
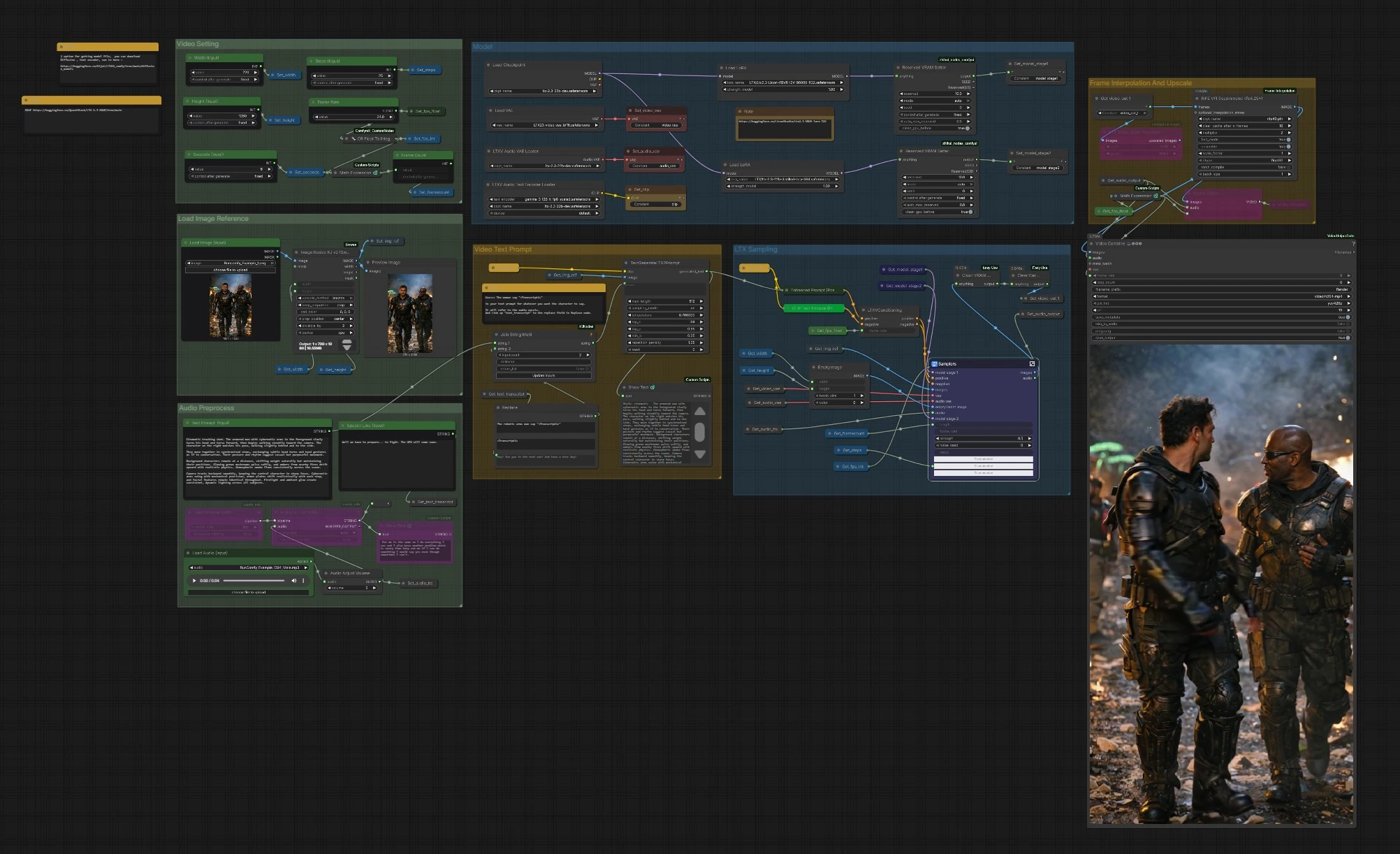
Flusso di Lavoro LTX 2.3 VBVR ComfyUI: immagine‑a‑video con dialogo consapevole del ragionamento#
Questo flusso di lavoro trasforma un'unica immagine di riferimento in una sequenza video coerente guidata da testo e discorso opzionale, alimentato da LTX‑2.3 e LTX 2.3 VBVR LoRA. VBVR sta per ragionamento visivo basato su video: aiuta il modello a mantenere coerenti identità, relazioni spaziali e causa‑ed‑effetto tra i fotogrammi, in modo che le scene risultino intenzionali piuttosto che casuali. Il grafico include suggerimenti consapevoli del discorso, campionamento LTX a due stadi, levigatura del movimento e ingrandimento/esportazione finale in MP4.
I creatori che necessitano di continuità narrativa, movimento credibile o tempistica del dialogo troveranno il flusso di lavoro LTX 2.3 VBVR particolarmente utile. Fornisci un forte fotogramma di riferimento, descrivi l'azione e le interazioni e inserisci facoltativamente una linea parlata che viene trascritta automaticamente e inserita nel prompt per un migliore allineamento delle labbra e della tempistica.
Modelli chiave nel flusso di lavoro Comfyui LTX 2.3 VBVR#
- Modello di generazione video LTX‑2.3 22B di Lightricks, la principale base di diffusione per la decodifica condizionata da immagine‑a‑video e audio. Hugging Face: Lightricks/LTX-2.3
- LTX‑2.3 Video VAE per la codifica/decodifica dei latenti video, abbinato al checkpoint base per una decodifica segmentata efficiente. Hugging Face: Lightricks/LTX-2.3
- Modello latente LTX‑2.3 Spatial Upscaler x2 per migliorare i dettagli spaziali dopo il primo passaggio. Hugging Face: Lightricks/LTX-2.3
- Codificatore di testo Gemma 3 12B confezionato per LTX‑2, usato qui per analizzare istruzioni complesse e token di dialogo. Hugging Face: Comfy-Org/ltx-2
- LTX 2.3 VBVR LoRA per la struttura della scena centrata sul ragionamento, interazione tra oggetti e continuità nel tempo. Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- Modello di interpolazione dei fotogrammi RIFE per levigare il movimento tra i fotogrammi generati. GitHub: hzwer/Practical-RIFE
- Modello di riconoscimento vocale Whisper per l'infusione opzionale di audio‑a‑testo nel prompt. GitHub: openai/whisper
Come usare il flusso di lavoro Comfyui LTX 2.3 VBVR#
Il grafico è organizzato in gruppi chiari. Configuri gli input, lo stack del modello e le impostazioni video, quindi i campionatori LTX generano fotogrammi che sono opzionalmente interpolati e ingranditi prima dell'esportazione.
Carica Immagine di Riferimento#
Usa Load Image (Input) (#5525) per scegliere un forte fotogramma di riferimento in stile. L'immagine viene ridimensionata da ImageResizeKJv2 (#5280) alla larghezza e altezza scelte preservando la composizione. Un nodo di anteprima conferma ciò che il modello vedrà effettivamente. Buone immagini di riferimento con soggetti e illuminazione chiari danno allo stack LTX 2.3 VBVR un ancoraggio affidabile per identità e stile.
Impostazione Video#
Imposta Width (Input) (#5284), Height (Input) (#5286), Seconds (Input) (#5573) e Frame Rate base (#5289). Il grafico calcola automaticamente il conteggio dei fotogrammi in modo che la tempistica rimanga coerente quando cambi durata o fps. Se prevedi di abilitare l'interpolazione più tardi, puoi scegliere un fps base modesto per risparmiare tempo e lasciare che RIFE aggiunga fluidità. Queste impostazioni informano anche il nodo di condizionamento in modo che il movimento e il ritmo rimangano coerenti.
Modello#
CheckpointLoaderSimple (#5493) carica LTX‑2.3. Il grafico collega il LTX 2.3 VBVR LoRA tramite LoraLoaderModelOnly (#5616) e può opzionalmente applicare un LoRA distillato e un LoRA detailer per maggiore fedeltà. LTXAVTextEncoderLoader (#5494) introduce il codificatore di testo basato su Gemma, mentre VAELoader (#5629) e LTXVAudioVAELoader (#5492) forniscono i VAE video e audio. Due nodi ReservedVRAMSetter bilanciano l'uso della memoria in modo che le esecuzioni lunghe rimangano stabili.
Prompt di Testo Video#
Scrivi la tua scena in Text Prompt (Input) (#5620). Per iniettare dialogo allineato con l'audio, includi un segnaposto come: The woman says "<Transcript1>". Inserisci la linea effettiva in Speech Line (Input) (#5524) o lascia che Whisper la produca dall'audio; StringReplace (#5226) e JoinStringMulti (#5602) sostituiscono <Transcript1> con la trascrizione. TextGenerateLTX2Prompt (#5488) poi compone un'istruzione raffinata, che Enhanced Prompt (Positive) (#5174) codifica prima che LTXVConditioning (#5173) prepari la guida finale. Verbi chiari, riferimenti a soggetti e segnali spaziali danno al LTX 2.3 VBVR LoRA il contesto di cui ha bisogno per ragionare nel tempo.
Preprocesso Audio#
Porta una traccia vocale con Load Audio (Input) (#5590) o collega TTS. AudioAdjustVolume (#5601) normalizza i livelli. Se vuoi dialogo consapevole del prompt, usa Whisper tramite Load Whisper (mtb) (#5606) e Audio To Text (mtb) (#5607) per generare la trascrizione usata nel prompt. Lo stesso audio viene anche codificato come latente e in seguito mixato nel video finale in modo che le labbra e i segnali temporali possano influenzare la generazione.
Campionamento LTX#
LTXVPreprocess (#5240) e LTXVImgToVideoInplace (#5245) convertono il tuo fotogramma di riferimento in una sequenza latente iniziale, preservando l'identità di base permettendo il movimento. Il sottografico Samplers (#5278) esegue un processo a due stadi con guidatori CFG e un pianificatore, producendo latenti spatio-temporali che rispettano sia il tuo prompt che il ragionamento del LTX 2.3 VBVR LoRA. I latenti audio sono concatenati con i latenti video in modo che la tempistica del discorso possa informare il movimento. LTXVSpatioTemporalTiledVAEDecode (#5237) decodifica i fotogrammi, e LTXVAudioVAEDecode (#5103) ripristina la traccia audio.
Interpolazione dei Fotogrammi e Ingrandimento#
RIFE VFI (#5554) interpola tra i fotogrammi per creare un movimento più fluido e raggiungere il tuo tasso di riproduzione target quando combinato con l'fps base. RTXVideoSuperResolution (#5631) migliora i dettagli e riduce gli artefatti di compressione, migliorando la leggibilità di volti, bordi e piccoli oggetti di scena. Usa questa fase per bilanciare velocità e qualità: interpola per la fluidità, poi ingrandisci per la nitidezza.
Esportazione#
Scegli tra CreateVideo (#5599) per un semplice mix o VHS_VideoCombine (#5618) per un maggiore controllo su formato, metadati e taglio. La pipeline scrive un H.264 MP4 tramite SaveVideo (#5597). Il tasso di fotogrammi è derivato dalle tue impostazioni e dalla fase di interpolazione in modo che la riproduzione corrisponda all'intento di movimento che hai creato all'inizio.
Nodi chiave nel flusso di lavoro Comfyui LTX 2.3 VBVR#
LoraLoaderModelOnly (#5616)#
Carica il LTX 2.3 VBVR LoRA che migliora la continuità logica, l'interazione tra oggetti e il movimento consapevole della telecamera. Regola il peso del LoRA per bilanciare l'influenza del ragionamento con lo stile del modello base e di altri LoRA. Questo nodo è centrale per l'aspetto distintivo e la coerenza che definiscono il flusso di lavoro LTX 2.3 VBVR. Per i nodi LTX e l'uso di LoRA, vedi Lightricks/ComfyUI-LTXVideo e la scheda VBVR LoRA sopra.
TextGenerateLTX2Prompt (#5488)#
Assembla il prompt positivo finale unendo la tua descrizione di base, l'immagine di riferimento e il token di dialogo sostituito da <Transcript1>. Mantieni le istruzioni concise, esplicite e coerenti su soggetti e azioni in modo che il modello possa ragionare nel tempo. Qui è dove codifichi l'intento che il LTX 2.3 VBVR LoRA rafforzerà durante il campionamento.
LTXVConditioning (#5173)#
Confeziona il condizionamento positivo e negativo e inoltra le informazioni temporali in modo che il movimento e il ritmo si allineino con la tua scelta di fps. Se cambi il tasso di fotogrammi nelle impostazioni, aggiornalo qui per mantenere costanti le dinamiche del movimento. Negativi forti aiutano a prevenire fotogrammi fissi, filigrane o sovrapposizioni indesiderate dal penetrare nella sequenza.
Samplers (#5278)#
Il blocco di campionamento a due stadi coordina rumore, guida e pianificazione per trasformare i latenti immagine e audio in un video coerente. Gli aggiustamenti più impattanti sono i passi totali, la forza immagine della fase iniziale I2V e il noise_seed per la riproducibilità. Regola questi con cura per bilanciare la fedeltà al fotogramma di riferimento contro la disponibilità a seguire nuovi movimenti e azioni.
RIFE VFI (#5554)#
Interpola i fotogrammi per un movimento più fluido o per raggiungere un fps effettivo più alto senza rigenerare la sequenza. Aumenta l'interpolazione quando il tuo fps base è basso o quando il movimento sembra scattoso; diminuiscila per preservare il ritmo generativo originale. Il modello è ampiamente usato per VFI di alta qualità; vedi il progetto RIFE su GitHub.
Extra opzionali#
- Trucco del dialogo con LTX 2.3 VBVR: scrivi una frase naturale con il segnaposto, ad esempio The woman says "<Transcript1>", quindi fornisci la linea in Speech Line o lascia che Whisper trascriva l'audio in modo che il prompt e le labbra si allineino.
- Prompting per il ragionamento: indica chi fa cosa, dove e perché. Usa nomi di soggetti coerenti e segnali temporali come poi, mentre e mentre la telecamera si muove per sfruttare i punti di forza di VBVR.
- Iterazioni più veloci: inizia con una durata più breve o un fps base inferiore, conferma i battiti del movimento, quindi aumenta l'interpolazione o i secondi per finire.
- Consigli di stabilità: se vedi un'alterazione dell'identità, abbassa leggermente la forza immagine‑a‑video o aumenta il peso del VBVR LoRA; se vedi un eccesso di vincoli, fai il contrario.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo sentitamente @Benji’s AI Playground per il 2.3 VBVR Workflow Source per i loro contributi e la loro manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- LTX/2.3 VBVR Workflow Source
- Documenti / Note di Rilascio: LTX 2.3 VBVR Workflow Source @Benji’s AI Playground
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.