
Trasferimento del movimento del personaggio SCAIL-2: flusso di lavoro da immagine di riferimento a video lungo#
Questa pipeline ComfyUI trasforma una singola immagine di riferimento in una lunga performance del personaggio fedele all'identità prendendo in prestito il movimento da un video di guida. Costruito sul percorso SCAIL-2 Wan 2.1 14B con condizionamento CLIP Vision, mascheramento persona basato su SAM e accelerazione LightX2V, è ottimizzato per la stabilità su sequenze lunghe e facile ispezione affiancata. È un pratico flusso di lavoro di trasferimento del movimento del personaggio SCAIL-2 da immagine di riferimento a video lungo per creatori che necessitano di identità, guardaroba e stile coerenti su centinaia di fotogrammi.
Usalo per generare test di movimento in stile catalogo, dimostrazioni da immagine di riferimento a video ed esempi di video di mercato editoriale occidentale. Il flusso di lavoro supporta la guida opzionale di riluminazione in modo che il soggetto possa essere armonizzato con la scena di guida mantenendo i dettagli del viso e del vestito allineati con la tua immagine di riferimento.
Modelli chiave nel flusso di lavoro di trasferimento del movimento del personaggio SCAIL-2 ComfyUI da immagine di riferimento a video lungo#
- SCAIL-2 su Wan 2.1 14B. Diffusione video consapevole dell'identità principale utilizzata per il trasferimento del movimento. Il flusso di lavoro carica i pesi 14B SCAIL-2 confezionati per ComfyUI e li abbina a un Wan VAE per la ricostruzione. Vedi la raccolta di modelli in Comfy-Org/SCAIL-2 e la panoramica del metodo in zai-org/SCAIL.
- OpenCLIP ViT-H/14 per CLIP Vision. Estrae robuste incorporazioni di identità e aspetto dall'immagine di riferimento per condizionare la generazione, migliorando la fedeltà del personaggio attraverso i fotogrammi. Famiglia di modelli di riferimento: laion/CLIP-ViT-H-14-laion2B-s32B-b79K.
- Segment Anything (SAM) family. Fornisce maschere per persone e tracce per fotogramma che localizzano il soggetto sia nel video di guida che nell'immagine di riferimento, consentendo un condizionamento mirato. Riferimento del progetto: facebookresearch/segment-anything.
- LightX2V LoRA e WanAnimate Relight LoRA. Adattatori opzionali che il flusso di lavoro carica per accelerare l'inferenza da fotogramma a fotogramma e offrire guida di riluminazione in modo che il personaggio trasferito corrisponda all'illuminazione del clip di guida.
Come utilizzare il flusso di lavoro di trasferimento del movimento del personaggio SCAIL-2 ComfyUI da immagine di riferimento a video lungo#
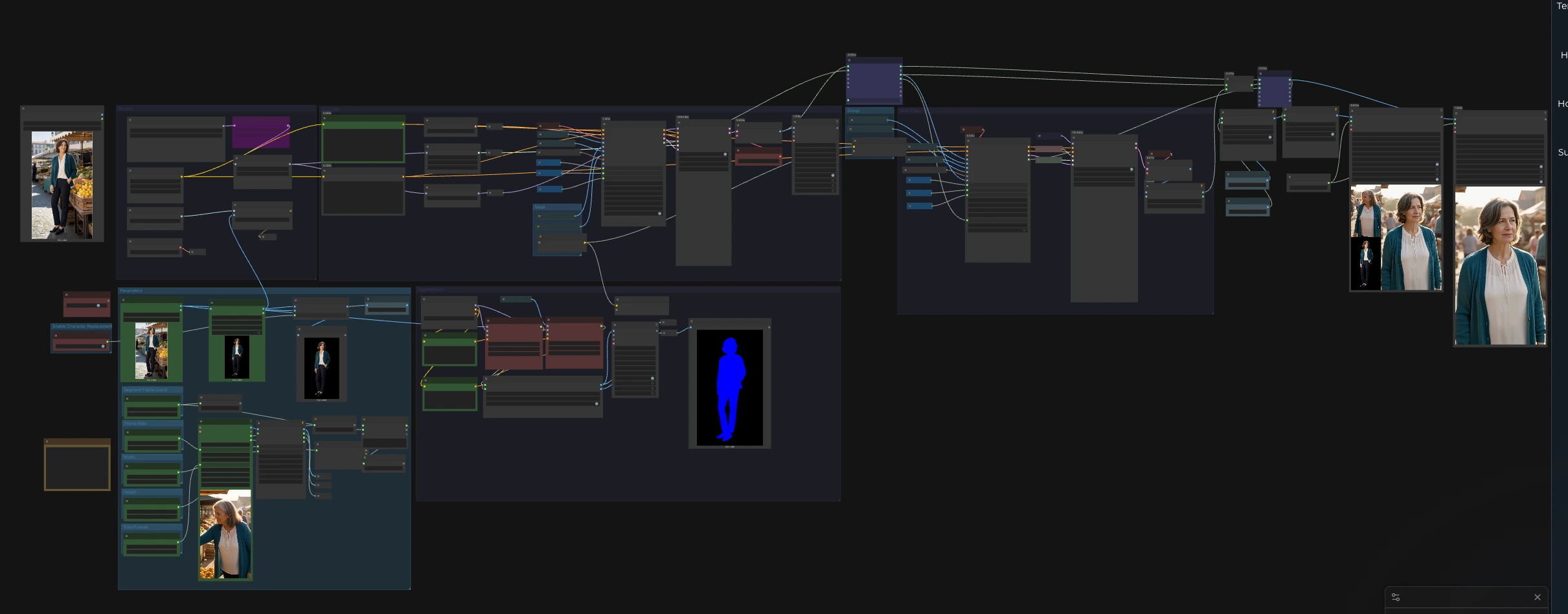
A un livello elevato, fornisci un'immagine di riferimento e un video di guida. Il gruppo di segmentazione trova e maschera la persona in entrambe le fonti, CLIP Vision codifica l'identità di riferimento, un primo passaggio genera un segmento iniziale e un ciclo Multi-Pass applica quella logica di segmentazione all'intera linea temporale per fornire un video lungo e coerente. I pannelli di anteprima affiancati rendono facile ispezionare l'allineamento dell'identità e della posa.
Modelli#
Questo gruppo inizializza i modelli di base e gli adattatori opzionali. L'UNet carica il checkpoint SCAIL-2 Wan 2.1 14B e il VAE gestisce la decodifica latente per i fotogrammi video. Il flusso di lavoro carica anche CLIP Vision per le incorporazioni di identità e due adattatori LoRA: LightX2V per la velocità e WanAnimate Relight per la guida dell'illuminazione. I prompt di testo sono codificati dallo stack di testo Wan per spingere scena e tono, il che è conveniente quando si crea un esempio di mercato editoriale occidentale.
Parametri#
Usa il gruppo di Parametri per impostare i controlli a livello di progetto. La risoluzione è esposta in modo da poter scegliere una base veloce o un'impostazione più nitida che si adatta al tuo budget GPU. Il frame rate regola come il video di guida viene campionato e come l'output viene codificato per la riproduzione. La lunghezza del segmento definisce quanti fotogrammi contiene ciascun blocco di inferenza, mantenendo prevedibile la memoria su linee temporali lunghe. È disponibile un limite finale di fotogrammi per limitare l'elaborazione durante lo sviluppo dell'aspetto prima di eseguire il clip completo.
Segmentazione#
Il gruppo di segmentazione prepara una guida pulita e mirata per il trasferimento del movimento. VHS_LoadVideo (#33) importa il video di guida e i fotogrammi vengono ridimensionati alla risoluzione scelta in modo che corrispondano al percorso SCAIL-2. Due tracciatori, SAM3_VideoTrack (#85) per il video della posa e SAM3_VideoTrack (#91) per il riferimento, eseguono il rilevamento delle persone guidato da un semplice condizionamento testuale "person" per aumentare il richiamo. SCAIL2ColoredMask (#104) unisce le tracce in due maschere coerenti, una per il video della posa e una per l'immagine di riferimento, che i nodi di generazione consumano per mantenere le modifiche focalizzate sul soggetto.
Primo Passaggio#
Il primo passaggio avvia la sequenza e stabilisce il blocco dell'identità. CLIPVisionEncode (#76) estrae le incorporazioni dall'immagine di riferimento, quindi WanSCAILToVideo (#114) combina quelle incorporazioni con il video della posa e le due maschere per produrre una sequenza latente per il primo segmento. Una semplice pila di campionatori SamplerCustom (#19) con BasicScheduler (#18) rende questo latente in immagini, decodificato da VAEDecode (#6). Questo passaggio espone anche un offset di fotogramma che la fase Multi-Pass utilizza per allineare i blocchi successivi.
Multi-Pass#
Il gruppo Multi-Pass scala l'esecuzione a video lunghi senza perdere coerenza. Un paio di for-loop, easy forLoopStart (#233) e easy forLoopEnd (#234), itera sull'intera linea temporale in segmenti di dimensioni fisse mentre passa i fotogrammi decodificati in avanti come contesto temporale. WanSCAILToVideo (#115) consuma quel contesto tramite il suo input previous_frames, migliorando la continuità del viso, dei capelli e del guardaroba attraverso i confini dei segmenti. La pila di campionatori SamplerCustom (#63) è guidata dal campionatore scelto e dal programma sigma in modo da poter bilanciare velocità e aderenza, e VAEDecode (#66) restituisce ogni blocco come immagini. Il flusso di lavoro quindi cuce insieme gli intervalli e li prepara per l'esportazione.
Maschera#
Il gruppo Maschera instrada le maschere delle persone calcolate nella segmentazione in modo che sia i nodi del primo passaggio che quelli del Multi-Pass ricevano le regioni corrette del soggetto. Get_pose_video_mask (#122) e Get_reference_image_mask (#120) assicurano che il trasferimento di stile e la conservazione dell'identità siano applicati esattamente dove necessario, riducendo la deriva dello sfondo e proteggendo i dettagli della scena al di fuori del soggetto.
Abilitare la Sostituzione del Personaggio#
Questo gruppo ti consente di passare tra il trasferimento dell'identità che rispetta lo sfondo originale e la sostituzione completa del primo piano. easy imageRemBg (#204) rimuove lo sfondo dall'immagine di riferimento, e ImpactConditionalBranch (#270) alterna se il primo piano pulito viene utilizzato a valle. Abilitalo quando vuoi uno scambio rigoroso del personaggio, utile per test simili a cataloghi o un esempio di mercato editoriale occidentale in cui un soggetto deve corrispondere a un look standardizzato.
Anteprima ed esportazione#
Il flusso di lavoro offre visualizzazione affiancata e rendering finali. ImageConcatMulti (#153) compone un pannello rapido che mostra i fotogrammi della posa di guida e l'immagine di riferimento per controlli di realtà. Un altro ImageConcatMulti (#72) può visualizzare l'output del modello accanto agli input per QA fotogramma per fotogramma. I video finali sono scritti da VHS_VideoCombine (#71) e VHS_VideoCombine (#236), che possono includere l'audio dalla fonte se desiderato in modo che le recensioni rimangano fedeli al timing.
Nodi chiave nel flusso di lavoro di trasferimento del movimento del personaggio SCAIL-2 ComfyUI da immagine di riferimento a video lungo#
WanSCAILToVideo (#114)#
Genera il segmento latente iniziale fondendo fotogrammi di posa, maschere del soggetto e incorporazioni di identità CLIP Vision dall'immagine di riferimento. Regola pose_strength per bilanciare tra copiare il movimento esatto e consentire un adattamento stilistico sottile. Usa length per adattare la dimensione del segmento in modo che il campionatore elabori un blocco prevedibile a ogni passaggio. Se stai sostituendo rigorosamente la persona sullo schermo, imposta replacement_mode per favorire l'identità rispetto allo stile di sfondo. Supportato da SCAIL-2 su Wan 2.1 14B come confezionato in Comfy-Org/SCAIL-2 con contesto del metodo da zai-org/SCAIL.
WanSCAILToVideo (#115)#
Funziona durante il ciclo per coprire il resto della linea temporale con una stabilità temporale migliorata. Fornisci previous_frames dal segmento precedente per aiutare il modello a mantenere dettagli di abbigliamento e identità facciale stabili attraverso i confini. video_frame_offset e previous_frame_count mantengono i segmenti sincronizzati con il clip di guida. Quando la guida di riluminazione è abilitata tramite il LoRA, spingi leggermente più forte l'abbinamento stilistico in questo passaggio per armonizzare l'illuminazione globale.
SAM3_VideoTrack (#85, #91)#
Rileva e traccia la persona sia nel video della posa che nell'immagine di riferimento. Il condizionamento testuale "person" migliora la robustezza quando sono presenti più oggetti. Se il tracciatore si sposta, aumenta la fiducia nel rilevamento o limita max_objects in modo che lo stesso soggetto venga selezionato durante tutto il processo. Il concetto di tracciamento segue la famiglia Segment Anything, vedere facebookresearch/segment-anything per ulteriori informazioni.
CLIPVisionEncode (#76)#
Produce l'incorporazione dell'identità di riferimento che condiziona ogni fotogramma. Per riferimenti a testa e spalle, mantieni crop a una scelta neutra in modo che l'encoder veda l'intera silhouette e l'outfit. Se il soggetto è piccolo nel fotogramma, prepara un'immagine di riferimento più stretta invece di ritagliare eccessivamente nel nodo. Questo nodo si basa su caratteristiche di visione in stile OpenCLIP ViT-H/14 come in laion/CLIP-ViT-H-14-laion2B-s32B-b79K.
VHS_LoadVideo (#33)#
Importa e opzionalmente ricampiona il video di guida per una tempistica coerente. Abbina force_rate al ritmo di output desiderato, quindi mantienilo fisso durante lo sviluppo dell'aspetto per ottenere risultati comparabili tra le iterazioni. Usa il limite opzionale di fotogrammi durante i test per accelerare i tempi di risposta, quindi sollevalo per i rendering finali.
Extra opzionali#
- Per iterazioni rapide scegli una risoluzione adatta ai ritratti, quindi sali di livello quando approvi i finali. Il flusso di lavoro è ottimizzato per le impostazioni tipiche 9:16, con un'opzione più alta disponibile quando la memoria GPU lo consente.
- Scrivi suggerimenti che descrivono guardaroba, età e ambientazione in linguaggio semplice per allinearsi alle norme degli esempi di mercato editoriale occidentale, ad esempio "una persona di mezza età in un maglione blu in una cucina luminosa".
- Se l'outfit del soggetto deve essere esatto, abbassa i suggerimenti artistici e aumenta l'affidamento sulla maschera in modo che il sistema dia priorità a indumenti e colore rispetto all'umore dello sfondo.
- Usa la Sostituzione del Personaggio quando vuoi uno scambio rigoroso della persona sullo schermo. Lascialo spento quando vuoi che il modello armonizzi delicatamente il personaggio con la scena.
- Evita occlusioni pesanti o tagli veloci nel video di guida. Un movimento della telecamera moderato e un movimento pulito e frontale producono il trasferimento di identità più stabile.
- Quando aggiungi la guida di riluminazione, inizia in modo conservativo in modo che toni della pelle e materiali rimangano naturali pur mantenendo la direzione della luce della scena.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo zai-org e teal024 per SCAIL/SCAIL-2, Comfy-Org per i file del modello SCAIL-2 e il checkpoint Wan 2.1 14B FP8, e i team RunningHub e RunComfy per i riferimenti al flusso di lavoro e il flusso di lavoro di salvataggio su cloud per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/Workflow Reference
- Docs / Note di Rilascio: RunningHub workflow reference
- zai-org/SCAIL-2 Project
- GitHub: zai-org/SCAIL
- teal024/SCAIL Project Page
- Docs / Note di Rilascio: SCAIL project page
- zai-org/SCAIL-2
- Hugging Face: zai-org/SCAIL-2
- Comfy-Org/SCAIL-2
- Hugging Face: Comfy-Org/SCAIL-2
- Comfy-Org/SCAIL-2 Wan 2.1 14B FP8 checkpoint
- Hugging Face: wan2.1_14B_SCAIL_2_fp8_scaled.safetensors
- RunComfy/Cloud Save Workflow
- Docs / Note di Rilascio: [RunComfy Cloud Save workflow](json
https://www.runcomfy.com/comfyui-workflows/my-workflows?shared_workflow=1f200078-7913-6599-2cf9-35462cfa2fdb)
Note: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.