
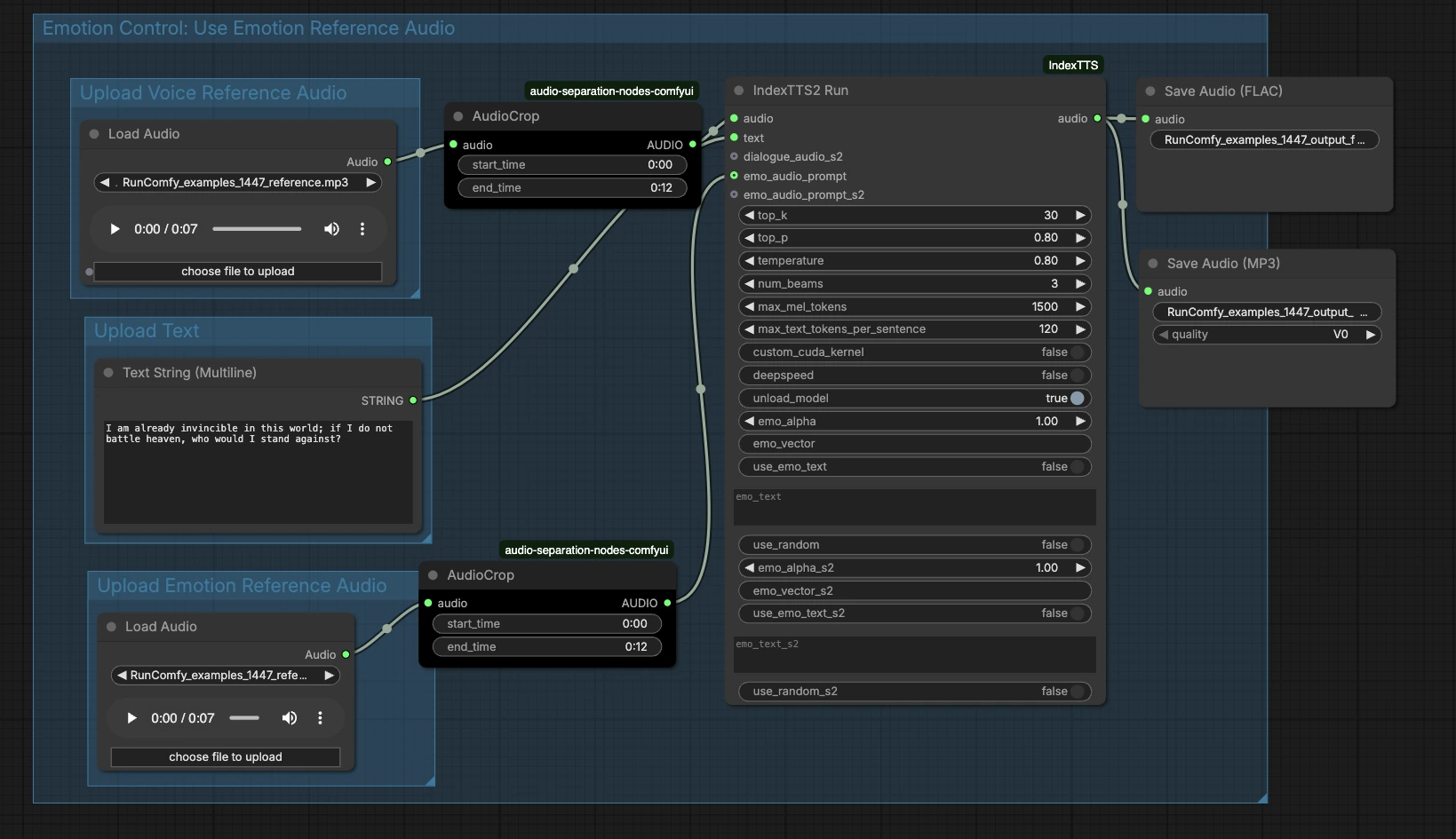
IndexTTS2 ComfyUI workflow: Clonazione di voce emotiva con audio di riferimento#
Questo workflow di IndexTTS2 ComfyUI trasforma una breve clip di riferimento in un discorso naturale ed espressivo che corrisponde al timbro e allo stile del parlante. Fornisci un audio di riferimento pulito, un suggerimento emotivo opzionale e il tuo script; il grafo genera cloni vocali di alta qualità e li esporta come FLAC per uso archivistico o MP3 per una condivisione rapida.
Basato sul modello IndexTTS‑2 e sui nodi ComfyUI IndexTTS, il workflow è ideale per creatori, designer di personaggi, educatori e utenti RunComfy che desiderano un TTS emotivo veloce e riproducibile. Tutto avviene all'interno di ComfyUI, quindi puoi ispezionare gli input, modificare le impostazioni e iterare rapidamente su esempi di narrazione, dialogo e voice-over.
Modelli chiave nel workflow Comfyui IndexTTS2 ComfyUI#
- IndexTTS‑2 di IndexTeam. Un moderno sistema text-to-speech che esegue clonazione vocale condizionata da riferimento e controllo di prosodia espressiva. Si condiziona su un breve esempio di parlante e opzionalmente su suggerimenti emotivi per rendere il discorso naturale dal testo. Vedi la scheda del modello su Hugging Face e il documento di accompagnamento per dettagli architettonici e di addestramento: IndexTTS‑2, progetto IndexTTS, documento IndexTTS‑2.
Come usare il workflow Comfyui IndexTTS2 ComfyUI#
A un livello alto, il grafo prende tre input — audio di timbro di riferimento, testo e audio emotivo opzionale — poi esegue la generazione ed esporta il risultato. I gruppi sotto mostrano dove aggiungere gli input e come si collegano al discorso finale.
Carica Audio di Riferimento Vocale#
Questo gruppo prepara l'identità del parlante. Carica un campione pulito della voce target in LoadAudio (#13), idealmente un singolo parlante che parla chiaramente senza musica o effetti. Usa AudioCrop (#37) per isolare un segmento stabile in modo che il sistema apprenda un timbro coerente. Segmenti brevi con tono stabile e consegna neutrale producono tipicamente la clonazione più affidabile. Il riferimento ritagliato viene inviato avanti per condizionare il generatore.
Carica Testo#
Inserisci il tuo script in PrimitiveStringMultiline (#14). Una punteggiatura chiara aiuta il modello a dedurre pause ed enfasi, quindi scrivi il testo nel modo in cui vuoi che venga pronunciato. Se pianifichi letture multi-frase, mantieni ogni frase ben formata ed evita emoji o simboli non comuni. Il testo fluisce direttamente nel nodo di sintesi per il rendering.
Carica Audio di Riferimento Emotivo#
Fornisci una clip opzionale che cattura l'emozione o la consegna che desideri — per esempio eccitato, calmo o cupo — tramite LoadAudio (#15). Tagliala con AudioCrop (#38) per mantenere solo la porzione espressiva che vuoi imitare. Questo è separato dal riferimento di timbro e si concentra su ritmo, energia e tono. Se salti questo passaggio, il workflow IndexTTS2 ComfyUI si baserà solo sul testo per la prosodia.
Controllo delle Emozioni: Usa Audio di Riferimento Emotivo#
Quest'area collega il tuo suggerimento emotivo al generatore. La clip emotiva ritagliata alimenta l'input emo_audio_prompt su IndexTTS2Run (#12), guidando la cadenza e l'intensità mentre preserva la voce target. Puoi anche usare i controlli del testo emotivo del nodo per indirizzare lo stile se non hai un esempio audio emotivo. In pratica, l'audio emotivo tende a dare un'espressività più forte e coerente, mentre il testo emotivo fornisce una guida più leggera. Combinali quando vuoi sia un esempio concreto che un suggerimento testuale.
Genera ed Esporta#
IndexTTS2Run (#12) sintetizza il discorso usando il tuo testo, riferimento di timbro e qualsiasi guida emotiva. L'output viene instradato a SaveAudio (#17) per un FLAC senza perdita e a SaveAudioMP3 (#39) per un'anteprima leggera e adatta al web. Usa i campi del nome del file sui nodi di salvataggio per mantenere le registrazioni organizzate attraverso le iterazioni. Questo design rende facile confrontare diversi testi o emozioni mantenendo la stessa identità del parlante.
Nodi chiave nel workflow Comfyui IndexTTS2 ComfyUI#
IndexTTS2Run (#12)#
Questo è il generatore principale che avvolge IndexTTS‑2 ed espone controlli per il campionamento, la ricerca a fascio e il condizionamento emotivo. Regola top_p, top_k e temperature per bilanciare stabilità e varietà — valori più bassi danno letture più coerenti, valori più alti aumentano la spontaneità. Usa num_beams quando vuoi che il nodo cerchi più letture candidate, scambiando velocità per qualità. Per script lunghi, max_mel_tokens e max_text_tokens_per_sentence aiutano a prevenire sovraccarichi limitando le dimensioni dei segmenti audio e testo. L'emozione può essere guidata con emo_audio_prompt, emo_alpha per la forza di miscelazione, o con use_emo_text e emo_text quando preferisci un suggerimento testuale. Aiuti alle prestazioni come deepspeed, custom_cuda_kernel e unload_model sono disponibili a seconda del tuo hardware. L'implementazione del nodo è fornita dai nodi personalizzati ComfyUI IndexTTS: ComfyUI_IndexTTS, e il modello sottostante è documentato qui: IndexTTS‑2, progetto IndexTTS.
AudioCrop (#37) — timbro di riferimento#
Usa questo nodo per isolare un estratto pulito e stabile dal tuo campione di parlante. Evita rumori di fondo, risate o emozioni estreme perché quei dettagli possono infiltrarsi nella voce clonata. Il ritaglio in un tono coerente migliora il blocco dell'identità e riduce gli artefatti indesiderati.
AudioCrop (#38) — suggerimento emotivo#
Questo ritaglio seleziona il suggerimento espressivo che controlla la consegna. Scegli una porzione con il ritmo o l'intensità esatta che desideri e mantienila concisa per evitare di diluire il segnale. Per la migliore coerenza, usa suggerimenti emotivi dallo stesso parlante del riferimento di timbro quando possibile.
Extra opzionali#
- Mantieni l'audio di riferimento asciutto e monofonico; rimuovi riverbero, musica di sottofondo e compressione pesante per una clonazione più pulita.
- Punteggia intenzionalmente. Virgole, punti e punti interrogativi aiutano il modello a posizionare pause e inflessioni che corrispondono alla tua intenzione.
- Per registrazioni riproducibili, disabilita la casualità nel nodo o tieni note su selezioni di testo e audio in modo da poter rigenerare lo stesso output in seguito.
- Se la VRAM è limitata, abilita lo scaricamento del modello tra le esecuzioni; può aggiungere un piccolo costo in tempo ma libera memoria per altri grafici.
- Rispetta i diritti vocali. Usa solo registrazioni di riferimento che sei autorizzato a clonare e dichiara il discorso sintetico dove richiesto.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine RunningHub per il riferimento del workflow, RunComfy per il workflow Cloud Save, Index Team per IndexTTS e IndexTTS-2, gli autori del documento IndexTTS2 e billwuhao per i nodi personalizzati ComfyUI IndexTTS per i loro contributi e manutenzione. Per dettagli autorevoli, consulta la documentazione originale e i repository collegati sotto.
Risorse#
- RunningHub/Workflow Reference
- Documenti / Note di rilascio: RunningHub post
- RunComfy/Cloud Save Workflow
- Documenti / Note di rilascio: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.