
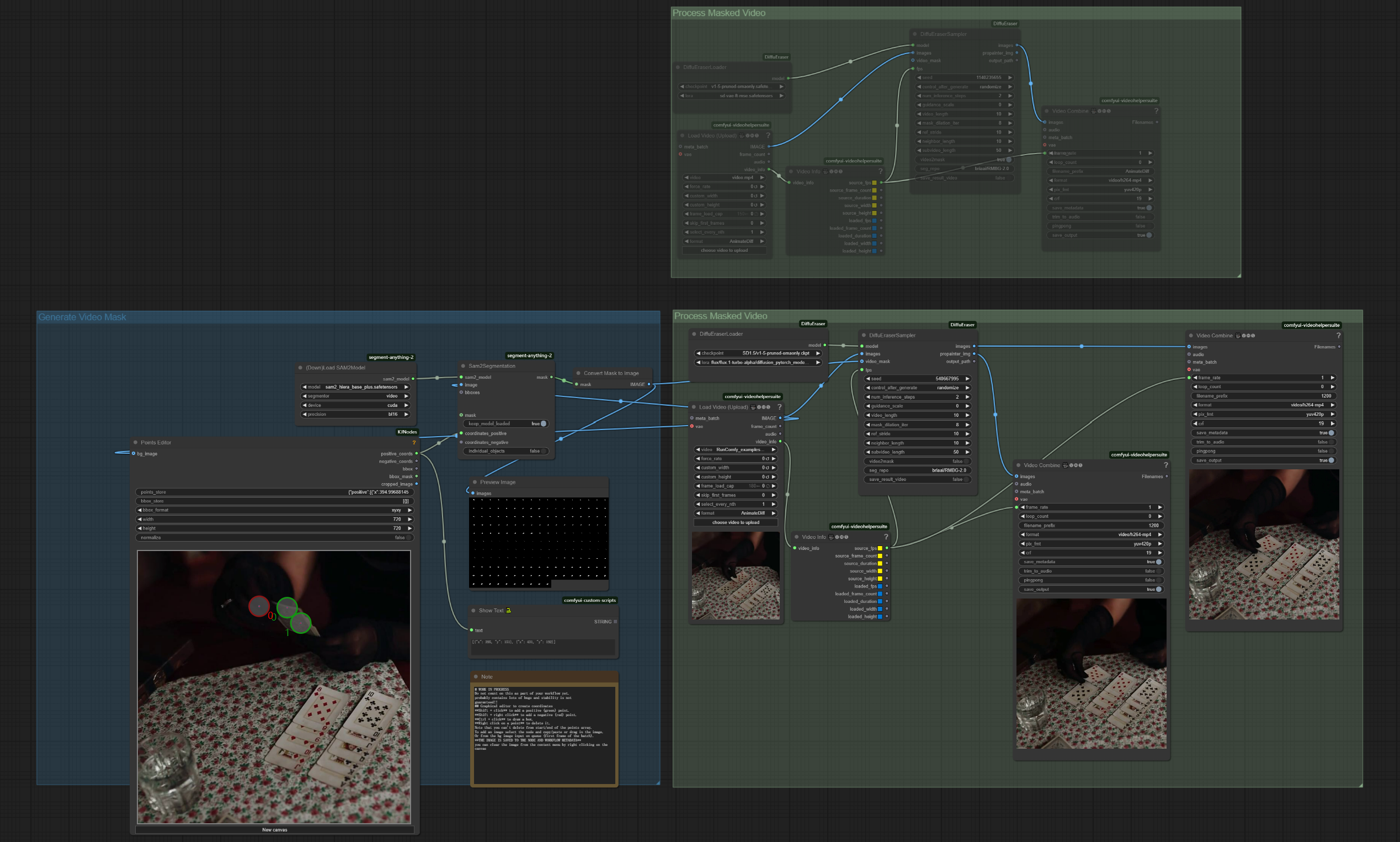
ComfyUI DiffuEraserビデオインペインティングワークフローディスクリプション#
ComfyUI DiffuEraserワークフローとは?#
DiffuEraser は、ビデオから不要なオブジェクトをシームレスに除去し、時間的一貫性を保持する最先端のビデオインペインティングソリューションです。強力な拡散ベースのインペインティングモデルを使用して、DiffuEraserは欠落している領域をコンテキストに応じた正確なコンテンツで再構築します。このワークフローは、Segment Anything 2 (SAM2) と統合されており、自動マスク生成を行い、手動で作成されたマスクの必要性を排除します。
DiffuEraserは、デノイジングUNetと補助的なBrushNetブランチを利用し、時間的アテンションを統合してフレームの一貫性を維持します。事前情報を活用することで、幻覚やアーティファクトを減少させ、完璧なオブジェクト除去を保証します。
Runcomfy Crewによる**SAM2**統合は、ポイント選択インターフェースを使用してマスク生成を自動化し、ユーザーが手動でマスクを作成することなくオブジェクトをマークして除去できるようにします。これにより、インペインティングワークフローが大幅に簡素化されます。
DiffuEraserワークフローの利点#
- 自然なシーンブレンディングによる高品質の再構築。
- SAM2による自動マスク生成で手動作業を削減。
- フレーム間のシームレスなインペインティングのための時間的一貫性。
- ポイントベースのインターフェースによる柔軟なオブジェクト選択。
- 最小限のユーザー入力でプロフェッショナルな結果。
- 事前情報を活用して幻覚を抑制します。
- 標準のビデオフォーマットと互換性があり、手間のかからない統合が可能です。
DiffuEraserワークフローの使用方法#
DiffuEraserによるオブジェクト除去#
主な生成方法: SAM2 + DiffuEraser#
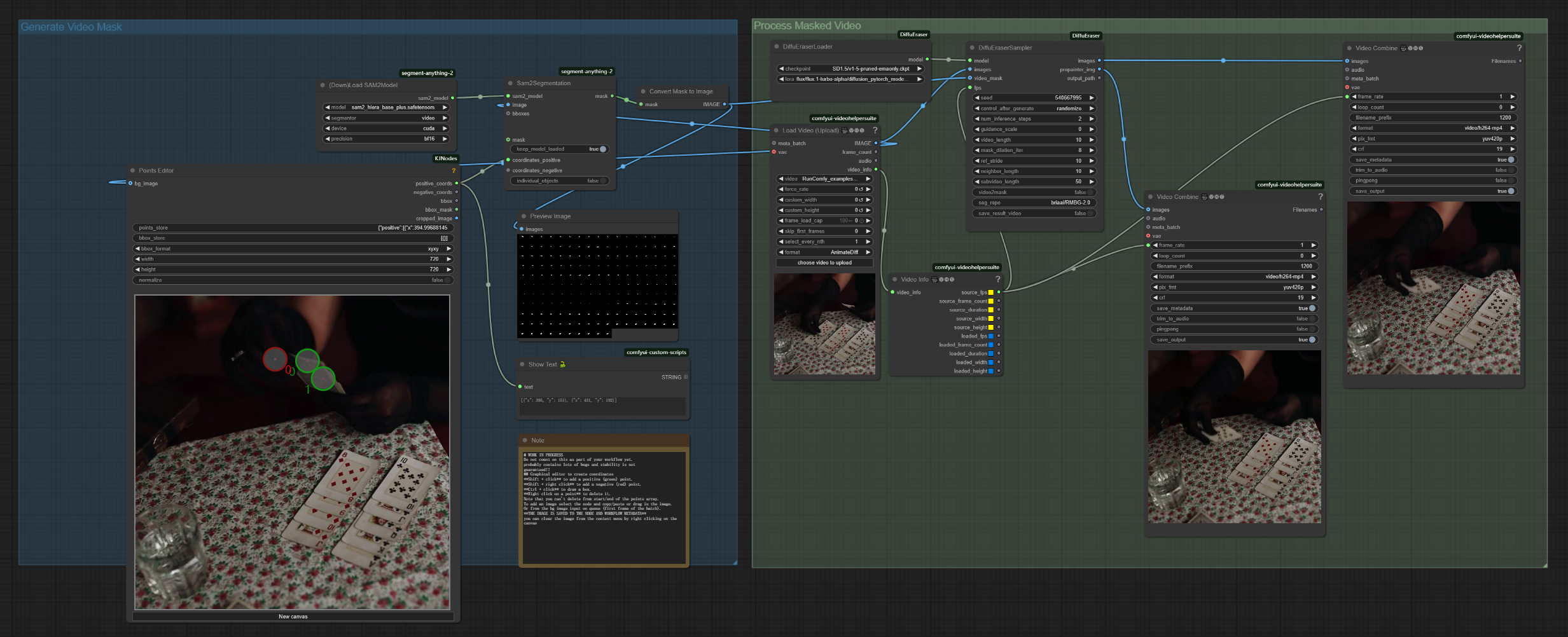
- 入力: オリジナルビデオ、ポイント座標によるオブジェクト選択用フレーム
- 最適な用途: オブジェクト、人、ウォーターマーク、その他不要な要素の除去
- 特徴:
- 自動マスク生成にSAM2を使用
- 高い視覚的忠実度で自然なインペインティングを実現
- 全てのフレームで時間的一貫性を保証
ワークフローの例#
- 入力を準備する
- Load Video Node: でソースビデオをアップロード
- Points Editor: で最初のフレームを読み込み、除去するオブジェクトをマークするために正のポイント(緑)を追加
- 調整(オプション)
- DiffuEraserSampler で
mask_dilation_iterを調整して正確なマスキングを行う - Video Combine で
crfを変更して出力品質を向上
- DiffuEraserSampler で
- 出力
- Video Combine: でプレビューを見つけてローカルマシンに保存
代替方法: 手動マスク作成#
- 入力: 事前に作成されたマスクビデオ。
- 最適な用途: マスク領域を正確に制御したいユーザー。
- 特徴:
- 手動でのマスク作成が必要。
- オブジェクト選択を完全に制御可能。
- 複雑なシーンやアーティスティックなワークフローに最適。
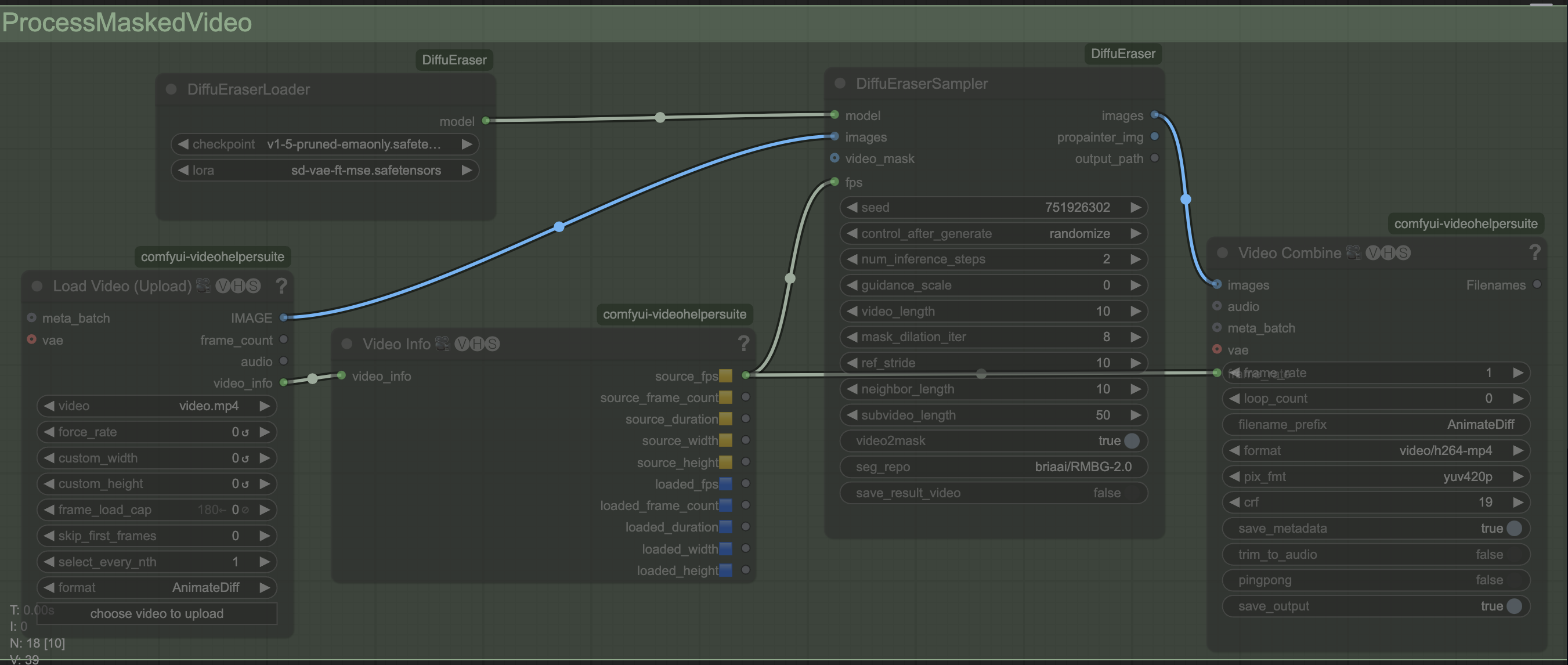
DiffuEraserのパラメータリファレンス#
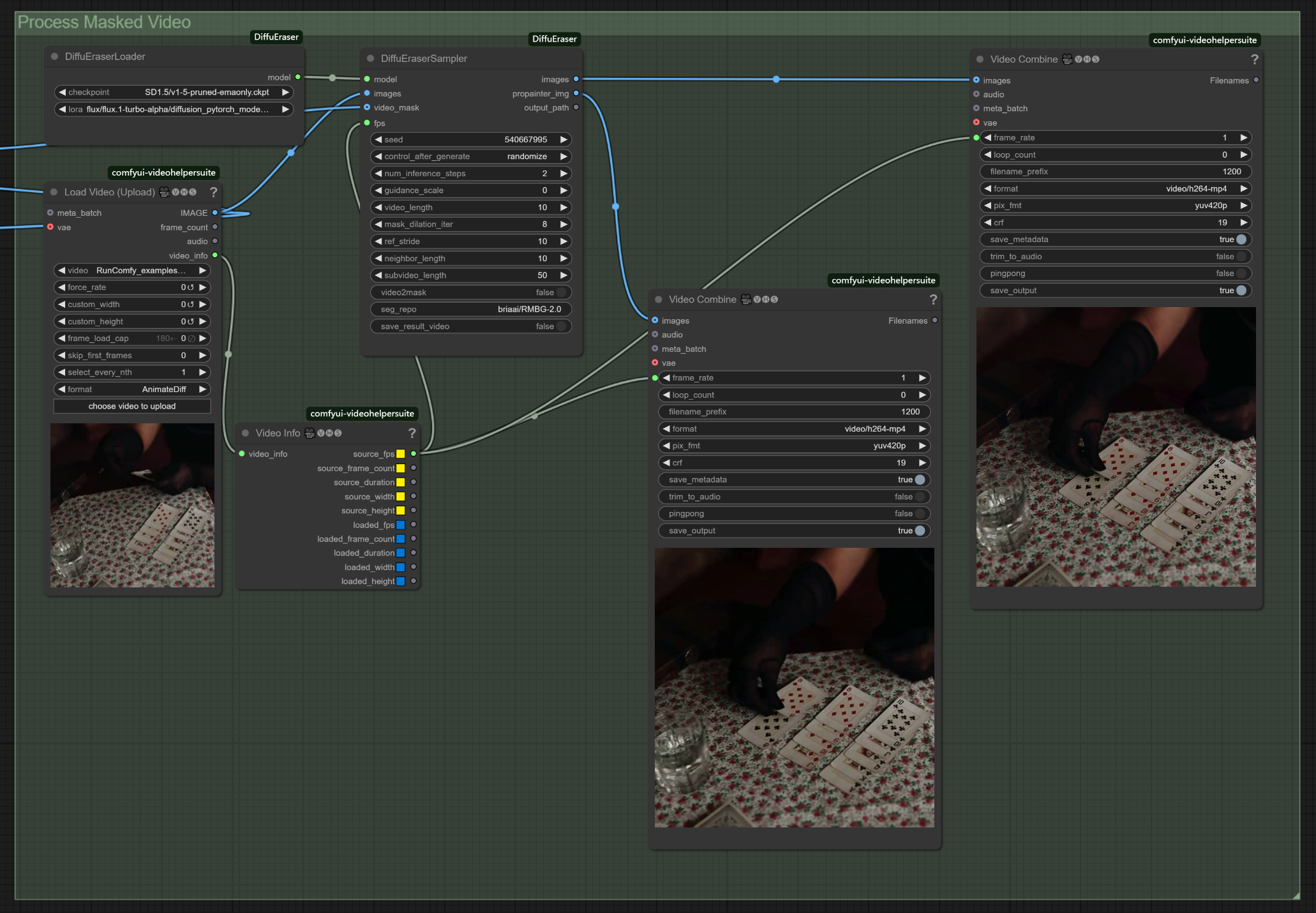
- DiffuEraserLoader:
checkpoint: [SD1.5/v1-5-pruned-emaonly.ckpt] - Stable Diffusionベースモデル。lora: [flux/flux.1-turbo-alpha/diffusion_pytorch_model.safetensors] - インペインティングを強化するLoRA。
- DiffuEraserSampler:
seed: [random] - 生成の変動性を制御。num_inference_steps: [2] - 値が高いほど品質が向上。guidance_scale: [0] - 事前情報への適合を制御。video_length: [10] - 処理されるフレームを定義。mask_dilation_iter: [8] - マスクカバレッジを拡大。ref_stride: [10] - 時間的一貫性のための参照フレームストライド。neighbor_length: [10] - 参照に使用されるフレームを定義。subvideo_length: [50] - バッチで処理される最大フレーム。seg_repo: [briaai/RMBG-2.0] - 背景除去モデル。
- Video Combine:
frame_rate: [1] - ソースのフレームレートに一致。format: [video/h264-mp4] - 出力フォーマット。crf: [19] - ビデオ圧縮品質を制御。
DiffuEraserによる高度な最適化#
- パフォーマンスの最適化:
- 処理時間を短縮するために
subvideo_lengthを減少。 - 生成速度を上げるために
num_inference_stepsを低下。
- 処理時間を短縮するために
- 品質向上:
- マスクカバレッジを向上させるために
mask_dilation_iterを増加。 - 動くオブジェクトの精度を向上させるために
neighbor_lengthを調整。
- マスクカバレッジを向上させるために
使用のヒント#
- Points Editor を使用して、ターゲットオブジェクトに複数のポイントをマークします。
- SAM2が不要な領域を含む場合は、負のポイント(赤) を追加します。
- 動くオブジェクト の場合、複数のフレームにわたってポイントをマークします。
- シンプルな背景は、より良いインペインティング結果をもたらします。
- メモリ問題を回避するために、長いビデオの
video_lengthとsubvideo_lengthを減らします。
詳細情報#
- DiffuEraserに関する詳細なガイドと更新については、DiffuEraser を訪問してください。
- DiffuEraserのComfyUI統合については、ComfyUI DiffuEraser を訪問してください。
- SAM2に関する詳細なガイドについては、SAM2 on RunComfy を訪問してください。
オリジナル作者へのクレジット#
DiffuEraserは、Alibaba GroupのTongyi LabのXiaowen Li、Haolan Xue、Peiran Ren、およびLiefeng Boによって作成され、ComfyUI統合はsmthemexによって行われました。Runcomfy CrewはSAM2による自動マスク生成でワークフローを強化しました。すべてのクレジットは、彼らの画期的な貢献に対するオリジナルの作者に帰属します。

