
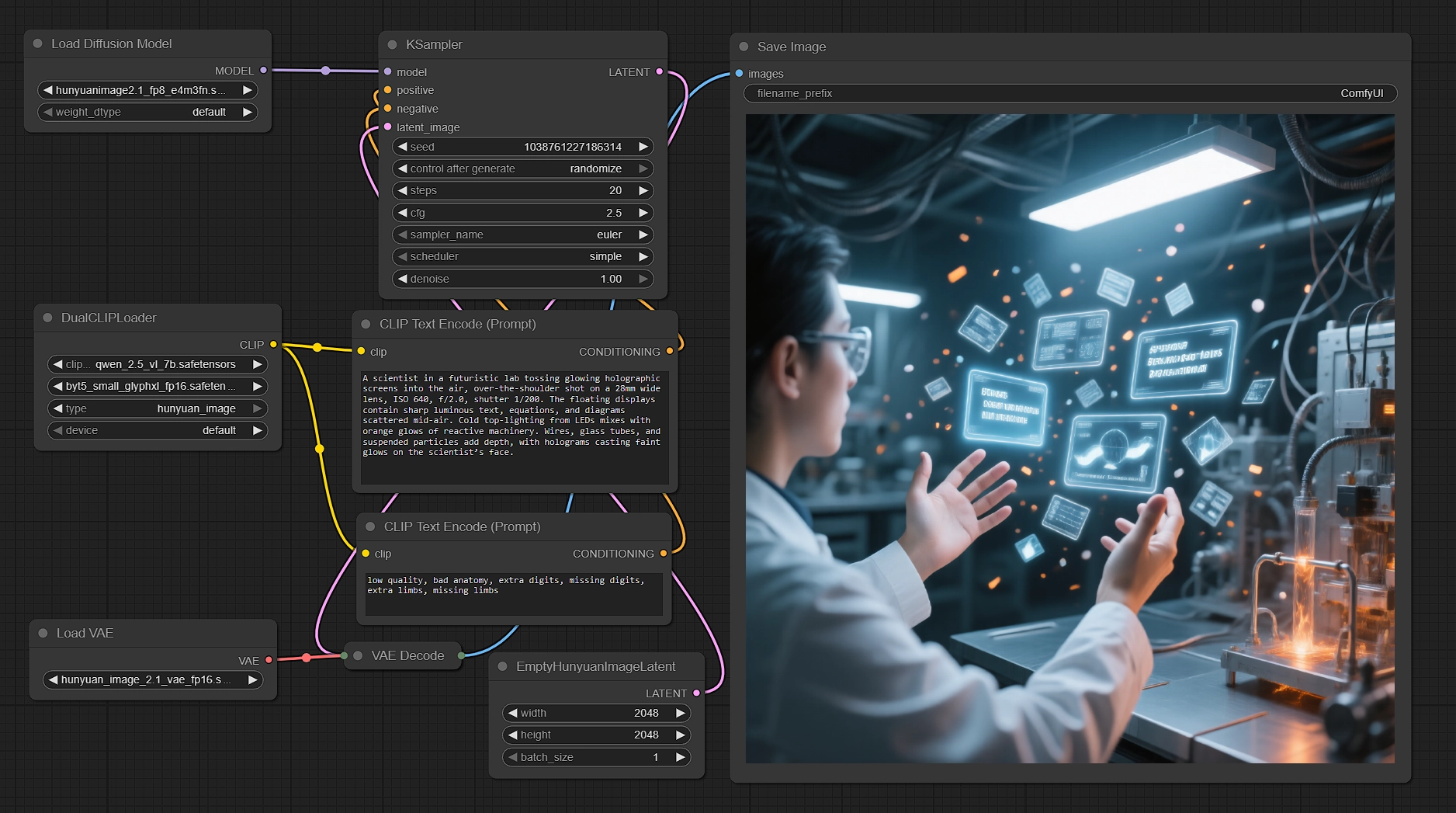










Genera immagini native 2K con Hunyuan Image 2.1 in ComfyUI#
Questo workflow trasforma i tuoi prompt in rendering nitidi e nativi 2048×2048 utilizzando Hunyuan Image 2.1. Abbina il trasformatore di diffusione di Tencent con doppi encoder di testo per migliorare l'allineamento semantico e la qualità del rendering del testo, quindi campiona in modo efficiente e decodifica attraverso il VAE ad alta compressione corrispondente. Se hai bisogno di scene pronte per la produzione, personaggi e testo chiaro nell'immagine a 2K mantenendo velocità e controllo, questo workflow ComfyUI Hunyuan Image 2.1 è fatto per te.
Creatori, direttori artistici e artisti tecnici possono inserire prompt multilingue, regolare alcuni parametri e ottenere costantemente risultati nitidi. Il grafico viene fornito con un prompt negativo sensato, una tela nativa 2K e un FP8 UNet per tenere sotto controllo la VRAM, mostrando cosa può offrire Hunyuan Image 2.1 appena fuori dalla scatola.
Modelli chiave nel workflow Comfyui Hunyuan Image 2.1#
- HunyuanImage‑2.1 di Tencent. Modello base da testo a immagine con un backbone di trasformatore di diffusione, doppi encoder di testo, un VAE 32×, post-allenamento RLHF e distillazione meanflow per un campionamento efficiente. Link: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Encoder multimodale visione-linguaggio utilizzato qui come encoder di testo semantico per migliorare la comprensione dei prompt in scene complesse e lingue. Link: Hugging Face
- ByT5 Small. Encoder byte-level senza tokenizzazione che potenzia la gestione di caratteri e glifi per il rendering del testo all'interno delle immagini. Link: Hugging Face · Paper
Come utilizzare il workflow Comfyui Hunyuan Image 2.1#
Il grafico segue un percorso chiaro dal prompt ai pixel: codifica il testo con due encoder, prepara una tela latente nativa 2K, campiona con Hunyuan Image 2.1, decodifica attraverso il VAE corrispondente e salva l'output.
Codifica del testo con doppi encoder#
- Il
DualCLIPLoader(#33) carica Qwen2.5‑VL‑7B e ByT5 Small configurati per Hunyuan Image 2.1. Questo setup doppio consente al modello di analizzare la semantica della scena restando robusto ai glifi e al testo multilingue. - Inserisci la tua descrizione principale in
CLIPTextEncode(#6). Puoi scrivere in inglese o cinese, mescolare suggerimenti per la fotocamera e l'illuminazione e includere istruzioni di testo nell'immagine. - Un prompt negativo pronto all'uso in
CLIPTextEncode(#7) sopprime gli artefatti comuni. Puoi adattarlo al tuo stile o lasciarlo così com'è per risultati bilanciati.
Tela latente a 2K nativa#
EmptyHunyuanImageLatent(#29) inizializza la tela a 2048×2048 con un singolo batch. Hunyuan Image 2.1 è progettato per la generazione 2K, quindi le dimensioni native 2K sono raccomandate per la migliore qualità.- Regola larghezza e altezza se necessario, mantenendo i rapporti d'aspetto supportati da Hunyuan. Per rapporti alternativi, attieniti a dimensioni amiche del modello per evitare artefatti.
Campionamento efficiente con Hunyuan Image 2.1#
UNETLoader(#37) carica il checkpoint FP8 per ridurre la VRAM mantenendo la fedeltà, poi alimentaKSampler(#3) per la denoising.- Usa i condizionamenti positivi e negativi dagli encoder per guidare la composizione e la chiarezza. Modifica il seed per la varietà, i passaggi per la qualità rispetto alla velocità e la guida per l'aderenza al prompt.
- Il workflow si concentra sul percorso del modello base. Hunyuan Image 2.1 supporta anche una fase di raffinamento; puoi aggiungerne una in seguito se desideri ulteriore lucidatura.
Decodifica e salvataggio#
VAELoader(#34) porta nel VAE di Hunyuan Image 2.1, eVAEDecode(#8) ricostruisce l'immagine finale dal latente campionato con lo schema di compressione 32× del modello.SaveImage(#9) scrive l'output nella directory scelta. Imposta un prefisso chiaro per il nome del file se prevedi di iterare tra seed o prompt.
Nodi chiave nel workflow Comfyui Hunyuan Image 2.1#
DualCLIPLoader (#33)#
Questo nodo carica la coppia di encoder di testo che Hunyuan Image 2.1 si aspetta. Mantieni il tipo di modello impostato per Hunyuan e seleziona Qwen2.5‑VL‑7B e ByT5 Small per combinare una forte comprensione della scena con una gestione del testo consapevole dei glifi. Se iteri sullo stile, regola il prompt positivo in tandem con la guida piuttosto che cambiare gli encoder.
CLIPTextEncode (#6 e #7)#
Questi nodi trasformano i tuoi prompt positivi e negativi in condizionamenti. Mantieni il prompt positivo conciso in cima, quindi aggiungi indizi su lenti, illuminazione e stile. Usa il prompt negativo per sopprimere artefatti come arti extra o testo rumoroso; riducilo se lo trovi eccessivamente restrittivo per il tuo concetto.
EmptyHunyuanImageLatent (#29)#
Definisce la risoluzione di lavoro e il batch. Il default 2048×2048 si allinea con la capacità nativa 2K di Hunyuan Image 2.1. Per altri rapporti d'aspetto, scegli coppie di larghezza e altezza amiche del modello e considera di aumentare leggermente i passaggi se ti allontani troppo dal quadrato.
KSampler (#3)#
Guida il processo di denoising con Hunyuan Image 2.1. Aumenta i passaggi quando hai bisogno di micro-dettagli più fini, diminuisci per bozze rapide. Aumenta la guida per una maggiore aderenza al prompt ma fai attenzione alla sovrasaturazione o rigidità; abbassala per una variazione più naturale. Cambia i seed per esplorare composizioni senza cambiare il tuo prompt.
UNETLoader (#37)#
Carica l'UNet di Hunyuan Image 2.1. Il checkpoint FP8 incluso mantiene l'uso della memoria modesto per output 2K. Se hai abbondante VRAM e vuoi il massimo margine per impostazioni aggressive, considera una variante ad alta precisione dello stesso modello dalle versioni ufficiali.
VAELoader (#34) e VAEDecode (#8)#
Questi nodi devono corrispondere alla versione di Hunyuan Image 2.1 per decodificare correttamente. Il VAE ad alta compressione del modello è fondamentale per la generazione rapida 2K; abbinare il VAE corretto evita cambiamenti di colore e texture a blocchi. Se cambi il modello base, aggiorna sempre di conseguenza il VAE.
Extra opzionali#
- Prompting
- Hunyuan Image 2.1 risponde bene a prompt strutturati: soggetto, azione, ambiente, fotocamera, illuminazione, stile. Per testo nell'immagine, cita esattamente le parole che vuoi e mantienile brevi.
- Velocità e memoria
- L'UNet FP8 è già efficiente. Se hai bisogno di comprimere ulteriormente, disabilita grandi batch e preferisci meno passaggi. I nodi loader GGUF opzionali sono presenti nel grafico ma disabilitati per default; gli utenti avanzati possono sostituirli quando sperimentano con checkpoint quantizzati.
- Rapporti d'aspetto
- Attieniti a dimensioni amiche del 2K nativo per i migliori risultati. Se ti avventuri in formati larghi o alti, verifica un rendering pulito e considera un piccolo aumento dei passaggi.
- Raffinamento
- Hunyuan Image 2.1 supporta una fase di raffinamento. Per provarla, aggiungi un secondo campionatore dopo il passaggio base con un checkpoint di raffinamento e una leggera denoise per preservare la struttura mentre aumenti i micro-dettagli.
- Riferimenti
- Dettagli del modello Hunyuan Image 2.1 e download: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small e paper: Hugging Face · Paper
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo sentitamente @Ai Verse e Hunyuan per il demo di Hunyuan Image 2.1 per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Hunyuan/Hunyuan Image 2.1 Demo
- Documenti / Note di rilascio: Hunyuan Image 2.1 Demo tutorial da @Ai Verse
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.


