
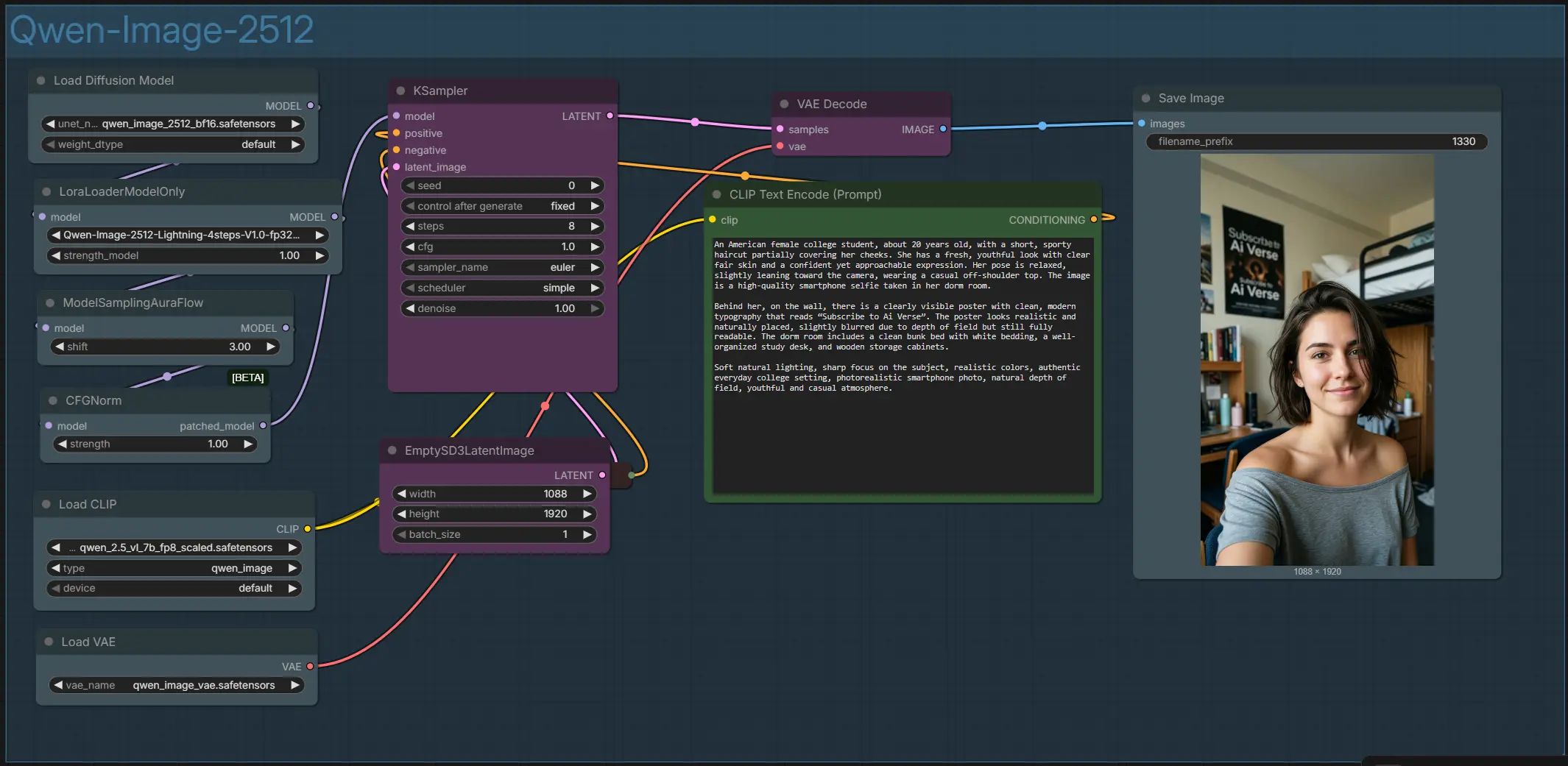






Flusso di lavoro Qwen Image 2512 ComfyUI per ritratti e scene testualmente accurati#
Questo flusso di lavoro trasforma il tuo prompt in un'immagine ad alta fedeltà utilizzando Qwen Image 2512. È progettato per creatori che necessitano di un forte allineamento testo-immagine, persone realistiche e un affidabile rendering di testi bilingue all'interno della scena. Il grafico viene preconfigurato con il VAE e l'encoder di testo di Qwen, oltre a un Lightning LoRA opzionale per la generazione in pochi passaggi, in modo da passare dal prompt al risultato con un setup minimo.
Utilizzalo per concept art, illustrazione, segnaletica, poster e stili fotografici quotidiani. Qwen Image 2512 offre una composizione stabile e una tipografia nitida, rendendolo una scelta solida per prompt che mescolano persone, ambienti e testo leggibile.
Modelli chiave nel flusso di lavoro Comfyui Qwen Image 2512#
- Modello base Qwen-Image 2512 (bfloat16). Modello di diffusione principale che sintetizza l'immagine dal condizionamento. I pesi pronti per Comfy sono forniti nel pacchetto Comfy-Org. Model files
- Encoder di testo Qwen2.5‑VL 7B. Codifica il tuo prompt in vettori di condizionamento che guidano il layout, lo stile e il rendering del testo di Qwen Image 2512. Text encoder files
- VAE di Qwen Image. Decodifica il latente prodotto dal campionatore in un'immagine RGB con colore e dettaglio fedeli. VAE file
- LoRA Qwen‑Image‑2512‑Lightning‑4steps‑V1.0 (opzionale). Un LoRA della comunità ottimizzato per la generazione in pochi passaggi per accelerare il rendering con minori compromessi sulla qualità. LoRA card
- Per informazioni di base sulla famiglia di modelli e l'approccio di addestramento, vedere il rapporto tecnico di Qwen‑Image. Paper
Come utilizzare il flusso di lavoro Comfyui Qwen Image 2512#
Flusso generale: il tuo prompt viene codificato, una tela latente viene creata alla risoluzione scelta, la pila di modelli applica il modello base e il LoRA opzionale, il campionatore itera per affinare il latente e il VAE decodifica l'immagine finale per il salvataggio.
- Panoramica del gruppo Qwen‑Image‑2512
- L'intero grafico è organizzato all'interno di un singolo gruppo chiamato "Qwen‑Image‑2512". Collega insieme l'encoder di testo, la pila di modelli e LoRA, gli assistenti di campionamento e la decodifica VAE. Controlli l'aspetto con i tuoi prompt positivi e negativi, la dimensione della tela e alcune impostazioni del campionatore. L'output è un'immagine in stile ritratto ad alta risoluzione salvata nella tua cartella di output ComfyUI.
- Prompt con
CLIPTextEncode(#52) e negativi opzionaliCLIPTextEncode(#32)- Inserisci la tua descrizione principale in
CLIPTextEncode(#52). Scrivi la scena, i soggetti e qualsiasi testo all'interno dell'immagine che desideri venga reso; Qwen Image 2512 è particolarmente forte nella segnaletica, poster, mockup UI e didascalie bilingue. UsaCLIPTextEncode(#32) per negativi opzionali per allontanarti da artefatti o stili indesiderati. Mantieni i frammenti di testo tra virgolette se hai bisogno di una formulazione precisa.
- Inserisci la tua descrizione principale in
- Tela e rapporto d'aspetto con
EmptySD3LatentImage(#57)- Scegli la tua larghezza e altezza target qui per impostare la composizione. I formati ritratto funzionano bene per persone e selfie, mentre i rapporti quadrati e paesaggistici si adattano ai layout di prodotti e scene. Telai più grandi offrono maggiori dettagli a costo di memoria e tempo; inizia modesto, poi scala una volta che ti piace l'inquadratura. La coerenza migliora quando mantieni lo stesso rapporto d'aspetto attraverso le iterazioni.
- Modello e pila LoRA con
UNETLoader(#100) eLoraLoaderModelOnly(#101)- Il generatore base è Qwen Image 2512 caricato da
UNETLoader(#100). Se desideri rendering più veloci, abilita il Lightning LoRA inLoraLoaderModelOnly(#101) per passare a un flusso di lavoro in pochi passaggi. Questa pila imposta le capacità del modello per realismo, layout e allineamento testo-immagine prima che inizi il campionamento.
- Il generatore base è Qwen Image 2512 caricato da
- Assistenti di campionamento con
ModelSamplingAuraFlow(#43) eCFGNorm(#55)- Questi due nodi preparano il modello per un campionamento stabile e bilanciato nel contrasto.
ModelSamplingAuraFlow(#43) regola il programma per mantenere i dettagli nitidi senza sovracottura delle texture.CFGNorm(#55) normalizza la guida per mantenere il colore e l'esposizione costanti seguendo il tuo prompt.
- Questi due nodi preparano il modello per un campionamento stabile e bilanciato nel contrasto.
- Denoising e affinamento con
KSampler(#54)- Questa è la fase di lavoro che migliora iterativamente il latente dal rumore a un'immagine coerente. Imposti il seme per la ripetibilità, selezioni il campionatore e il programmatore e scegli quanti passaggi eseguire. Con Lightning abilitato, puoi puntare a pochi passaggi; con solo il modello base, usa più passaggi per la massima fedeltà.
- Decodifica e salvataggio con
VAEDecode(#45) eSaveImage(#117)- Dopo il campionamento, il VAE ricostruisce pulitamente l'RGB dal latente e
SaveImagescrive il PNG finale. Se i colori o il contrasto sembrano sbagliati, rivisita la guida o la formulazione del prompt piuttosto che il post-processing; Qwen Image 2512 risponde bene a suggerimenti descrittivi di illuminazione e materiali.
- Dopo il campionamento, il VAE ricostruisce pulitamente l'RGB dal latente e
Nodi chiave nel flusso di lavoro Comfyui Qwen Image 2512#
UNETLoader(#100)- Carica il modello base Qwen‑Image‑2512 che determina la capacità complessiva e lo spazio stilistico. Usa la versione bf16 per la massima qualità se la tua GPU lo consente. Passa a una variante fp8 o compressa solo se hai bisogno di adattare la memoria o aumentare il throughput.
LoraLoaderModelOnly(#101)- Applica il LoRA Qwen‑Image‑2512‑Lightning‑4steps‑V1.0 sul modello base. Aumenta o riduci
strength_modelper fondere la sintonizzazione della velocità con la fedeltà di base, o impostalo su 0 per disabilitare. Quando questo LoRA è attivo, riducistepsinKSamplera poche iterazioni per realizzare l'accelerazione.
- Applica il LoRA Qwen‑Image‑2512‑Lightning‑4steps‑V1.0 sul modello base. Aumenta o riduci
ModelSamplingAuraFlow(#43)- Modifica il comportamento di campionamento del modello per un programma in stile flusso che spesso produce bordi più nitidi e meno sbavature. Se i risultati sembrano troppo nitidi o poco dettagliati, sposta leggermente il parametro
shifte ripeti il campionamento. Mantieni stabili le altre variabili mentre testi per isolare l'effetto.
- Modifica il comportamento di campionamento del modello per un programma in stile flusso che spesso produce bordi più nitidi e meno sbavature. Se i risultati sembrano troppo nitidi o poco dettagliati, sposta leggermente il parametro
CFGNorm(#55)- Normalizza la guida senza classificatore per prevenire risultati sbiaditi o eccessivamente saturi. Usa
strengthper decidere quanto assertivamente la normalizzazione dovrebbe agire. Se l'accuratezza del testo diminuisce quando aumenti il CFG, aumenta la forza della normalizzazione invece di alzare ulteriormente il CFG.
- Normalizza la guida senza classificatore per prevenire risultati sbiaditi o eccessivamente saturi. Usa
EmptySD3LatentImage(#57)- Imposta la dimensione della tela latente che definisce l'inquadratura e il rapporto d'aspetto. Per le persone, i rapporti ritratto riducono la distorsione e aiutano con le proporzioni del corpo; per i poster, i rapporti quadrati o paesaggistici enfatizzano il layout e i blocchi di testo. Aumenta la risoluzione solo dopo che sei soddisfatto della composizione.
CLIPTextEncode(#52) eCLIPTextEncode(#32)- L'encoder positivo (#52) trasforma la tua descrizione in condizionamento, inclusi stringhe di testo esplicite da rendere nella scena. L'encoder negativo (#32) sopprime tratti indesiderati come artefatti, dita extra o sfondi rumorosi. Mantieni i prompt concisi e fattuali per il miglior allineamento.
KSampler(#54)- Controlla seme, campionatore, programmatore, passaggi, CFG e forza di denoise. Con Qwen Image 2512, i valori CFG moderati tipicamente preservano il forte allineamento del testo del modello; se le lettere si deformano, abbassa il CFG prima di cambiare il campionatore. Per bozze veloci abilita Lightning e prova pochissimi passaggi, poi aumenta i passaggi per i rendering finali se necessario.
VAELoader(#34) eVAEDecode(#45)- Carica e applica il VAE di Qwen per ricostruire colori fedeli e dettagli fini. Mantieni il VAE abbinato al modello base per evitare cambi di colore. Se cambi i pesi di base, passa anche alla build VAE corrispondente.
Extra opzionali#
- Prompting per testo nell'immagine
- Metti le parole esatte tra virgolette dritte e aggiungi brevi suggerimenti tipografici come "tipografia moderna pulita" o "sans serif grassetto." Includi suggerimenti di posizionamento come "poster da parete" o "insegna di negozio" per ancorare dove il testo dovrebbe apparire.
- Iterazione più veloce con Lightning
- Abilita il Lightning LoRA e usa pochi passaggi per anteprime. Una volta che l'inquadratura e la formulazione sono corrette, disabilita o riduci la forza del LoRA e aumenta i passaggi per recuperare la massima fedeltà.
- Scelte di rapporto d'aspetto
- Attieniti a rapporti coerenti attraverso le variazioni. Usa il ritratto per le persone, il quadrato per studi di prodotto o logo, e il paesaggio per ambienti o diapositive. Se esegui un ingrandimento successivamente, mantieni lo stesso rapporto per preservare la composizione.
- Disciplina della guida
- Qwen Image 2512 di solito preferisce un CFG modesto. Se la fedeltà del testo scivola, abbassa il CFG o aumenta la forza di
CFGNormpiuttosto che accumulare più guida.
- Qwen Image 2512 di solito preferisce un CFG modesto. Se la fedeltà del testo scivola, abbassa il CFG o aumenta la forza di
- Riproducibilità
- Blocca un seme quando ti piace un risultato in modo da poter iterare in sicurezza. Modifica un controllo alla volta per capire il suo impatto prima di procedere.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo Comfy-Org per i Qwen Image 2512 Model Files per i loro contributi e la loro manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Comfy-Org/Qwen Image 2512 Model Files
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- Documenti / Note di rilascio: Qwen Image 2512 Model Files
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
