
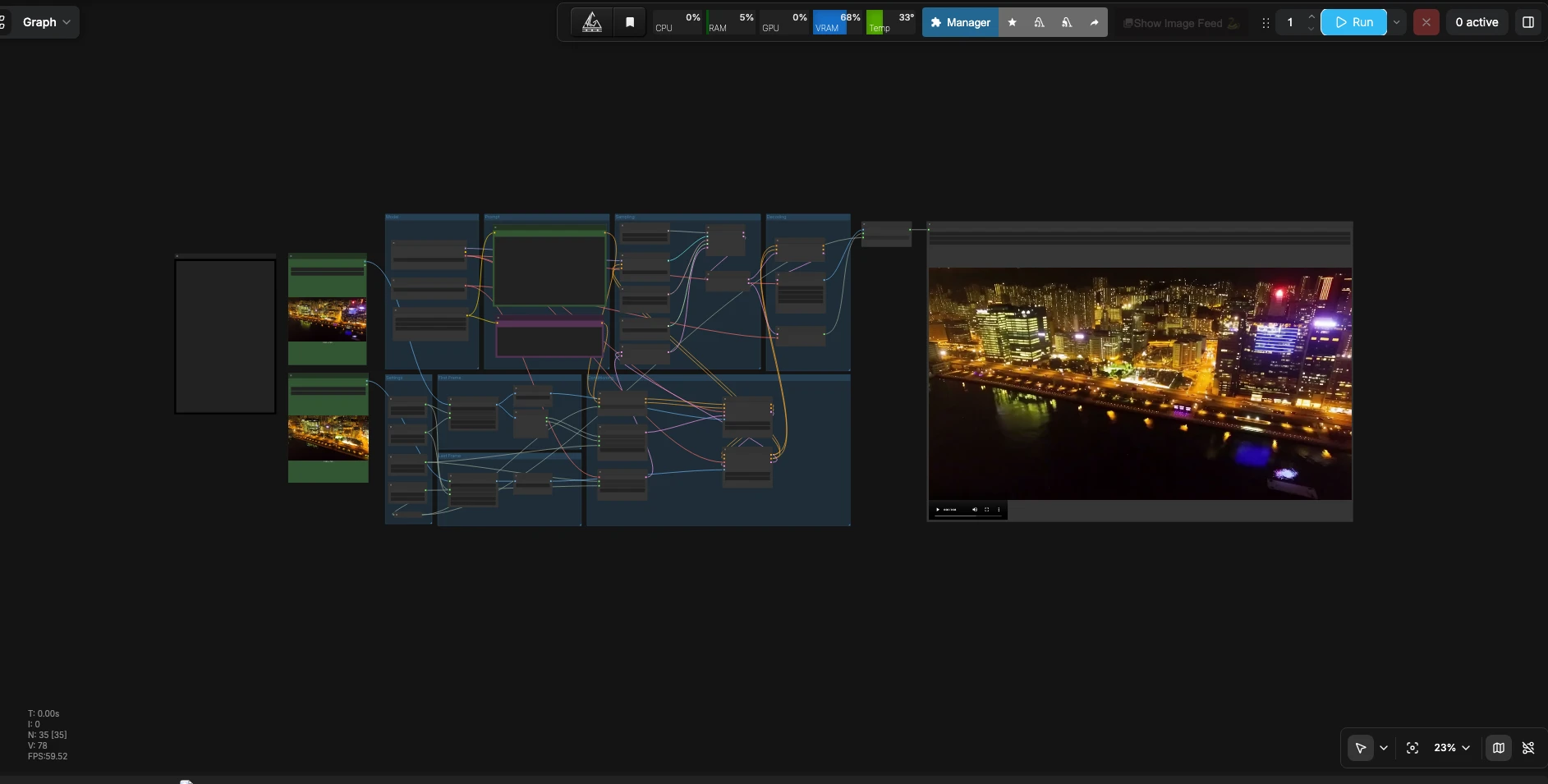
LTX 2.3 Primo Ultimo Frame per Video#
LTX 2.3 Primo Ultimo Frame per Video è un flusso di lavoro ComfyUI che trasforma due immagini statiche in un video fluido e continuo con audio sincronizzato. Fornisci un primo fotogramma, un ultimo fotogramma e un prompt in linguaggio naturale che descrive movimento, dettagli della scena e suono. Alimentata dal checkpoint LTX-2.3 22B distillato FP8, la pipeline interpola tra le immagini mantenendo un aspetto e una tempistica coerenti. È ideale per editor, designer di movimento e artisti di storyboard che necessitano di una transizione senza soluzione di continuità o di una breve clip in loop creata direttamente all'interno di ComfyUI.
Questo flusso di lavoro LTX 2.3 Primo Ultimo Frame enfatizza l'inferenza efficiente e l'alta fedeltà del prompt. I pesi FP8 mantengono l'uso di VRAM sotto controllo, mentre un encoder di testo Gemma 3 12B migliora la comprensione semantica sia delle istruzioni visive che audio. Il risultato è un passaggio visivo coerente dal primo all'ultimo fotogramma che onora il tuo prompt e rimane sincronizzato con l'audio generato.
Modelli chiave nel flusso di lavoro Comfyui LTX 2.3 Primo Ultimo Frame#
- LTX-2.3 22B Distilled FP8 checkpoint di Lightricks. Modello di generazione video principale distillato per inferenza efficiente, utilizzato qui per sintetizzare fotogrammi temporalmente coerenti mentre si condiziona sulle due guide di immagine e il prompt di testo. Model card
- Gemma 3 12B IT text encoder. Fornisce una robusta comprensione del linguaggio per gli aspetti visivi e audio del prompt, consentendo un accurato movimento, attributi della scena e indicazioni della colonna sonora. Model card
- LTX-2.3 latent VAEs per video e audio. Questi componenti mappano immagini e audio a forma d'onda in latenti compatti e viceversa durante la decodifica, preservando la qualità mentre si mantiene l'efficienza del campionamento. Spediti con il rilascio LTX-2.3 FP8. Model card
Come usare il flusso di lavoro Comfyui LTX 2.3 Primo Ultimo Frame#
Questo flusso di lavoro prende due immagini di riferimento e un prompt, costruisce la condizione con le guide del primo e dell'ultimo fotogramma, campiona un video latente con audio sincronizzato, e decodifica tutto in un file riproducibile.
Impostazioni
- Imposta la tua risoluzione di destinazione, il conteggio dei fotogrammi e il frame rate nel gruppo Impostazioni. Larghezza e altezza definiscono la tela di lavoro; i fotogrammi di input vengono ridimensionati per adattarsi in modo che il modello possa interpolare in modo pulito. Il conteggio dei fotogrammi controlla quanto dura la transizione e il frame rate imposta la velocità di riproduzione. Scegli un rapporto d'aspetto che corrisponda alle tue fonti per evitare ritagli indesiderati. I nodi
WIDTH(#113),HEIGHT(#98),Length(#102) eFrame Rate(int)(#114) ancorano queste scelte.
Primo Fotogramma
- Carica la tua immagine iniziale in
Load First Frame(#31). Viene ridimensionata daResizeImageMaskNode(#124) alle dimensioni target e normalizzata daLTXVPreprocess(#104). Questo prepara il primo fotogramma per agire come una forte guida strutturale e cromatica all'inizio del clip. Usa un'immagine nitida e ben illuminata per i migliori risultati.
Ultimo Fotogramma
- Carica la tua immagine finale in
Load Last Frame(#39). L'immagine viene adattata alla stessa dimensione conResizeImageMaskNode(#125) e normalizzata daLTXVPreprocess(#99). Questo assicura l'aspetto e il layout finali che desideri alla fine della transizione. Per i loop, rendi l'ultimo fotogramma visivamente compatibile con il primo.
Prompt
LTXAVTextEncoderLoader(#103) fornisce l'encoder di testo e due nodiCLIPTextEncodecatturano i tuoi prompt positivi e negativi. Nel prompt positivo (CLIPTextEncode(#128)), descrivi il movimento della telecamera, i soggetti, l'illuminazione e includi anche indicazioni audio come "Music: ambient pads with soft percussion" o "Dialogue: brief whisper." Il prompt negativo (CLIPTextEncode(#112)) può elencare artefatti o tratti che vuoi sopprimere.
Condizionamento
LTXVConditioning(#109) unisce il condizionamento di testo con le informazioni temporali in modo che il movimento e l'audio si allineino con il frame rate scelto.EmptyLTXVLatentVideo(#108) crea un video latente alla tua risoluzione e lunghezza. Due passaggi diLTXVAddGuideprima attaccano il primo fotogramma (LTXVAddGuide(#115)) e poi l'ultimo fotogramma (LTXVAddGuide(#111)) in modo che il modello sappia dove iniziare e dove finire.LTXVEmptyLatentAudio(#101) inizializza un audio latente di durata corrispondente eLTXVConcatAVLatent(#119) raggruppa latenti audio e video per il campionamento.
Modello
CheckpointLoaderSimple(#127) carica i pesi distillati FP8 LTX-2.3 22B e il video VAE, mentreLTXVAudioVAELoader(#126) fornisce l'audio VAE. Questi sono preconfigurati in modo che tu possa concentrarti sugli input creativi anziché sui dettagli di configurazione.
Campionamento
CFGGuider(#116) equilibra l'aderenza al tuo testo e alle guide dei fotogrammi contro la libertà creativa.RandomNoise(#100) imposta un seme per la riproducibilità. Il campionatore utilizzaSamplerEulerAncestral(#117) con un programma personalizzato daManualSigmas(#118), orchestrato daSamplerCustomAdvanced(#120), per raffinare progressivamente il latente in una sequenza coerente che segue le tue istruzioni di movimento e audio.
Decodifica
- Dopo il campionamento,
LTXVSeparateAVLatent(#121) scinde il latente combinato in video e audio.LTXVCropGuides(#106) raffina la guida spaziale per ridurre gli artefatti ai bordi prima della decodifica delle immagini.VAEDecodeTiled(#105) produce la sequenza di fotogrammi eLTXVAudioVAEDecode(#107) genera la forma d'onda audio.CreateVideo(#122) combina fotogrammi e suono al tuo fps selezionato eSaveVideo(#68) scrive il file finale nella tua uscita ComfyUI.
Nodi chiave nel flusso di lavoro Comfyui LTX 2.3 Primo Ultimo Frame#
EmptyLTXVLatentVideo (#108)
- Definisce la risoluzione e la durata del tuo clip. Regola larghezza, altezza e lunghezza qui per impostare la scala visiva e il tempo di transizione. Durate più lunghe necessitano di indicazioni di movimento più forti nel prompt per evitare stagnazione.
LTXVAddGuide (#115)
- Inietta il primo fotogramma come ancoraggio strutturale e cromatico all'inizio della sequenza. Se l'apertura si discosta dalla tua fonte, aumenta l'influenza di questa guida; se sembra troppo vincolata, riducila leggermente per consentire più movimento.
LTXVAddGuide (#111)
- Ancora l'aspetto target alla fine del clip utilizzando l'ultimo fotogramma. Se la transizione supera o non atterra mai sul tuo ultimo fotogramma, aumenta l'influenza della guida; se si aggancia troppo forte verso la fine, abbassa leggermente.
CFGGuider (#116)
- Controlla quanto fortemente il modello segue il condizionamento di testo e immagine. Una guida più alta enfatizza il tuo prompt e le guide, ma può ridurre la fluidità; valori più bassi si sentono più liberi ma possono deviare dall'aspetto previsto. Modifica in piccoli passi e riutilizza lo stesso seme quando confronti.
SamplerCustomAdvanced (#120) con SamplerEulerAncestral (#117) e ManualSigmas (#118)
- Guida il denoising con un programma coerente per un movimento stabile. Programmi più brevi rendono più velocemente ma possono essere grezzi; programmi più lunghi o più gentili migliorano la coerenza a un costo computazionale aggiuntivo. Mantieni il programma coerente quando esegui test A/B su altri parametri.
CreateVideo (#122)
- Combina fotogrammi decodificati e audio in un clip finale al frame rate scelto. Usa lo stesso fps con cui hai condizionato affinché forme delle labbra, passi o impulsi musicali rimangano allineati.
Extra opzionali#
- Scrivi prompt con verbi e tempi: "la telecamera si muove in avanti," "le luci si abbassano mentre ci avviciniamo," "Music: sparse piano with soft reverb." Verbi chiari aiutano la pipeline LTX 2.3 Primo Ultimo Frame a inferire movimento e ritmo.
- Abbina il rapporto d'aspetto e l'orientamento delle tue due immagini. Grandi discrepanze possono introdurre ritagli o stiramenti indesiderati.
- Per loop senza soluzione di continuità, rendi l'ultimo fotogramma una quasi corrispondenza al primo e mantieni il movimento della telecamera ciclico.
- Riutilizza un seme in
RandomNoiseper riprodurre un aspetto mentre iteri su prompt o punti di guida; cambia il seme per esplorare nuove variazioni. - Se hai bisogno di dettagli sull'implementazione o riferimenti a nodi personalizzati, consulta le integrazioni e le utilità di ComfyUI come ComfyUI-LTXTricks. Repository
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo Lightricks per LTX-2.3 22B Distilled FP8 Checkpoint, Google per Gemma 3 12B IT FP4 Text Encoder, logtd per ComfyUI-LTXTricks Custom Nodes, e Comfy.org per Comfy.org Official Workflow per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
Nota: L'uso dei modelli, dataset e codice referenziati è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
