
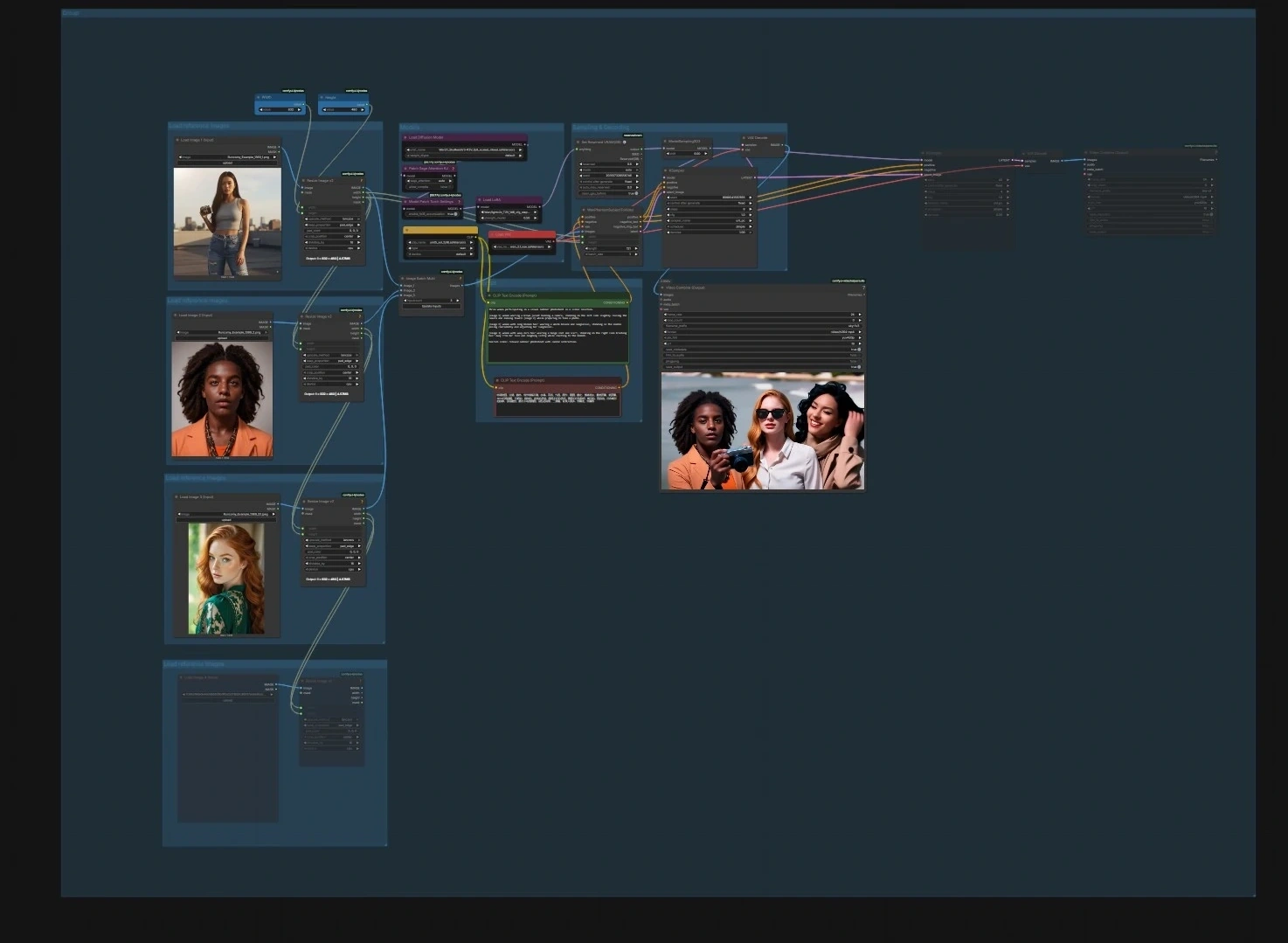
SkyReels V3 ComfyUI: creazione video da immagine, video e audio fedele all'identità#
SkyReels V3 ComfyUI è un workflow pronto per la produzione che porta il modello video multimodale SkyReels V3 in ComfyUI, così puoi animare immagini statiche, estendere riprese esistenti e costruire avatar parlanti guidati dall'audio con sincronizzazione labiale precisa. È progettato per creatori che vogliono movimento cinematografico, forte identità soggettiva e coerenza temporale rimanendo all'interno di un grafo di nodi flessibile.
Il workflow include quattro pipeline focalizzate che possono essere eseguite indipendentemente o concatenate: animazione del personaggio da immagine a video, continuazione video a video, avatar parlanti da audio a video, e generazione del prossimo scatto per il flusso della storia. Ogni percorso include punti di ingresso chiari e impostazioni predefinite sensate, così puoi inserire i tuoi asset e rendere rapidamente output SkyReels V3 di alta qualità.
Nota per macchine 2X Large e superiori (workflow R2V): Imposta
Patch Sage Attention KJ(#240)sage_attentionsudisabledprima di eseguire. Lasciandolo abilitato può causare erroriSM90 kernel is not available.
Modelli chiave nel workflow Comfyui SkyReels V3 ComfyUI#
- SkyReels V3 video backbones (R2V, V2V Shot, A2V) dal pacchetto WanVideo FP8. Questi sono i generatori principali che gestiscono il movimento consapevole dell'identità, la continuazione video e la sincronizzazione labiale condizionata dall'audio. Vedi i pesi SkyReels V3 nel pacchetto WanVideo su Hugging Face qui.
- Modelli OpenCLIP Vision ViT per la guida delle immagini e l'incorporamento di riferimento. Forniscono robuste caratteristiche visive che aiutano a preservare l'aspetto e lo stile attraverso i fotogrammi. Pagina del progetto: open_clip.
- Codificatore di testo UMT5 per la comprensione dei prompt. Fornisce un ricco condizionamento linguistico per guidare stile, scena e azioni. Repo: umt5.
- Caratteristiche vocali Wav2Vec2 per la sincronizzazione labiale e l'analisi audio. La variante base cinese è supportata di default e funzionano bene anche varianti simili in inglese. Scheda modello: TencentGameMate/chinese-wav2vec2-base.
- Qwen3‑ASR‑1.7B per il riconoscimento vocale. Utilizzato per trascrivere audio di riferimento e avviare prompt TTS clonati dalla voce. Scheda modello: Qwen/Qwen3-ASR-1.7B.
- MelBandRoFormer per la separazione vocale. Utile quando hai bisogno di tracce vocali pulite prima dell'incorporamento della sincronizzazione labiale. Scheda modello: Kijai/MelBandRoFormer_comfy.
- MiniCPM‑V per la generazione di prompt consapevoli del colpo. Analizza le riprese precedenti e propone il prossimo colpo per la continuità della storia. Hub del modello: OpenBMB/MiniCPM-V.
Come utilizzare il workflow Comfyui SkyReels V3 ComfyUI#
Il grafo è organizzato in quattro pipeline. Puoi eseguire una qualsiasi da sola o in sequenza per creare montaggi più lunghi.
Animazione del personaggio da Immagine a Video#
- Modelli. Carica l'UNet, CLIP e VAE nel gruppo Modelli usando
UNETLoader(#241),CLIPLoader(#242), eVAELoader(#194). I nodi patch del modelloPathchSageAttentionKJ(#240) eModelPatchTorchSettings(#239) ottimizzano le impostazioni di attenzione e matematica, mentreLoraLoaderModelOnly(#250) ti permette di fondere opzionalmente uno stile o un movimento LoRA nel modello SkyReels. - Carica immagini di riferimento. Usa i tre gruppi “Carica immagini di riferimento” per importare 1–3 ritratti o pose. Gli aiuti per il ridimensionamento
ImageResizeKJv2(#291, #298, #299, #304) allineano il rapporto d'aspetto e li raggruppano; foto di identità più pulite producono risultati più stabili. - Prompt. Inserisci testo di scena e azione nel gruppo Prompt con
CLIPTextEncode(#6) e un codificatore di testo negativo opzionaleCLIPTextEncode(#7) per allontanare tratti indesiderati. Mantieni il linguaggio conciso e specifico per movimento e inquadratura. - Campionamento e decodifica.
WanPhantomSubjectToVideo(#249) fonde i tuoi riferimenti e prompt in un latente consapevole dell'identità che alimentaKSampler(#149) attraversoModelSamplingSD3(#48). I fotogrammi decodificati daVAEDecode(#264) sono confezionati in un film conVHS_VideoCombine(#280); imposta lì il tuo frame rate e formato file di destinazione.
Loop di estensione Video a Video#
- Video di input e impostazioni. Porta nella tua clip sorgente con
VHS_LoadVideo(#329). Imposta quanti segmenti extra generare e quanto sovrapporre tra i segmenti usando gli aiuti interi “Number of Extend” (#342) e “Overlapping Frames” (#341).ImageResizeKJv2(#327) standardizza la risoluzione per il campionatore. - Estensione del video del campionamento del loop. La coppia di loop
easy forLoopStart(#331) eeasy forLoopEnd(#332) cammina sulla clip in finestre per stabilizzare le transizioni. Ogni finestra è codificata conWanVideoEncode(#326), riceve incorporamenti neutri o di controllo tramiteWanVideoEmptyEmbeds(#328), ed è denoised daWanVideoSampler(#320) daWanVideoModelLoader(#319). I fotogrammi sono decodificati conWanVideoDecode(#321) e visualizzati in anteprima o salvati conVHS_VideoCombine(#322, #335). - Aiuti per le prestazioni.
WanVideoTorchCompileSettings(#323) eWanVideoBlockSwap(#325) abilitano trucchi di compilazione e memoria per esecuzioni più lunghe o ad alta risoluzione.
Avatar parlante da Audio a Video#
- 1 – Crea audio. Puoi generare una traccia vocale clonata con
FB_Qwen3TTSVoiceClonePrompt(#416) eFB_Qwen3TTSVoiceClone(#412), o caricare qualsiasi voce preregistrata conLoadAudio(#417).Qwen3ASRLoader(#414) piùQwen3ASRTranscribe(#413) ti aiutano a estrarre testo da una clip di riferimento per avviare il prompt TTS se desiderato. - 2 – Caratteristiche audio.
DownloadAndLoadWav2VecModel(#348) alimentaMultiTalkWav2VecEmbeds(#350) per creare incorporamenti di movimento labiale dalla tua voce; la lunghezza è allineata all'audio e visualizzabile in anteprima conPreviewAudio(#422). UsaAny Switch (rgthree)(#435) per scegliere l'output TTS o il tuo file importato come traccia di guida. - 3 – Immagine di input. Carica il volto parlante nel gruppo “3 - Immagine di input” e dimensiona con
ImageResizeKJv2(#370). Ritratti puliti e frontali con illuminazione coerente funzionano meglio. - Gen. video di riferimento. Prima, crea un ancoraggio visivo breve dall'immagine statica usando
WanVideoImageToVideoEncode(#392). Le caratteristiche CLIP-Vision daCLIPVisionLoader(#352) eWanVideoClipVisionEncode(#351) stabilizzano l'identità nella fase successiva; uno schedulerWanVideoSchedulerv2(#385) è preparato nel gruppo Impostazioni di Campionamento. - Genera sincronizzazione labiale audio.
WanVideoImageToVideoSkyreelsv3_audio(#383) combina l'immagine iniziale, fotogrammi di riferimento opzionali e incorporamenti CLIP-Vision nel condizionamento delle immagini.WanVideoSamplerv2(#384) poi denoises con il modello SkyReels A2V mentreWanVideoSamplerExtraArgs(#386) inietta gli incorporamentiMultiTalkper forme labiali precise.WanVideoPassImagesFromSamples(#381) trasmette i fotogrammi decodificati aVHS_VideoCombine(#346) dove il video finale è muxato con il tuo audio.
Generazione del prossimo scatto Video a Video#
- Preprocessamento dei fotogrammi video. Importa lo scatto precedente con
VHS_LoadVideo(#443) e ridimensiona tramiteImageResizeKJv2(#441).GetImageRangeFromBatch(#445) seleziona una porzione di contesto cheWanVideoEncode(#440) trasforma in latenti;WanVideoEmptyEmbeds(#442) prepara la finestra di condizionamento. - Prompt video automatico.
CreateVideo(#450) assembla una clip proxy compatta dai fotogrammi di contesto cheAILab_MiniCPM_V_Advanced(#449) analizza per redigere un prompt del prossimo scatto. Ispeziona o affina il draft inShowText|pysssss(#447) e incorporalo conWanVideoTextEncodeCached(#444) prima del campionamento. - Modelli e campionamento. Carica il modello V2V Shot con
WanVideoModelLoader(#436) eWanVideoVAELoader(#438); opzionaleWanVideoBlockSwap(#439) gestisce la VRAM.WanVideoSampler(#451) genera la continuazione,WanVideoDecode(#437) rende i fotogrammi, eVHS_VideoCombine(#446) output il colpo finale. Questo percorso SkyReels V3 ComfyUI è ideale per storyboard e previz dove ogni nuovo taglio dovrebbe rispettare quello precedente.
Nodi chiave nel workflow Comfyui SkyReels V3 ComfyUI#
WanPhantomSubjectToVideo(#249). Costruisce un latente consapevole dell'identità dalle tue immagini di riferimento raggruppate più i suggerimenti di testo, che poi guida il campionatore. Regola il numero e la diversità dei riferimenti per bilanciare il blocco della somiglianza rispetto al movimento creativo; mantieni i nodi di ridimensionamento che lo alimentano coerenti per evitare derive. Riferimento: WanVideo Wrapper su GitHub contiene note di implementazione e input attesi ComfyUI‑WanVideoWrapper.WanVideoImageToVideoEncode(#392). Codifica un'immagine statica in un seme di ripresa stabile e opzionalmente fonde la guida CLIP-Vision per posa e inquadratura. Usalo per creare fotogrammi di ancoraggio prima della fase guidata dall'audio in modo che l'identità e l'impostazione della fotocamera rimangano coerenti tra le pipeline. Documenti del wrapper: ComfyUI‑WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). Prepara incorporamenti di immagini su misura per il campionatore A2V e fonde opzionalmente fotogrammi video di riferimento. Assicurati che la sua larghezza e altezza corrispondano al percorso del campionatore; abbinalo aWanVideoSamplerv2eMultiTalkWav2VecEmbedsper sincronizzazione labiale precisa.WanVideoSamplerv2(#384, #387). Il principale denoiser per SkyReels V3 che accetta incorporamenti di immagini e testo più impostazioni dello scheduler. I nodiWanVideoSamplerExtraArgs(#386, #409) sono dove vengono iniettate caratteristiche di sincronizzazione labiale, loop o contesto; mantienili collegati quando si passa tra i modelli A2V e I2V. Dettagli di implementazione: ComfyUI‑WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). Converte la voce in incorporamenti allineati temporalmente che guidano il movimento della bocca. Abbinare il budget dei fotogrammi previsto e garantire voci pulite migliora significativamente l'accuratezza dei fonemi. Modello di riferimento Wav2Vec: TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). Analizza il colpo precedente e redige un prompt strutturato per personaggio, sfondo, azione, umore e illuminazione. Usalo per mantenere la continuità narrativa quando si utilizza il percorso successivo V2V; il testo risultante fluisce inWanVideoTextEncodeCached. Famiglia di modelli: OpenBMB/MiniCPM-V.
Extra opzionali#
- Mantieni le risoluzioni di immagine, video e campionatore coerenti tra i nodi collegati per evitare distorsioni dell'aspetto e sfarfallio dell'identità.
- Per estensioni più lunghe, aumenta la sovrapposizione delle finestre nel loop di estensione V2V per rendere più fluide le transizioni tra i segmenti.
- Se la memoria GPU è limitata, lascia abilitati i nodi Reserved VRAM (
ReservedVRAMSetter(#312, #448)) e utilizza i blocchi delle impostazioni di compilazione prima del campionamento. - Quando gli avatar parlanti vanno fuori tempo, dai priorità a voci pulite o separa le vocali con MelBandRoFormer prima di creare gli incorporamenti
MultiTalk. - Le impostazioni di consegna finale come frame rate, formato pixel e CRF sono controllate nei nodi di output
VHS_VideoCombine; abbina il frame rate alla tua sorgente per montaggi senza soluzione di continuità.
Questo README copre l'intero grafo SkyReels V3 ComfyUI, così puoi scegliere il percorso che si adatta al tuo progetto, combinarli quando necessario e rendere video pronti per la storia con il minimo tentativo ed errore.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine il @Benji’s AI Playground e SkyReels per il workflow SkyReels V3 ComfyUI per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- SkyReels/V3 ComfyUI Source
- Documenti / Note di rilascio: SkyReels V3 ComfyUI Source from @Benji’s AI Playground
Nota: l'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
