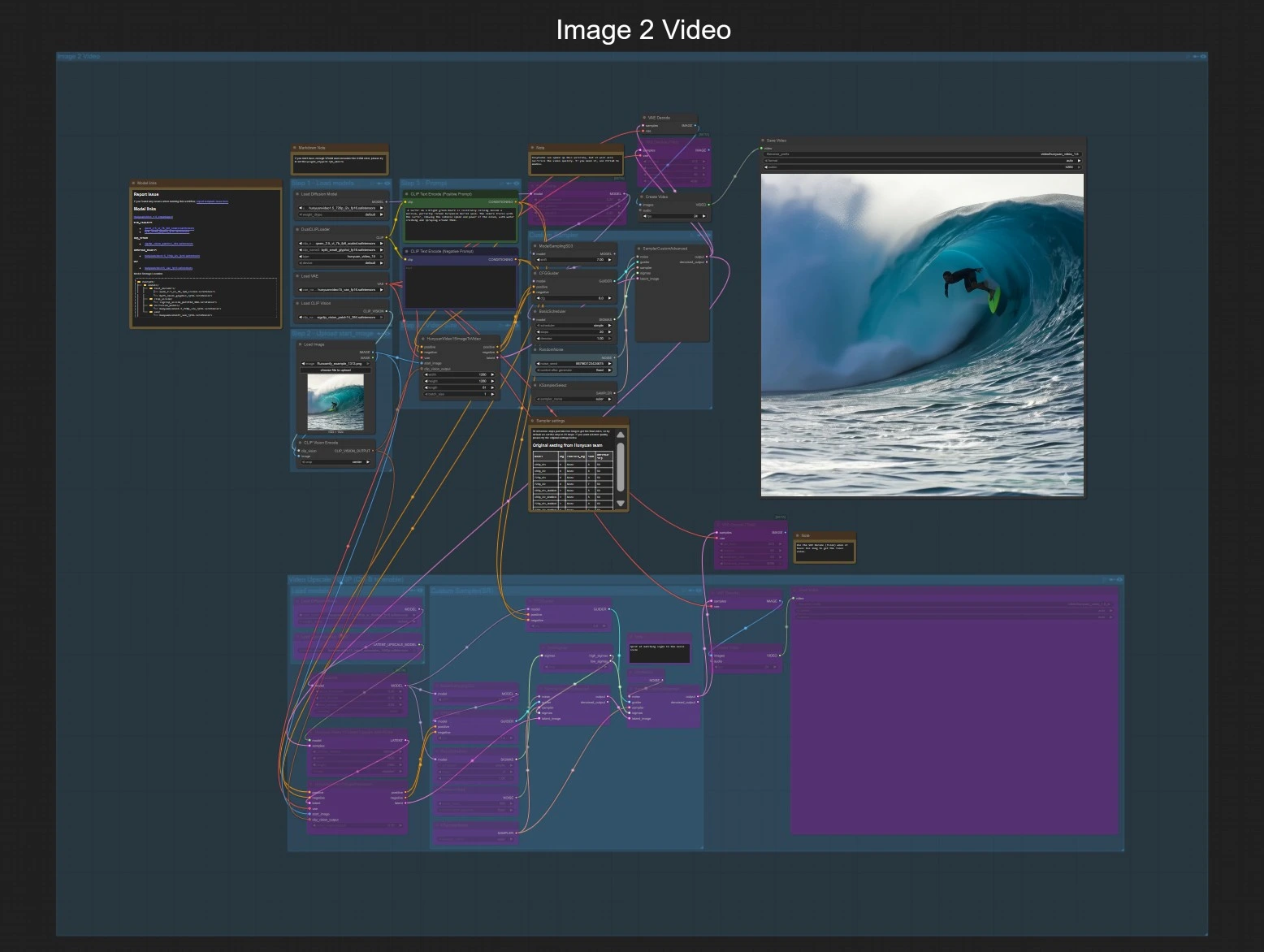
このグラフは、同じエクスポートとオプションの1080p仕上げステージを共有する2つの独立したパスを公開します。Image to VideoまたはText to Videoのいずれかを選択し、オプションで1080pグループを有効にして仕上げます。
Image to Video#
Step 1 — モデルをロード ローダーは、Hunyuan Video 1.5 UNetの画像からビデオへの変換、3D VAE、デュアルテキストエンコーダー、SigCLIPビジョンを取り込みます。これにより、単一の開始画像とプロンプトを受け入れるための準備が整います。モデルが利用可能であることを確認する以外にユーザーの操作は必要ありません。
Step 2 — 開始画像をアップロード LoadImage (#80)にクリーンで露出の良い画像を提供してください。このグラフは、CLIPVisionEncode (#79)でこの画像をエンコードし、Hunyuan Video 1.5が動きとスタイルをリファレンスに固定できるようにします。ターゲットのアスペクト比に大まかに一致する画像を使用し、トリミングやパディングを減らします。
Step 3 — プロンプト CLIP Text Encode (Positive Prompt) (#44)で説明を書いてください。不要なアーティファクトやスタイルを避けるために、CLIP Text Encode (Negative Prompt) (#93)でネガティブプロンプトを使用します。プロンプトは簡潔にしつつ、被写体、動き、カメラの動作について具体的に記述してください。
Step 4 — ビデオサイズと期間 HunyuanVideo15ImageToVideo (#78)は、空間解像度と合成するフレーム数を設定します。長いシーケンスはより多くのVRAMと時間を必要とするため、短いものから始めて、動きが気に入ったらスケールアップしてください。
カスタムサンプリング サンプラースタック(ModelSamplingSD3 (#130)、CFGGuider (#129)、BasicScheduler (#126)、KSamplerSelect (#128)、RandomNoise (#127)、SamplerCustomAdvanced (#125))は、ガイダンスの強さ、ステップ、サンプラーの種類、シードを制御します。より多くの詳細と安定性のためにステップを増やし、プロンプトを繰り返す際に結果を再現するために固定シードを使用してください。
プレビューと保存 潜在シーケンスはVAEDecode (#8)でデコードされ、CreateVideo (#101)で24 fpsのビデオにフレーム化され、SaveVideo (#102)で書き出されます。これにより、レビューのための迅速な720pプレビューが得られます。
1080p仕上げ(オプション) “Video Upscale 1080P”グループを切り替えて仕上げチェーンを有効にします。潜在アップサンプラーは1920×1080に拡張し、蒸留された超高解像度UNetが詳細を2段階で精緻化します。VAEDecodeTiledと2番目のCreateVideo/SaveVideoペアが1080pの結果をエクスポートします。
Text to Video#
Step 1 — モデルをロード ローダーは、Hunyuan Video 1.5 720pテキストからビデオへのUNet、3D VAE、およびデュアルテキストエンコーダーを取得します。このパスは開始画像を必要としません。
Step 3 — プロンプト ポジティブエンコーダーCLIP Text Encode (Positive Prompt) (#149)に説明を入力し、必要に応じてCLIP Text Encode (Negative Prompt) (#155)でネガティブプロンプトを追加します。シーン、被写体、動き、カメラを具体的に記述し、言語を具体的にしてください。
Step 4 — ビデオサイズと期間 EmptyHunyuanVideo15Latent (#183)は、選択した幅、高さ、フレーム数で初期の潜在を割り当てます。これを使用して、ビデオの長さと大きさを設定します。
カスタムサンプリング ModelSamplingSD3 (#165)、CFGGuider (#164)、BasicScheduler (#161)、KSamplerSelect (#163)、RandomNoise (#162)、およびSamplerCustomAdvanced (#166)が協力して、ノイズをプロンプトに導かれた一貫したビデオに変換します。ステップとガイダンスを調整して速度と忠実性をトレードし、シードを固定してランを比較可能にします。
プレビューと保存 デコードされたフレームはCreateVideo (#168)によって組み立てられ、SaveVideo (#167)によって保存されます。24 fpsでの迅速な720pレビューが可能です。
1080p仕上げ(オプション) “Video Upscale 1080P”グループを有効にして潜在を1080pにアップスケールし、蒸留SR UNetで精緻化します。2段階のサンプリングにより、シャープネスが向上しながら動きが維持されます。タイル化デコーダーと2番目の保存ステージが最終的な1080pビデオをエクスポートします。
Comfyui Hunyuan Video 1.5ワークフローの主要ノード#
HunyuanVideo15ImageToVideo (#78) 開始画像とプロンプトに基づいてビデオを生成します。解像度と総フレーム数を調整して、クリエイティブターゲットに合わせてください。高解像度と長いクリップはVRAMと時間を増加させます。このノードは、CLIP-Visionの機能とテキストガイダンスをサンプリング前に融合させるため、画像からビデオへの質にとって中心的です。
EmptyHunyuanVideo15Latent (#183) テキストからビデオへの潜在グリッドを幅、高さ、フレーム数で初期化します。シーケンスの長さを事前に定義し、スケジューラーとサンプラーが安定したノイズ除去の軌跡を計画できるようにします。最終的な出力に合わせてアスペクト比を一貫させ、後で余分なパディングを回避します。
CFGGuider (#129) 分類子フリーのガイダンス強度を設定し、プロンプトの遵守と自然さをバランスさせます。ガイダンスを増やしてプロンプトをより厳密に追従させ、過飽和やちらつきを減らすために低くします。基本生成中は中程度の値を使用し、超高解像度の精緻化にはガイダンスを低くします。
BasicScheduler (#126) ノイズ除去ステップの数とスケジュールを制御します。より多くのステップは通常、より良い詳細と安定性を意味しますが、レンダリングが長くなります。ステップ数とサンプラーの選択を組み合わせて最良の結果を得るために、このワークフローは高速で汎用的なサンプラーをデフォルトとして使用します。
SamplerCustomAdvanced (#125) 選択したサンプラーとガイダンスでノイズ除去ループを実行します。1080pの仕上げチェーンでは、SplitSigmasで分割された2段階で高ノイズで構造を確立し、低ノイズで詳細を精緻化します。ステップとガイダンスを調整しながら種を固定して、出力を信頼性を持って比較できるようにします。
HunyuanVideo15LatentUpscaleWithModel (#109) リパッケージされた重みからの専用アップサンプラーを使用して、潜在シーケンスを1920×1080にリスケールします。潜在空間でのアップスケーリングは、ピクセル空間のリサイズよりも高速でメモリに優しく、蒸留SRモデルが微細な詳細を追加するためのステージを設定します。より大きなターゲットはより多くのVRAMを要求します; 16:9を維持して最高のスループットを得てください。
HunyuanVideo15SuperResolution (#113) Hunyuan Video 1.5バンドルからの1080p SR蒸留UNetでアップスケーリングされた潜在を精緻化し、オプションで開始画像とCLIP-Visionの手がかりを取ることで一貫性を保ちます。これにより、動きを維持しながら鮮明なテクスチャとラインワークが追加されます。SR重みはComfy-Org/HunyuanVideo_1.5_repackagedで利用可能です。
EasyCache (#116) 中間モデルの状態をキャッシュしてプレビュー反復を加速します。迅速なターンアラウンドを希望する場合に有効にし、最終パスで最大品質を得るために無効にします。同じ解像度と期間でプロンプトを繰り返すときに特に役立ちます。
オプションの追加機能#
- プロンプトを具体的に保ちます。被写体、動詞の動き、カメラの動きを記述します。よく見られるアーティファクトを抑制するために短いネガティブプロンプトを使用します。
- 画像からビデオへの変換には、クリーンで高コントラストの開始画像を好みます。ターゲット解像度にアスペクト比を合わせてパディングを最小限に抑えます。
- 速度のためには、短い期間と720pで反復し、最終ランのためにのみ1080pグループをオンにします。
- VRAMが厳しい場合は、タイル化VAEデコードを切り替え、モデルローダーで公開されている低精度設定で重みをロードすることを検討してください。
- ステップ、ガイダンス、言葉遣いを調整しながらシードを固定して、変更をラン全体で測定可能にします。
謝辞#
このワークフローは、以下の作品とリソースを実装し、それに基づいて構築されています。Hunyuan Video 1.5ワークフローチュートリアルの貢献とメンテナンスに対し、Comfy.orgに感謝いたします。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- Hunyuan Video 1.5 Source
- ドキュメント / リリースノートjson
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.