
VOID Video Inpainting ComfyUI: rimozione degli oggetti consapevole delle interazioni per video puliti e coerenti#
Questo flusso di lavoro VOID Video Inpainting ComfyUI rimuove oggetti e le loro interazioni visive da un clip con coerenza temporale. Combina la segmentazione testuale SAM3 di Meta per definire la maschera con il video inpainting a due passaggi di Netflix VOID per riempire il vuoto nel tempo, producendo risultati che sembrano come se l'oggetto indesiderato e i suoi effetti vicini non fossero mai stati lì.
Creatori, editor e team VFX possono fare affidamento su VOID Video Inpainting ComfyUI quando la pulizia di un singolo fotogramma sfarfalla o si rompe attraverso il movimento. Il flusso di lavoro produce due clip: Pass 1 come intermedio veloce e Pass 2 come risultato raffinato con maggiore stabilità temporale. Fornisci un video sorgente, una breve frase SAM3 che descrive l'oggetto da rimuovere e un prompt di inpainting che descrive la scena che vuoi mantenere.
Modelli chiave nel flusso di lavoro ComfyUI VOID Video Inpainting ComfyUI#
- VOID: Cancellazione degli oggetti e delle interazioni video. Diffusione a due passaggi per la rimozione degli oggetti video con ragionamento temporale; l'implementazione di riferimento e i checkpoint sono forniti da Netflix. GitHub e Hugging Face
- Segment Anything Model 3.1 Multiplex (SAM3.1). Segmentazione delle immagini basata su testo e prompt utilizzata per generare la maschera dell'oggetto che guida l'inpainting. Hugging Face
- RAFT: Recurrent All-Pairs Field Transforms. Flusso ottico utilizzato per deformare il rumore da Pass 1 a Pass 2 in modo che il movimento rimanga coerente tra i fotogrammi. arXiv e pesi nel pacchetto modello VOID su Hugging Face
- CogVideoX VAE. Codec latente per codificare e decodificare i fotogrammi video durante l'inpainting. Hugging Face
- T5-XXL text encoder (fp16). Backbone linguistico che trasforma i prompt positivi e negativi in condizionamenti per il modello di diffusione. Hugging Face
Come usare il flusso di lavoro ComfyUI VOID Video Inpainting ComfyUI#
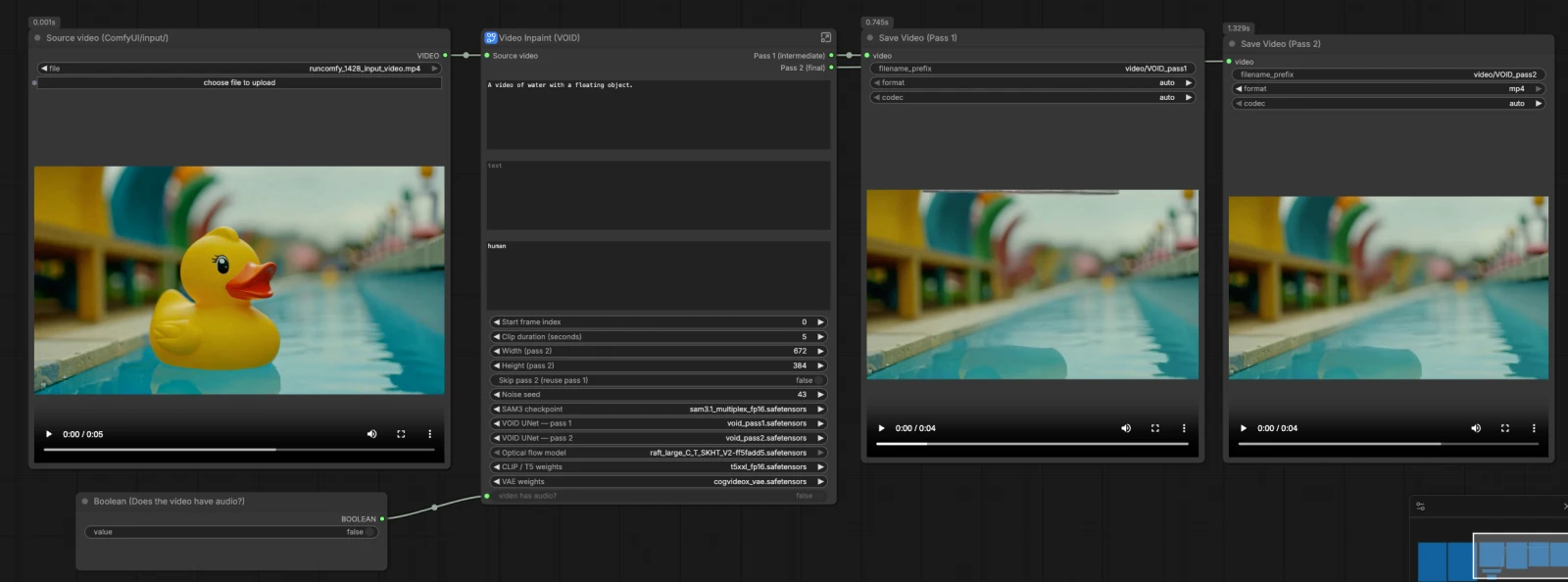
Questo grafico VOID Video Inpainting ComfyUI segue un percorso chiaro: carica i modelli e il clip sorgente, crea una maschera dell'oggetto con SAM3, costruisci un condizionamento condiviso dai tuoi prompt e dalla maschera, esegui il Pass 1 per stabilire il contenuto, quindi esegui il Pass 2 con rumore deformato per un movimento stabile. L'audio viene eventualmente tagliato per adattarsi al segmento elaborato. Il flusso di lavoro salva i video Pass 1 e Pass 2 in modo da poterli confrontare o spostarsi rapidamente.
Modelli#
Questo gruppo carica tutti i componenti richiesti per VOID Video Inpainting ComfyUI. CLIPLoader (#2) porta il codificatore di testo T5-XXL e VAELoader (#3) fornisce il CogVideoX VAE. UNETLoader (#144) inizializza il VOID UNet per il Pass 1 e UNETLoader (#143) imposta il VOID UNet per il Pass 2. OpticalFlowLoader (#142) carica il modello RAFT che successivamente guida la deformazione del rumore tra i passaggi.
Video di input (posiziona i file in ComfyUI/input/)#
Punta il caricatore Source video (ComfyUI/input/) al tuo clip, quindi GetVideoComponents (#166) lo divide in fotogrammi, audio e fps. ImageFromBatch (#145) seleziona un fotogramma rappresentativo per visualizzare l'anteprima della maschera. GetImageSize (#43) e nodi matematici semplici calcolano la lunghezza del clip e gli indici per un taglio coerente. Fornisci il fotogramma iniziale e la durata per mirare solo alla sezione che vuoi elaborare.
Creare Maschera#
Il sottografo Image Segmentation (SAM3) genera una maschera dell'oggetto per fotogramma per VOID Video Inpainting ComfyUI. SAM3_Detect (#75) utilizza il tuo prompt di testo SAM3 per segmentare l'oggetto sul fotogramma selezionato, con CLIPTextEncode (#78) che codifica la frase. La maschera è visualizzata in anteprima in MaskPreview (#132) in modo da poter verificare la copertura e perfezionare la formulazione se necessario. Una frase pulita e specifica come "tazza rossa sul tavolo" o "persona con giacca blu" aiuta SAM3 a isolare il soggetto giusto.
Condivisione: Condizionamento Testo & Maschera#
Prompt Positivo (CLIPTextEncode (#6)) dovrebbe descrivere la scena come dovrebbe apparire dopo la rimozione, non l'atto di rimozione. Prompt Negativo (CLIPTextEncode (#7)) elenca opzionalmente artefatti che non vuoi. VOIDInpaintConditioning (#10) fonde i prompt, VAE, fotogrammi in ingresso, la tua maschera SAM3 e le dimensioni target in un pacchetto di condizionamento latente utilizzato da entrambi i passaggi. Pensalo come dire a VOID cosa mantenere e come dovrebbero sentirsi il movimento e l'aspetto una volta che l'oggetto è sparito.
Pass 1: Campione (Rumore Casuale → DDIM)#
Pass 1 in VOID Video Inpainting ComfyUI stabilisce un riempimento plausibile utilizzando rumore casuale standard. RandomNoise (#141) semina il processo, BasicScheduler (#138) e VOIDSampler (#133) definiscono il programma di diffusione, e CFGGuider (#140) mescola i tuoi prompt nel modello. SamplerCustomAdvanced (#49) sintetizza il clip latente, e VAEDecode (#45) lo trasforma di nuovo in fotogrammi. CreateVideo (#46) allega eventualmente l'audio e scrive un video intermedio Pass 1 che puoi ispezionare prima del raffinamento.
Pass 2: Campione (Rumore Deformato → DDIM)#
Pass 2 migliora la stabilità temporale avviando con rumore deformato da Pass 1 piuttosto che con nuova casualità. VOIDWarpedNoise (#31) utilizza il flusso ottico RAFT con i fotogrammi Pass 1 per creare rumore allineato nel tempo, quindi VOIDWarpedNoiseSource (#32) lo alimenta nel campionamento. CFGGuider (#136), BasicScheduler (#137) e VOIDSampler (#134) impostano il secondo campionatore, e SamplerCustomAdvanced (#35) perfeziona il contenuto inpaintato. VAEDecode (#36) produce i fotogrammi finali. Se si attiva il salto, ComfySwitchNode (#150) indirizza i fotogrammi Pass 1 direttamente all'output per anteprime rapide.
Dimensione Video di Output#
I controlli di larghezza e altezza guidano la risoluzione latente per Pass 2 e il generatore di rumore deformato. Questi valori influenzano nitidezza, stabilità e carico di calcolo in VOID Video Inpainting ComfyUI. Scegli dimensioni che corrispondano ai tuoi obiettivi di contenuto e alla memoria disponibile. La stessa dimensione viene utilizzata costantemente in tutta la pipeline per mantenere allineati movimento e maschere.
Salta Pass 2#
Quando hai bisogno di un controllo rapido, usa il controllo di salto in modo che VOID Video Inpainting ComfyUI riutilizzi Pass 1 senza eseguire Pass 2. ComfySwitchNode (#150) seleziona automaticamente tra le immagini Pass 1 e Pass 2. Questo è utile per tagli approssimativi o quando stai iterando sulla formulazione della maschera o sui prompt. Riattiva Pass 2 per bloccare la coerenza temporale per il rendering finale.
Taglia Audio#
Se il tuo clip ha audio, VOID Video Inpainting ComfyUI lo taglia e lo riattacca in modo che la lunghezza dell'output corrisponda al segmento elaborato. TrimAudioDuration (#158) mantiene il suono sincronizzato, e ComfySwitchNode (#174) gestisce in sicurezza i clip silenziosi. L'fps da GetVideoComponents (#166) guida entrambi i nodi CreateVideo di Pass 1 e Pass 2 per evitare derive. Imposta correttamente l'interruttore "il video ha audio?" per ottenere il risultato previsto.
Nodi chiave nel flusso di lavoro ComfyUI VOID Video Inpainting ComfyUI#
SAM3_Detect (#75)#
Genera la maschera dell'oggetto da una breve frase SAM3. Se la maschera è troppo larga o stretta, perfeziona la formulazione per descrivere meglio il bersaglio e il suo contesto. Puoi anche regolare i controlli di perfezionamento interni per bordi nitidi quando necessario. Maschere forti rendono l'inpainting successivo più stabile.
VOIDInpaintConditioning (#10)#
Costruisce il pacchetto di condizionamento dal tuo prompt positivo, prompt negativo, VAE, fotogrammi e maschera SAM3. Il prompt positivo dovrebbe descrivere la scena che rimane; evita formulazioni come "rimuovi X". Usa il prompt negativo solo quando appaiono artefatti coerenti. I segnali latenti e di condizionamento risultanti alimentano entrambi i passaggi.
SamplerCustomAdvanced (#49) - Pass 1#
Esegue il campionamento VOID per il primo passaggio con rumore casuale. Il seed del rumore controlla la ripetibilità; cambialo quando vuoi un modello di riempimento diverso. Mantieni il campionatore e il pianificatore accoppiati con l'UNet di Pass 1. Ispeziona questo passaggio per convalidare la composizione e il movimento di base prima del raffinamento.
VOIDWarpedNoise (#31)#
Crea rumore temporaneamente allineato utilizzando il flusso ottico RAFT calcolato dai fotogrammi Pass 1. Questo preserva i segnali di movimento nel Pass 2 e riduce lo sfarfallio. Se il movimento sembra instabile, rivedi la qualità della maschera o prova un seed diverso in Pass 1 per generare una base migliore per la deformazione.
SamplerCustomAdvanced (#35) - Pass 2#
Perfeziona la regione inpaintata partendo dal rumore deformato. Usalo per bloccare le texture e stabilizzare i dettagli fini nel tempo. Quando gli output sono già stabili, puoi saltare Pass 2 per risparmiare tempo; altrimenti, mantienilo abilitato per la consegna finale.
ComfySwitchNode (#150) - Controllo di salto#
Commuta tra i fotogrammi Pass 1 e Pass 2 per l'output finale. Usalo per controllare A/B la qualità o per accelerare le iterazioni mentre regoli i prompt e la maschera SAM3. Disattivalo per il risultato definitivo di VOID Video Inpainting ComfyUI.
Extra opzionali#
- Scrivi prompt positivi per il mondo che vuoi vedere dopo la rimozione, ad esempio "bancone della cucina vuoto, luce del giorno, piastrelle pulite" piuttosto che "rimuovi tazza".
- Mantieni le frasi SAM3 specifiche, come "persona con giacca blu" o "tazza rossa sul tavolo", e riesegui dopo piccole modifiche per confermare la copertura nell'anteprima della maschera.
- Usa fotogramma iniziale e durata per limitare l'elaborazione alla sezione rilevante; i clip lunghi sono meglio gestiti in segmenti.
- Salta Pass 2 per le bozze, quindi abilitalo per la stabilizzazione finale in VOID Video Inpainting ComfyUI.
- Regola larghezza e altezza per bilanciare il dettaglio con la memoria GPU; risoluzioni più elevate appaiono più nitide ma richiedono più calcolo.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo calorosamente Netflix per il modello VOID, Comfy-Org per i file dei modelli VOID e SAM3.1, e RunComfy per la fonte del flusso di lavoro Cloud Save per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Netflix/void-model
- GitHub: netflix/void-model
- Comfy-Org/void-model
- Hugging Face: Comfy-Org/void-model
- Comfy-Org/sam3.1
- Hugging Face: Comfy-Org/sam3.1
- RunComfy/Cloud Save source
- Docs / Release Notes: Cloud Save source
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.