
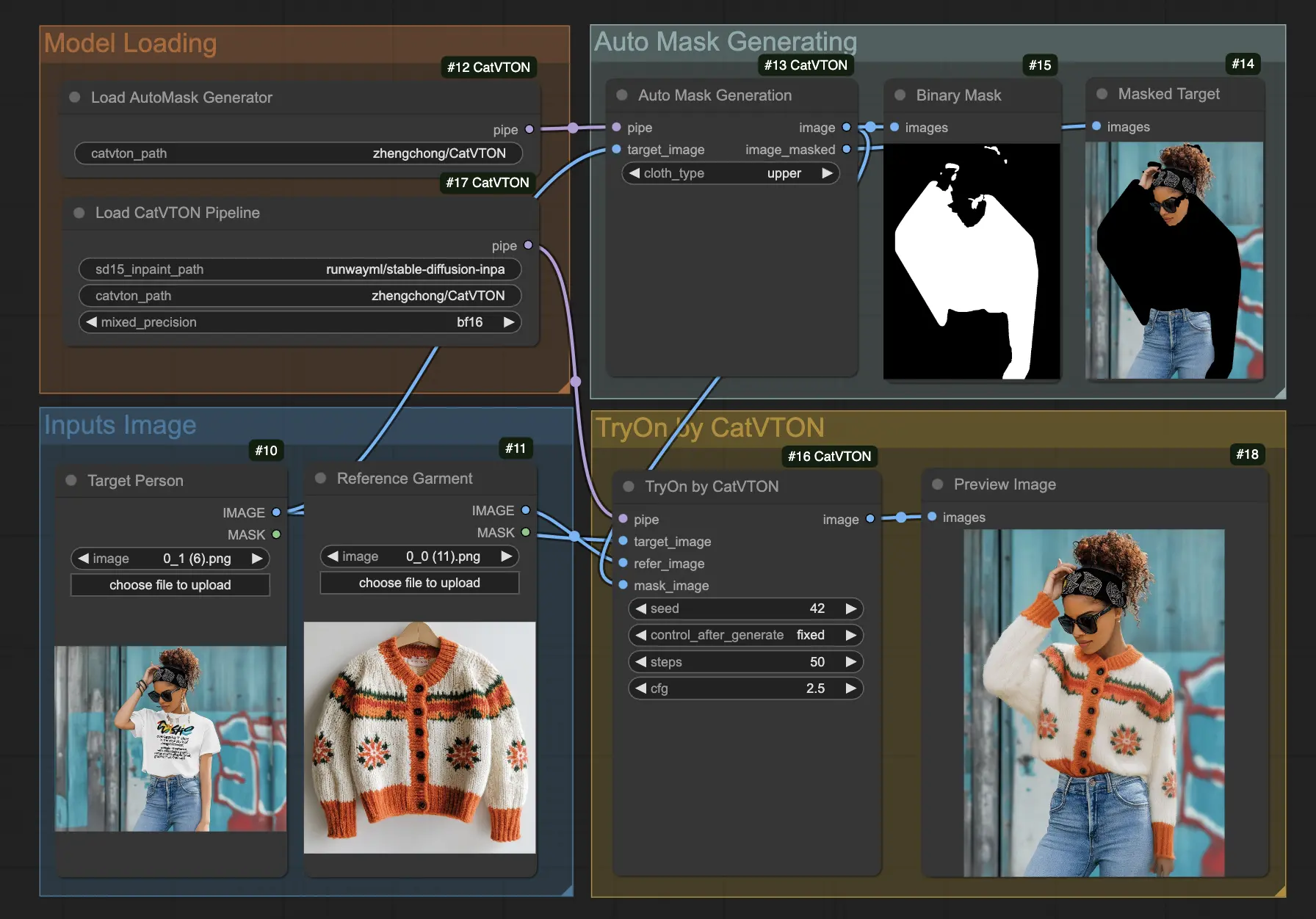



CatVTON (拡散モデルを使用したバーチャルトライオンへの革命的アプローチ)は、衣服と人の画像の空間的連結に依存するシンプルでありながら強力なアプローチを導入し、バーチャルトライオン技術の画期的な進歩を示しています。現在、ComfyUIワークフローとして利用可能であり、高品質のバーチャルトライオン画像の作成をこれまで以上に身近にしています。
1. CatVTONの理解#
CatVTONの核心は、そのエレガントにシンプルなアーキテクチャです。追加の画像エンコーダー、ReferenceNet、またはテキストエンコーダーのような複雑なコンポーネントに依存する従来のバーチャルトライオンソリューションとは異なり、CatVTONは本質的な拡散モジュールのみに焦点を当てることでプロセスを簡素化します。このミニマリストのアプローチにより、モデルのパラメータ数を大幅に削減するだけでなく、その効率とトレーニングプロセスを向上させます。
2. ComfyUIでのCatVTONの開始#
基本設定#
- 画像の準備
- 対象人物の鮮明な写真をアップロード
- 希望する衣服の参照画像を提供
- マスク生成
- "AutoMasker"ノードを使用
- 適切な衣服カテゴリを選択:
- 全体
- 上半身
- 下半身
- パラメータの設定
- 拡散ステップ:42ステップから始める
- 高い値:より高品質だが処理が遅い
- 低い値:処理が速いが品質が低下する可能性
- CFGスケール:50の値から始める
- 高い値:より正確な衣服転送
- 低い値:出力の多様性が増す
- 拡散ステップ:42ステップから始める
最適化のヒント#
最高の結果を得るために:
- 高解像度で明るい照明の画像を人と衣服の入力に使用
- 異なる衣服の組み合わせを試す
- 特定のニーズに基づいてパラメータを微調整
ライセンス情報#
CatVTONはCreative Commons BY-NC-SA 4.0ライセンスの下でリリースされています。つまり、あなたは以下のことができます:
- 素材を共有および適応
- 非商業目的で使用
- 適切な帰属を提供する必要があります
- 同じライセンス条件の下での変更を共有する必要があります
詳細情報および技術仕様については、公式CatVTONリポジトリをご覧ください。
素晴らしいバーチャルトライオンソリューションをお探しですか?CatVTONが答えです!CatVTONの世界に飛び込み、今日から素晴らしいバーチャルトライオン体験を作り始めましょう。RunComfyでは、すべてのモデルと環境を試していただく準備を整えています!楽しい作成を!
