
Inferenza Qwen Image 2512 LoRA: generazioni AI Toolkit allineate alla pipeline e alla formazione in ComfyUI#
Questo flusso di lavoro RunComfy, pronto per la produzione, applica un LoRA addestrato con AI Toolkit a Qwen Image 2512 in ComfyUI con un focus sul comportamento allineato alla formazione. Si concentra su RC Qwen Image 2512 (RCQwenImage2512)—un nodo personalizzato open-source costruito da RunComfy (source) che esegue una pipeline di inferenza nativa Qwen (anziché un grafico di campionamento generico) e carica il tuo adattatore tramite lora_path e lora_scale.
Perché l'Inferenza Qwen Image 2512 LoRA spesso appare diversa in ComfyUI#
Le anteprime di AI Toolkit per Qwen Image 2512 sono prodotte da una pipeline specifica del modello, inclusi il comportamento di guida "true CFG" di Qwen e i valori predefiniti che la pipeline utilizza per il condizionamento e il campionamento. Se ricostruisci lo stesso lavoro come un grafico di campionamento standard di ComfyUI, la semantica della guida e il punto di patch LoRA possono cambiare—quindi "stesso prompt + stesso seed + stessi passaggi" può comunque portare a un risultato diverso. In pratica, molti rapporti "il mio LoRA non corrisponde alla formazione" sono disallineamenti di pipeline, non un parametro mancante.
RCQwenImage2512 mantiene l'inferenza allineata avvolgendo la pipeline di Qwen Image 2512 all'interno del nodo e applicando il LoRA in quella pipeline tramite lora_path e lora_scale. Fonte della pipeline: `src/pipelines/qwen_image.py`.
Come usare il flusso di lavoro di Inferenza Qwen Image 2512 LoRA#
Passo 1: Apri il flusso di lavoro#
Avvia il flusso di lavoro cloud in ComfyUI.
Passo 2: Importa il tuo LoRA (2 opzioni)#
- Opzione A (Risultato di formazione RunComfy): RunComfy → Trainer → LoRA Assets → trova il tuo LoRA → ⋮ → Copia Link LoRA

- Opzione B (LoRA AI Toolkit addestrato fuori RunComfy): Copia un link di download diretto
.safetensorsper il tuo LoRA e incolla quell'URL inlora_path(non è necessario scaricare inComfyUI/models/loras)
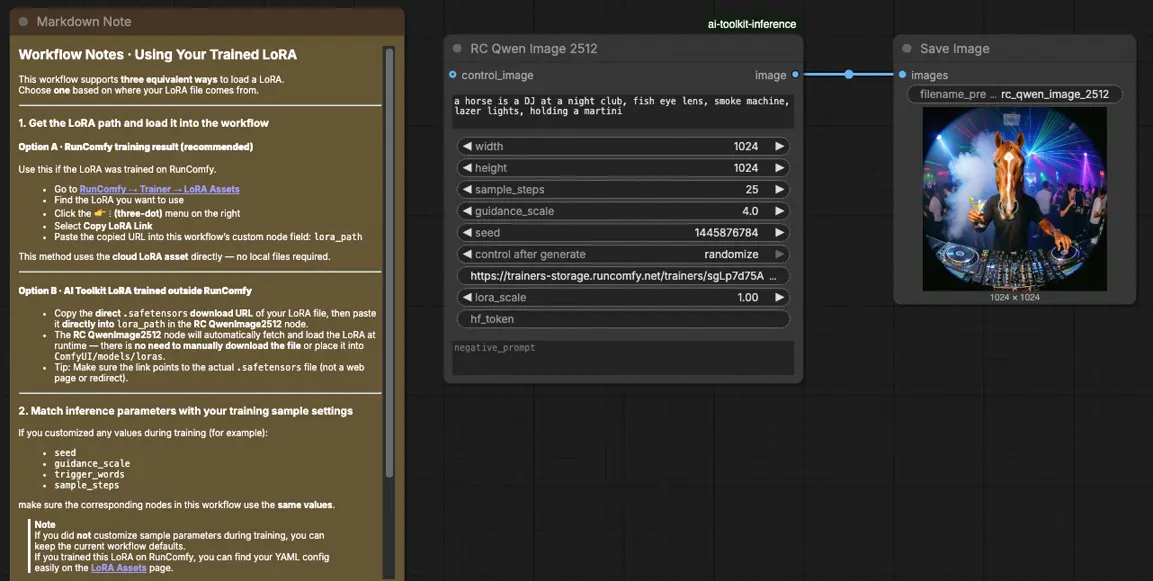
Passo 3: Configura il nodo personalizzato RCQwenImage2512 per l'Inferenza Qwen Image 2512 LoRA#
Incolla il tuo link LoRA in lora_path su RC Qwen Image 2512 (RCQwenImage2512).

Quindi imposta i restanti parametri del nodo (inizia abbinando i valori che hai usato per la generazione di anteprime/campioni durante la formazione):
prompt: il tuo prompt positivo (includi eventuali token di attivazione che il tuo LoRA si aspetta)negative_prompt: opzionale; lascialo vuoto se non hai usato negativi nelle tue anteprimewidth/height: risoluzione di output (si consigliano multipli di 32 per questa famiglia di pipeline)sample_steps: passaggi di inferenza; rispecchia il tuo conteggio di passaggi di anteprima prima di regolare (25 è una base comune)guidance_scale: forza di guida (Qwen utilizza una scala "true CFG", quindi riutilizza prima il tuo valore di anteprima)seed: blocca il seed mentre validi l'allineamento impostando il control_after_generate su 'fixed', quindi varia per nuovi campionilora_scale: forza del LoRA; inizia vicino al tuo valore di anteprima e regola in piccoli incrementi
Questo è un flusso di lavoro testo-immagine, quindi non è necessario fornire un'immagine di input.
Nota di allineamento della formazione: se hai personalizzato il campionamento durante la formazione, apri il tuo YAML di formazione AI Toolkit e rispecchia width, height, sample_steps, guidance_scale, seed, e lora_scale. Se hai addestrato su RunComfy, apri Trainer → LoRA Assets → Configura e copia i valori di anteprima/campione in RCQwenImage2512 prima di iterare.

Passo 4: Esegui Inferenza Qwen Image 2512 LoRA#
Clicca su Queue/Run. Il nodo SaveImage salva l'immagine generata nella tua cartella di output standard di ComfyUI.
Risoluzione dei problemi di Inferenza Qwen Image 2512 LoRA#
Il nodo personalizzato RC Qwen Image 2512 (RCQwenImage2512) di RunComfy è progettato per mantenere l'inferenza allineata alla pipeline con il campionamento in stile anteprima di Qwen Image 2512 eseguendo:
- una pipeline di inferenza nativa Qwen all'interno del nodo (non un grafico di campionamento generico), e
- iniettando il LoRA tramite
lora_path+lora_scaleall'interno di quella pipeline (punto di patch coerente).
(1)LoRA di Qwen-Image non funzionano in comfyui#
Perché succede
Gli utenti hanno segnalato che i LoRA di Qwen-Image addestrati con AI Toolkit possono non applicarsi in ComfyUI perché i prefissi delle chiavi dello stato-dict LoRA non corrispondono a ciò che il percorso di caricamento/inferenza di ComfyUI si aspetta (quindi l'adattatore si carica "silenziosamente" ma non effettivamente patcha i moduli del trasformatore Qwen).
Come risolvere (opzioni verificate dagli utenti)
- Usa RCQwenImage2512 per l'iniezione LoRA a livello di pipeline: carica l'adattatore solo tramite
lora_path+lora_scalesu RCQwenImage2512 (evita di impilare nodi di caricamento LoRA extra sopra mentre esegui il debugging). Questo mantiene il punto di patch LoRA allineato con la pipeline Qwen utilizzata dal campionamento in stile anteprima. - Se devi usare un provider di inferenza non RC / percorso di caricamento: una soluzione riportata dagli utenti è rinominare le chiavi LoRA sostituendo il primo segmento del prefisso della chiave LoRA da
diffusion_model→transformer, in modo che i pesi si mappino sui moduli trasformatore Qwen previsti (vedi il problema per il contesto esatto e perché è necessario).
(2)Patch per crash quando si utilizza inference_lora_path con qwen image (consente di generare campioni con turbo lora)#
Perché succede
Alcuni utenti hanno riscontrato un crash quando provano a caricare un'inferenza LoRA per Qwen (incluso Qwen-Image-2512) tramite il flusso inference_lora_path di AI Toolkit. Questo non è un problema di "prompt/CFG/seed"—è un problema di percorso di caricamento dell'inferenza.
Come risolvere (verificato dagli utenti)
- Applica la patch / aggiorna a una versione che include la patch descritta nel problema. L'autore del problema riporta che la patch risolve il crash quando si carica un'inferenza LoRA per Qwen (vedi il problema per il cambiamento esatto e il contesto della configurazione).
- Per l'inferenza ComfyUI specificamente: preferisci RCQwenImage2512 e carica l'adattatore tramite
lora_path/lora_scaleall'interno del nodo RC. Questo evita di fare affidamento su percorsi di caricamento LoRA di inferenza esterni e mantiene la pipeline coerente con il campionamento in stile anteprima.
(3)utilizzando sageattention 2 qwen-image in comfyui mostra immagini nere a causa di NaNs (cioè immagini nere)#
Perché succede
Gli utenti hanno segnalato che eseguendo Qwen Image in ComfyUI con SageAttention possono produrre NaNs che si trasformano in immagini nere. Questo può sembrare "il mio LoRA è rotto", ma in realtà è il backend di attenzione che produce valori non validi—l'esecuzione della pipeline fallisce prima che tu possa valutare significativamente il comportamento LoRA.
Come risolvere (verificato dagli utenti)
- Non usare
--use-sage-attentionper Qwen Image quando provoca NaNs/uscite nere. Valida prima una base pulita (uscite non nere), quindi valuta l'impatto del LoRA. - Se hai bisogno di accelerazioni SageAttention: risolvi l'output nero di Qwen forzando un percorso backend CUDA. In pratica, questo spesso significa utilizzare una patch a livello di flusso di lavoro (ad esempio, un nodo "Patch Sage Attention") e selezionare una variante backend CUDA che eviti il percorso Triton rotto per la GPU/architettura interessata.
- Dopo aver ottenuto output di base stabili (non neri), esegui l'inferenza Qwen Image 2512 tramite RCQwenImage2512 in modo che il punto di iniezione della pipeline + LoRA rimanga allineato all'anteprima mentre abbini
width/height/sample_steps/guidance_scale/seed/lora_scale.
Esegui ora l'Inferenza Qwen Image 2512 LoRA#
Apri il flusso di lavoro condiviso, incolla il tuo URL LoRA in lora_path, abbina i tuoi valori di campionamento di anteprima e esegui RCQwenImage2512 per generazioni Qwen Image 2512 allineate alla formazione in ComfyUI.
