
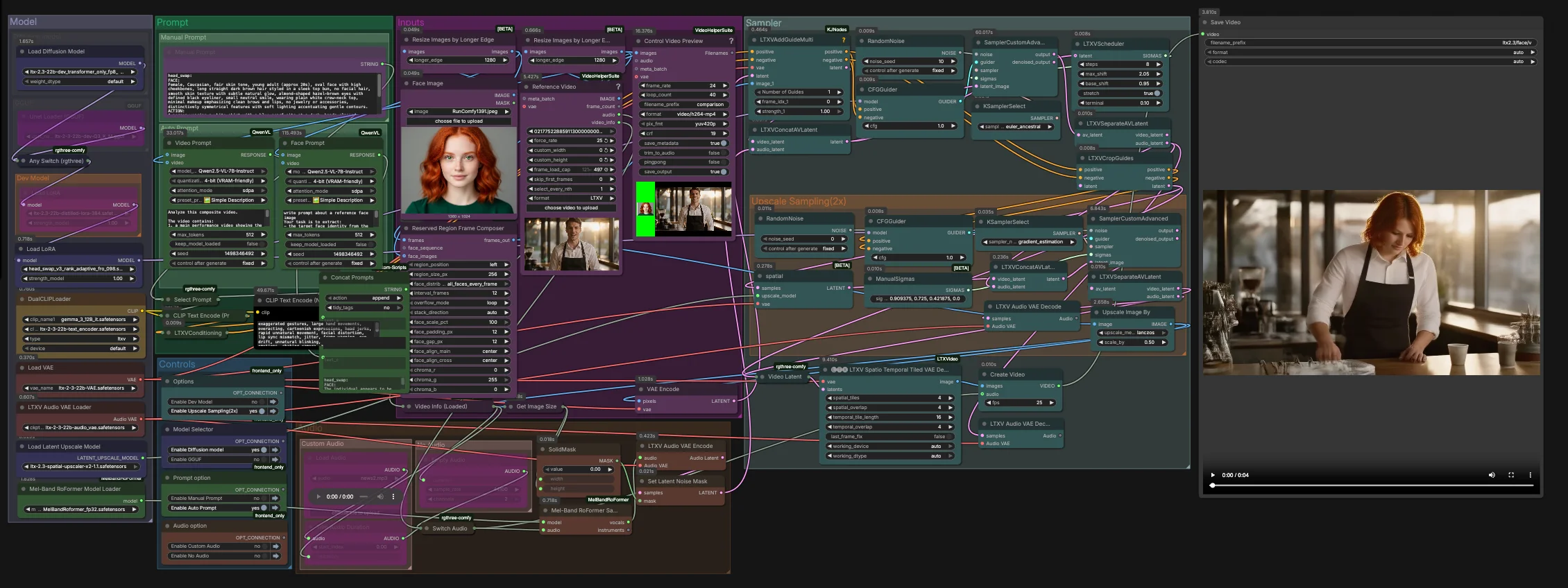
LTX-2.3-Video-Face-Swap per ComfyUI#
Questo workflow offre una sostituzione del volto video ad alta fedeltà e stabilità temporale utilizzando la famiglia LTX 2.3. Costruito per RunComfy e ComfyUI, fonde un'immagine guida di identità con un video target e una guida audio opzionale per preservare espressioni, illuminazione e movimento attraverso i fotogrammi. Il risultato è uno scambio realistico, resistente allo sfarfallio, che regge nei primi piani e nelle riprese medie.
Creatori, artisti VFX e cineasti AI possono usare LTX-2.3-Video-Face-Swap per mantenere il pieno controllo creativo: prompt manuali o generare prompt strutturati dagli input, scegliere tra le varianti dev, distilled, FP8 o GGUF, e finire con un decodifica spatio-temporale e un opzionale upscaling latente 2x per dettagli nitidi.
Modelli chiave nel workflow Comfyui LTX-2.3-Video-Face-Swap#
- LTX 2.3 22B Video Diffusion Transformer. Modello principale di generazione e modifica video che guida la conservazione dell'identità e la coerenza temporale. Vedi la famiglia di modelli ufficiale su Lightricks/LTX-2.3.
- LTX 2.3 Text Encoders. Il grafo accoppia l'encoder di testo LTX 2.3 con un encoder di istruzioni Gemma 3 12B per migliorare l'allineamento dei prompt per l'editing video. Esempi di artefatti: ltx-2-3-22b-text_encoder.safetensors e gemma_3_12B_it.safetensors.
- LTX 2.3 VAE e Audio VAE. Encoder/decoder utilizzati per comprimere e ricostruire fotogrammi visivi e tracce audio mantenendo i dettagli e la sincronizzazione. Vedi Lightricks/LTX-2.3 VAE files e varianti audio VAE nel repository split vantagewithai/LTX-2.3-Split.
- LTX 2.3 Spatial Upscaler x2. Upscaler latente 2x che aumenta la fedeltà spaziale prima della decodifica finale, ideale per i dettagli del volto. ltx-2.3-spatial-upscaler-x2-1.1.safetensors.
- Head‑swap LoRA. Un LoRA adattivo al rango specializzato per il trasferimento di identità che migliora la somiglianza e la stabilità durante l'editing. Esempio: head_swap_v3_rank_adaptive_fro_098.safetensors.
- MelBandRoFormer. Modello opzionale di separazione della sorgente musicale utilizzato qui per isolare i vocali per una guida più forte del movimento delle labbra. Kijai/MelBandRoFormer_comfy.
- Varianti di distribuzione opzionali. Pesi solo transformer FP8 per velocità su GPU supportate Kijai/LTX2.3_comfy e build UNet GGUF leggere per scenari CPU o low-VRAM vantagewithai/LTX-2.3-GGUF.
Come usare il workflow Comfyui LTX-2.3-Video-Face-Swap#
Questo grafo funziona in due fasi. La fase uno esegue lo scambio principale alla risoluzione latente nativa con guida audio-consapevole. La fase due esegue l'upsampling nello spazio latente e raffina la regione del volto prima di una decodifica spatio-temporale e del mux finale al video.
Inputs#
- Carica la tua immagine di identità in
Face Image(LoadImage(#255)). Usa uno scatto ben illuminato, frontale o a tre quarti per l'estrazione di identità più affidabile. - Carica il filmato di riferimento in
Reference Video(VHS_LoadVideo(#393)). I fotogrammi sono normalizzati e visualizzati in anteprima tramiteResizeImagesByLongerEdgeeControl Video Preview(VHS_VideoCombine(#396)) per controlli rapidi prima del campionamento. - Il
ReservedRegionFrameComposer(#395) prepara i fotogrammi guida che allineano l'immagine del volto al layout della scena, aiutando il modello a concentrarsi sull'area dello scambio durante il conditioning.
Prompt#
- Puoi descrivere l'aspetto e l'azione desiderati manualmente in
Manual Prompto lasciare che il grafo componga automaticamente un prompt strutturato.Video Prompt(AILab_QwenVL(#400)) estrae il movimento del corpo e la scena dal video mentreFace Prompt(AILab_QwenVL(#401)) estrae i dettagli dell'identità dall'immagine del volto. Concat Promptsunisce identità e azione in un'unica istruzione concisa, quindiSelect Promptinstrada il tuo testo manuale o il prompt automatico aCLIP Text Encode. Il testo del prompt negativo è codificato separatamente per sopprimere artefatti video comuni.
Model#
- Il gruppo
Modelcarica l'LTX 2.3 UNet o la sua variante GGUF, applica il LoRA distillato e il LoRA head-swap, e avvia gli LTX VAEs e i doppi encoder di testo. La configurazione a due encoder migliora l'allineamento per contenuti parlati e blocco della fotocamera senza sovracostringere l'identità. - Se stai ottimizzando per velocità o memoria, passa tra dev, distilled, FP8 solo transformer, o GGUF nel selettore di modelli fornito. Non è necessario un setup extra in RunComfy.
Sampler#
- La fase uno combina latenti video e audio in
LTXVConcatAVLatent(#321), quindi denoisa conCFGGuider(#326),LTXVScheduler(#324), eSamplerCustomAdvanced(#257). IlLTXVAddGuideMulti(#392) inietta la tua guida di identità in modo che il volto sia stabilito presto e rimanga stabile nel tempo. - Dopo un primo passaggio,
LTXVSeparateAVLatent(#323) separa i flussi cosìLTXVCropGuides(#282) può concentrare l'editing intorno al volto. Questo concentra il calcolo dove è importante e migliora la coerenza temporale.
Upscale Sampling (2x)#
LTXVLatentUpsampler(#279) applica l'upscaler spaziale x2 LTX 2.3 nello spazio latente. Il video latente upscalato viene poi riunito con il latente audio inLTXVConcatAVLatent(#287) e raffinato da un secondo passaggioSamplerCustomAdvanced(#288) guidato daCFGGuider(#284).- Questa strategia a due fasi produce pelle, occhi e capelli più nitidi mantenendo lo scambio bloccato sull'identità prevista.
Audio#
- Il gruppo
Audioti permette di instradare audio originale, silenzio, o un segmento ritagliato tramiteSwitch Audio. Per indizi più forti di movimento delle labbra, la traccia selezionata viene inviata attraversoMelBandRoFormerSampler(#355) per isolare i vocali, quindi codificata conLTXVAudioVAEEncode(#364). - Una solida maschera di rumore (
SetLatentNoiseMask(#365)) previene cambiamenti audio non intenzionali al di fuori della regione della bocca pur sfruttando la temporizzazione del discorso per guidare le espressioni.
Decode and export#
- I fotogrammi finali sono ricostruiti con
LTXVSpatioTemporalTiledVAEDecode(#377), che decodifica con tiling consapevole del tempo per evitare giunture e mantenere la continuità del movimento.CreateVideo(#292) muxa le immagini con l'audio scelto, eSaveVideoscrive il clip finito.
Nodi chiave nel workflow Comfyui LTX-2.3-Video-Face-Swap#
LTXVAddGuideMulti(#392). Alimenta la guida del volto allineato nel flusso di conditioning in modo che il modello si blocchi sull'identità target dai primi passi. Se la somiglianza si sposta in movimento rapido, aumenta il numero o la frequenza dei fotogrammi guida piuttosto che aumentare la guida globalmente.LTXVCropGuides(#282). Si concentra automaticamente il secondo passaggio sulla regione facciale derivata dai latenti e dai prompt della fase uno. Usalo per restringere l'area di modifica quando sfondi o mani competono per l'attenzione.SamplerCustomAdvanced(#257). Passaggio principale di denoise che stabilisce identità, illuminazione e movimento grossolano. Abbinalo alLTXVSchedulerper la modellazione dei passi e mantieni la scelta del sampler stabile tra gli esperimenti per rendere i confronti significativi.LTXVLatentUpsampler(#279). Esegue un'upscale latente 2x utilizzando l'upscaler spaziale LTX prima del raffinamento. Usalo quando hai bisogno di pori, ciglia e bordi del cappello più nitidi senza introdurre sfarfallio da upscaler pixel post-decodifica.SamplerCustomAdvanced(#288). Passaggio di raffinamento dopo l'upscaling. Regola moderatamente la guida qui per affilare le caratteristiche mantenendo l'identità impostata dal primo passaggio.LTXVSpatioTemporalTiledVAEDecode(#377). Decoder consapevole del tempo che riduce le giunture tra i fotogrammi. Se raggiungi i limiti di VRAM su clip lunghe, preferisci regolare il layout delle tessere piuttosto che abbassare la risoluzione.MelBandRoFormerSampler(#355). Separazione vocale utilizzata solo per la guida. Se l'audio sorgente è rumoroso, passa all'audio originale o silenzioso per evitare di propagare artefatti nel movimento della bocca.
Extra opzionali#
- La qualità dell'immagine del volto è importante. Usa una foto neutra, ben illuminata, frontale o leggermente a tre quarti di età e espressione simili alla performance.
- Mantieni il video di riferimento stabile. Le riprese statiche o su treppiede producono i risultati più stabili con LTX-2.3-Video-Face-Swap, specialmente nelle riprese medie e ravvicinate.
- I prompt dovrebbero essere concisi. Stabilisci la scena e l'azione in un solo paragrafo e riserva gli aggettivi di identità per il prompt del volto, non per il prompt dell'azione.
- La guida audio è opzionale. Un discorso chiaro migliora le forme delle labbra; le tracce solo musicali forniscono poco beneficio, quindi scegli il silenzio per concentrare il calcolo sui visivi.
- Per esecuzioni con VRAM bassa o solo CPU, preferisci la build UNet GGUF; per alta capacità su GPU moderne, i pesi solo transformer FP8 sono un buon default.
- Usa responsabilmente. Ottieni il consenso per qualsiasi somiglianza che scambi e rispetta le leggi applicabili e le politiche delle piattaforme.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine LTX-2.3 per il modello LTX-2.3, e EyeForAILabs per il tutorial su YouTube, per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository linkati di seguito.
Risorse#
- LTX-2.3/LTX-2.3 Model
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.