
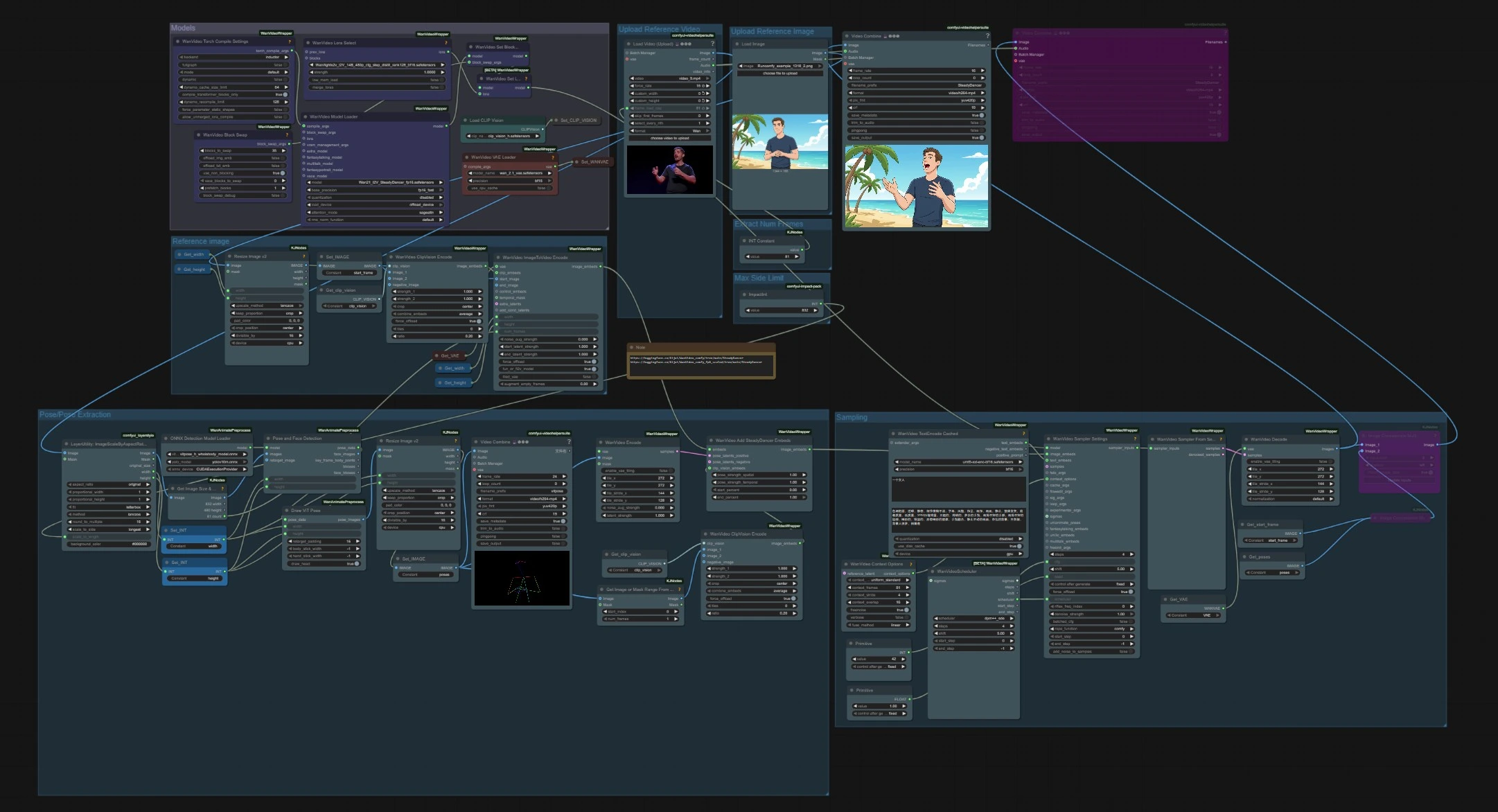
Flusso di lavoro di animazione delle pose da immagine a video di SteadyDancer#
Questo flusso di lavoro ComfyUI trasforma un'unica immagine di riferimento in un video coerente, guidato dal movimento di una fonte di pose separata. È costruito attorno al paradigma di immagine-a-video di SteadyDancer, quindi il primissimo fotogramma preserva l'identità e l'aspetto della tua immagine di input mentre il resto della sequenza segue il movimento target. Il grafico riconcilia pose e aspetto attraverso embed specifici di SteadyDancer e una pipeline di pose, producendo un movimento corporeo fluido e realistico con forte coerenza temporale.
SteadyDancer è ideale per l'animazione umana, la generazione di danza e per dare vita a personaggi o ritratti. Fornisci un'immagine fissa più una clip di movimento, e la pipeline ComfyUI gestisce l'estrazione delle pose, l'embedded, il campionamento e la decodifica per fornire un video pronto per la condivisione.
Modelli chiave nel flusso di lavoro Comfyui SteadyDancer#
- SteadyDancer. Modello di ricerca per la preservazione dell'identità da immagine a video con un Meccanismo di Riconciliazione delle Condizioni e Modulazione Sinergica delle Pose. Usato qui come metodo I2V principale. GitHub
- Pesi SteadyDancer Wan 2.1 I2V. Checkpoint portati per ComfyUI che implementano SteadyDancer sulla stack Wan 2.1. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) e Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. VAE video utilizzato per codificare e decodificare latenti all'interno della pipeline. Incluso con il port WanVideo su Hugging Face sopra.
- OpenCLIP CLIP ViT‑H/14. Codificatore di visione che estrae robusti embed di aspetto dall'immagine di riferimento. Hugging Face
- ViTPose‑H WholeBody (ONNX). Modello di punti chiave di alta qualità per corpo, mani e viso utilizzato per derivare la sequenza di pose guida. GitHub
- YOLOv10 (ONNX). Rilevatore che migliora la localizzazione delle persone prima della stima delle pose su video diversi. GitHub
- umT5‑XXL codificatore. Codificatore di testo opzionale per guida stilistica o scenica insieme all'immagine di riferimento. Hugging Face
Come usare il flusso di lavoro Comfyui SteadyDancer#
Il flusso di lavoro ha due input indipendenti che si incontrano al campionamento: un'immagine di riferimento per l'identità e un video guida per il movimento. I modelli vengono caricati una volta all'inizio, la pose viene estratta dalla clip guida, e gli embed di SteadyDancer fondono pose e aspetto prima della generazione e decodifica.
Modelli#
Questo gruppo carica i pesi principali utilizzati in tutto il grafico. WanVideoModelLoader (#22) seleziona il checkpoint SteadyDancer Wan 2.1 I2V e gestisce le impostazioni di attenzione e precisione. WanVideoVAELoader (#38) fornisce il VAE video, e CLIPVisionLoader (#59) prepara la spina dorsale di visione CLIP ViT‑H. Un nodo di selezione LoRA e opzioni BlockSwap sono presenti per utenti avanzati che vogliono cambiare il comportamento della memoria o allegare pesi aggiuntivi.
Carica Video di Riferimento#
Importa la fonte di movimento usando VHS_LoadVideo (#75). Il nodo legge fotogrammi e audio, permettendoti di impostare un frame rate target o limitare il numero di fotogrammi. La clip può essere qualsiasi movimento umano come una danza o un'azione sportiva. Il flusso video poi passa al ridimensionamento del rapporto d'aspetto e all'estrazione delle pose.
Estrarre Numero di Fotogrammi#
Una costante semplice controlla quanti fotogrammi vengono caricati dal video guida. Questo limita sia l'estrazione delle pose che la lunghezza dell'output SteadyDancer generato. Aumentalo per sequenze più lunghe, o riducilo per iterare più velocemente.
Limite Lato Massimo#
LayerUtility: ImageScaleByAspectRatio V2 (#146) ridimensiona i fotogrammi preservando il rapporto d'aspetto in modo che si adattino al passo e al budget di memoria del modello. Imposta un limite lungo adatto alla tua GPU e al livello di dettaglio desiderato. I fotogrammi ridimensionati vengono utilizzati dai nodi di rilevamento a valle e come riferimento per la dimensione dell'output.
Estrazione Pose/Pose#
Il rilevamento delle persone e la stima delle pose vengono eseguiti sui fotogrammi ridimensionati. PoseAndFaceDetection (#89) utilizza YOLOv10 e ViTPose‑H per trovare persone e punti chiave in modo robusto. DrawViTPose (#88) rende una rappresentazione pulita a figura stilizzata del movimento, e ImageResizeKJv2 (#77) dimensiona le immagini delle pose risultanti per adattarsi alla tela di generazione. WanVideoEncode (#72) converte le immagini delle pose in latenti in modo che SteadyDancer possa modulare il movimento senza opporsi al segnale di aspetto.
Carica Immagine di Riferimento#
Carica l'immagine di identità che desideri che SteadyDancer animi. L'immagine dovrebbe mostrare chiaramente il soggetto che intendi muovere. Usa una posa e un angolo di ripresa che corrispondano ampiamente al video guida per il trasferimento più fedele. Il fotogramma viene inviato al gruppo di immagini di riferimento per l'embed.
Immagine di riferimento#
L'immagine fissa viene ridimensionata con ImageResizeKJv2 (#68) e registrata come fotogramma di inizio tramite Set_IMAGE (#96). WanVideoClipVisionEncode (#65) estrae embed CLIP ViT‑H che preservano identità, abbigliamento e layout approssimativo. WanVideoImageToVideoEncode (#63) impacchetta larghezza, altezza e conteggio dei fotogrammi con il fotogramma di inizio per preparare il conditioning I2V di SteadyDancer.
Campionamento#
È qui che aspetto e movimento si incontrano per generare video. WanVideoAddSteadyDancerEmbeds (#71) riceve il conditioning dell'immagine da WanVideoImageToVideoEncode e lo arricchisce con latenti di pose più un riferimento CLIP‑vision, abilitando la riconciliazione delle condizioni di SteadyDancer. Le finestre di contesto e la sovrapposizione sono impostate in WanVideoContextOptions (#87) per la coerenza temporale. Facoltativamente, WanVideoTextEncodeCached (#92) aggiunge una guida testuale umT5 per suggerimenti stilistici. WanVideoSamplerSettings (#119) e WanVideoSamplerFromSettings (#129) eseguono i passaggi di denoising effettivi sul modello Wan 2.1, dopodiché WanVideoDecode (#28) converte i latenti di nuovo in fotogrammi RGB. I video finali vengono salvati con VHS_VideoCombine (#141, #83).
Nodi chiave nel flusso di lavoro Comfyui SteadyDancer#
WanVideoAddSteadyDancerEmbeds (#71)#
Questo nodo è il cuore di SteadyDancer nel grafico. Fonde il conditioning dell'immagine con latenti di pose e spunti CLIP‑vision in modo che il primo fotogramma blocchi l'identità mentre il movimento si svolge naturalmente. Regola pose_strength_spatial per controllare quanto strettamente gli arti seguono lo scheletro rilevato e pose_strength_temporal per regolare la fluidità del movimento nel tempo. Usa start_percent e end_percent per limitare dove il controllo delle pose si applica all'interno della sequenza per intros e outros più naturali.
PoseAndFaceDetection (#89)#
Esegue il rilevamento YOLOv10 e la stima dei punti chiave ViTPose‑H sul video guida. Se le pose mancano di arti piccoli o volti, aumenta la risoluzione dell'input a monte o scegli filmati con meno occlusioni e illuminazione più pulita. Quando sono presenti più persone, mantieni il soggetto target più grande nel fotogramma in modo che il rilevatore e la testa delle pose rimangano stabili.
VHS_LoadVideo (#75)#
Controlla quale porzione della fonte di movimento utilizzi. Aumenta il limite dei fotogrammi per output più lunghi o abbassalo per prototipare rapidamente. L'input force_rate allinea la spaziatura delle pose con il tasso di generazione e può aiutare a ridurre il balbettio quando l'FPS della clip originale è insolito.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
Mantiene i fotogrammi entro un limite di lato lungo scelto mantenendo il rapporto d'aspetto e il bucketing a una dimensione divisibile. Abbina la scala qui alla tela di generazione in modo che SteadyDancer non debba campionare o tagliare in modo aggressivo. Se vedi risultati morbidi o artefatti ai bordi, avvicina il lato lungo alla scala di allenamento nativa del modello per una decodifica più pulita.
WanVideoSamplerSettings (#119)#
Definisce il piano di denoising per il campionatore Wan 2.1. scheduler e steps impostano la qualità complessiva rispetto alla velocità, mentre cfg bilancia l'aderenza all'immagine più il prompt contro la diversità. seed blocca la riproducibilità, e denoise_strength può essere abbassato quando si desidera attenersi ancora più fedelmente all'aspetto dell'immagine di riferimento.
WanVideoModelLoader (#22)#
Carica il checkpoint SteadyDancer Wan 2.1 I2V e gestisce precisione, implementazione dell'attenzione e posizionamento del dispositivo. Lascia questi configurati per la stabilità. Gli utenti avanzati possono allegare un I2V LoRA per alterare il comportamento del movimento o alleggerire il costo computazionale durante gli esperimenti.
Extra opzionali#
- Scegli un'immagine di riferimento chiara e ben illuminata. Le viste frontali o leggermente angolate che somigliano alla telecamera del video guida fanno sì che SteadyDancer preservi l'identità in modo più affidabile.
- Preferisci clip di movimento con un unico soggetto prominente e minima occlusione. Sfondi affollati o tagli veloci riducono la stabilità delle pose.
- Se mani e piedi tremano, aumenta leggermente la forza temporale delle pose in
WanVideoAddSteadyDancerEmbedso aumenta l'FPS del video per densificare le pose. - Per scene più lunghe, elabora in segmenti con contesto sovrapposto e unisci gli output. Questo mantiene l'uso della memoria ragionevole e mantiene la continuità temporale.
- Usa i mosaici di anteprima integrati per confrontare i fotogrammi generati con il fotogramma di inizio e la sequenza delle pose mentre regoli le impostazioni.
Questo flusso di lavoro SteadyDancer ti offre un percorso pratico, end-to-end, da un'immagine fissa a un video guidato da pose fedele con identità preservata fin dal primo fotogramma.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine MCG-NJU per SteadyDancer per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
