
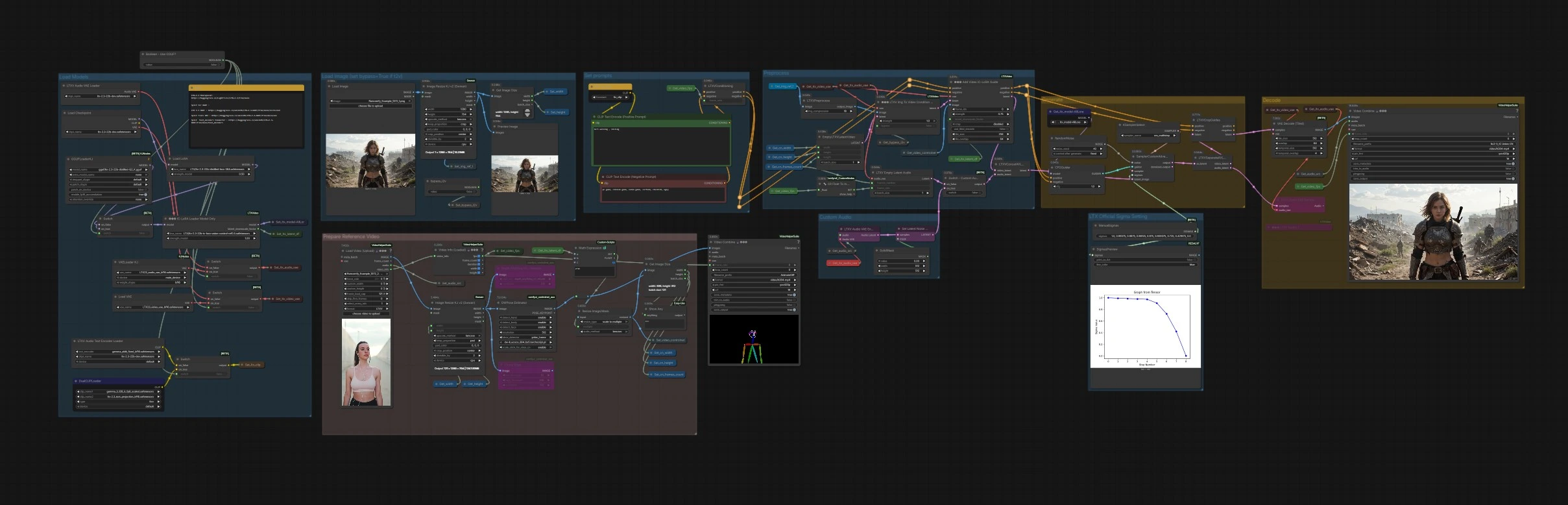
LTX 2.3 IC-LoRA: Generazione video con tracciamento del movimento in ComfyUI#
Questo workflow porta il sistema LTX 2.3 IC-LoRA su ComfyUI in modo da poter guidare il movimento e la struttura della scena mentre stili liberamente con prompt o LoRAs aggiuntivi. Condiziona il generatore video LTX-2.3 su segnali di riferimento come profondità, posa e bordi, abilitando il trasferimento del movimento, il bloccaggio della telecamera e la composizione prevedibile.
I creatori che lavorano su video-to-video, retargeting del movimento e animazione AI controllata troveranno che LTX 2.3 IC-LoRA separa il controllo del movimento dallo stile visivo. Guida l'aspetto con testo e LoRAs di stile, e guida il movimento con guide strutturate, tutto all'interno di un singolo grafico ComfyUI.
Modelli chiave nel workflow Comfyui LTX 2.3 IC-LoRA#
- LTX-2.3 di Lightricks. Un trasformatore di diffusione video latente ad alta fedeltà che genera sequenze temporalmente consistenti e supporta il conditioning per il controllo della struttura e del movimento. Hugging Face: Lightricks/LTX-2.3
- Pesi di controllo unione LTX 2.3 IC-LoRA. Pesi LoRA in-context progettati per iniettare segnali di guida strutturata in LTX-2.3 per un controllo preciso del movimento e della geometria. Forniti con la catena di modelli del workflow e caricati prima della generazione.
- LTX-2.3 VAEs per video e audio. Encoder/decoder latenti abbinati a LTX-2.3 per comprimere e ricostruire caratteristiche video e audio utilizzate durante il campionamento. Preconfigurati nel grafico e commutabili quando si usano build quantizzate. Esempi di pacchetti divisi sono disponibili qui: Hugging Face: unsloth/LTX-2.3-GGUF
- Depth Anything V2. Stima della profondità monoculare robusta utilizzata per bloccare il movimento della telecamera o preservare il layout della scena durante la generazione. Hugging Face: LiheYoung/Depth-Anything-V2
- DWPose. Stimatore di posa multi-persona leggero utilizzato per il retargeting o preservare il movimento del personaggio tramite punti chiave. Hugging Face: yzd-v/DWPose
Come usare il workflow Comfyui LTX 2.3 IC-LoRA#
Il grafico è organizzato in gruppi chiari. Prepara i prompt e un video di riferimento, scegli una o più guide strutturali, quindi genera ed esporta.
Imposta i prompt#
Usa CLIP Text Encode (Positive Prompt) (#2483) e CLIP Text Encode (Negative Prompt) (#2612) per descrivere lo stile visivo ed escludere tratti indesiderati. Gli encoder di testo sono caricati nel gruppo del modello e instradati in LTXVConditioning (#1241), che riceve anche il frame rate di lavoro in modo che il conditioning corrisponda al timing del tuo clip. Mantieni i prompt concentrati sull'aspetto poiché LTX 2.3 IC-LoRA gestirà movimento e struttura.
Preprocessa#
Carica o passa un clip di riferimento in VHS_LoadVideo (#5182). I frame sono ridimensionati in ImageResizeKJv2 (#5080) e alimentati negli estrattori di guida: DepthAnythingV2Preprocessor (#5064) per la profondità, DWPreprocessor (#4986) per la posa e CannyEdgePreprocessor (#4991) per i bordi. Un nodo di ridimensionamento a valle assicura che le mappe guida corrispondano ai multipli compatibili con il modello, e GetImageSize (#5029) registra larghezza, altezza e conteggio dei frame per il resto della pipeline. La sequenza di immagini guida risultante è memorizzata da Set_video_controlnet (#5100) per essere consumata da IC-LoRA.
Carica Modelli#
Il modello base e i LoRAs sono assemblati in questo gruppo. CheckpointLoaderSimple (#3940) carica LTX-2.3; LoraLoaderModelOnly (#4922) applica un LoRA LTX distillato per qualità e velocità; LTXICLoRALoaderModelOnly (#5011) aggiunge i pesi LTX 2.3 IC-LoRA e pubblica il fattore di ridimensionamento latente richiesto. I VAEs per video e audio sono caricati, e Boolean - Use GGUF? (#5158) può passare a una build quantizzata GGUF tramite GGUFLoaderKJ (#5150) con encoder di testo e VAEs compatibili quando il VRAM è limitato.
Carica Immagine (imposta bypass=True se t2v)#
Se vuoi ancorare la composizione con un riferimento fermo o un primo frame, usa LoadImage (#2004). Viene ridimensionato da ImageResizeKJv2 (#5076) e visualizzato per controlli rapidi. Il booleano bypass_i2v controlla se l'immagine viene usata del tutto; impostalo su True per puro testo-a-video con LTX 2.3 IC-LoRA.
Genera#
EmptyLTXVLatentVideo (#3059) crea la tela latente. Se l'ancoraggio dell'immagine è abilitato, LTXVImgToVideoConditionOnly (#3159) inietta solo informazioni strutturali dalla tua immagine senza incorporare lo stile. Il passaggio principale avviene in LTXAddVideoICLoRAGuide (#5012), che allega la tua sequenza guida scelta al modello usando il fattore di ridimensionamento latente dal caricatore IC-LoRA. Anche il conditioning audio fluisce nel latente tramite LTXVEmptyLatentAudio (#3980) o il percorso audio personalizzato. CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#5025), e SamplerCustomAdvanced (#4829) eseguono quindi il denoising per sintetizzare il video latente finale rispettando sia i prompt che i controlli LTX 2.3 IC-LoRA.
Decodifica#
LTXVSeparateAVLatent (#4845) divide i latenti audio e video generati per la decodifica. LTXVCropGuides (#5013) allinea e ritaglia se necessario, poi VAEDecodeTiled (#4851) ricostruisce i frame in modo efficiente. VHS_VideoCombine (#5070) muxa i frame in un MP4, utilizzando di default l'audio del clip di riferimento. Puoi anche decodificare il latente audio generato con LTXVAudioVAEDecode (#4848) se vuoi ascoltarlo separatamente.
Prepara Video di Riferimento#
Quest'area di supporto mostra la pipeline del frame di riferimento. VHS_VideoInfoLoaded (#5073) estrae fps e durata, che vengono propagati ai nodi di conditioning e agli esportatori in modo che il timing rimanga sincronizzato. Un piccolo nodo di combinazione fornisce un'anteprima visiva rapida della sequenza sorgente per controlli di sanità mentale.
Audio Personalizzato#
Se desideri una generazione consapevole dell'audio, l'audio di riferimento è codificato con LTXVAudioVAEEncode (#5146) e una semplice maschera è applicata in SetLatentNoiseMask (#5148). L'interruttore intitolato Switch - Custom Audio? (#5149) seleziona tra latenti audio vuoti o codificati prima della concatenazione in LTXVConcatAVLatent (#4528). L'esportazione finale utilizza ancora l'audio di riferimento per impostazione predefinita; se preferisci l'audio decodificato dal modello, instrada l'output di LTXVAudioVAEDecode all'ingresso audio dell'esportatore.
Impostazione Sigma Ufficiale LTX#
Il nodo di pianificazione ManualSigmas (#5025) definisce un profilo sigma conciso sintonizzato per LTX-2.3, e SigmasPreview (#5142) lo visualizza in modo da poter ragionare sulla distribuzione del rumore nel tempo. Questo ti permette di scambiare velocità per dettaglio mantenendo la caratteristica stabilità temporale di LTX 2.3 IC-LoRA.
Nodi chiave nel workflow Comfyui LTX 2.3 IC-LoRA#
LTXICLoRALoaderModelOnly(#5011). Carica i pesi LTX 2.3 IC-LoRA e fornisce il fattore di ridimensionamento latente richiesto dall'iniettore di guida. Se aggiungi ulteriori LoRAs di stile, posizionali prima di questo caricatore per mantenere dominante la guida del movimento.LTXAddVideoICLoRAGuide(#5012). Il punto in cui le sequenze di profondità, posa o bordo entrano nel modello come guida in-context. Modula la sua forza per bilanciare tra stretta aderenza strutturale e libertà stilistica dal tuo prompt e LoRAs di stile.LTXVImgToVideoConditionOnly(#3159). Fornisce un conditioning opzionale da immagine a video che trasferisce solo la composizione e la struttura grossolana da un'immagine fissa. Usa il suo togglebypassquando passi tra i2v e puro testo-a-video.CFGGuider(#4828). Controlla quanto fortemente il modello segue i tuoi prompt in relazione alla guida LTX 2.3 IC-LoRA. Aumenta la guida quando la fedeltà dello stile è più importante, diminuiscila per preservare movimento e geometria con minimo drift.SamplerCustomAdvanced(#4829) conManualSigmas(#5025). Un'accoppiata compatta di pianificazione e sampler multi-step che offre buona coerenza temporale per LTX-2.3. Se modifichi la pianificazione, mantienila in una diminuzione fluida e testa clip brevi prima di render più lunghi.
Extra opzionali#
- Scegli la guida giusta. Usa la profondità per bloccare la telecamera e il layout, la posa per il movimento del personaggio e i bordi per oggetti rigidi o silhouette pulite. È possibile mescolare due guide se descrivono aspetti diversi.
- Mantieni dimensioni amichevoli al campionatore. I preprocessori già arrotondano le dimensioni a multipli compatibili con il modello; mantieni la tua sorgente vicina al rapporto d'aspetto target per minimizzare il padding.
- Stile senza rompere il movimento. Aggiungi un LoRA di stile leggero prima del caricatore IC-LoRA e mantieni il suo peso moderato in modo che LTX 2.3 IC-LoRA possa mantenere geometria e timing.
- Modalità VRAM bassa. Attiva Use GGUF per eseguire il modello distillato quantizzato e gli encoder di testo/VAEs abbinati dal pacchetto GGUF se la tua GPU è limitata. Hugging Face: unsloth/LTX-2.3-GGUF
- Timing stabile. Il frame rate letto dal video di riferimento è iniettato nel conditioning e negli esportatori in modo che movimento e audio rimangano allineati. Se sovrascrivi fps, fallo in modo coerente tra conditioning ed esportazione.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Riconosciamo con gratitudine @Benji’s AI Playground di LTX 2.3 IC-LoRA Source per aver fornito materiali di origine e guida. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- LTX 2.3 IC-LoRA Source
- Documenti / Note di rilascio: YouTube @Benji’s AI Playground
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.