
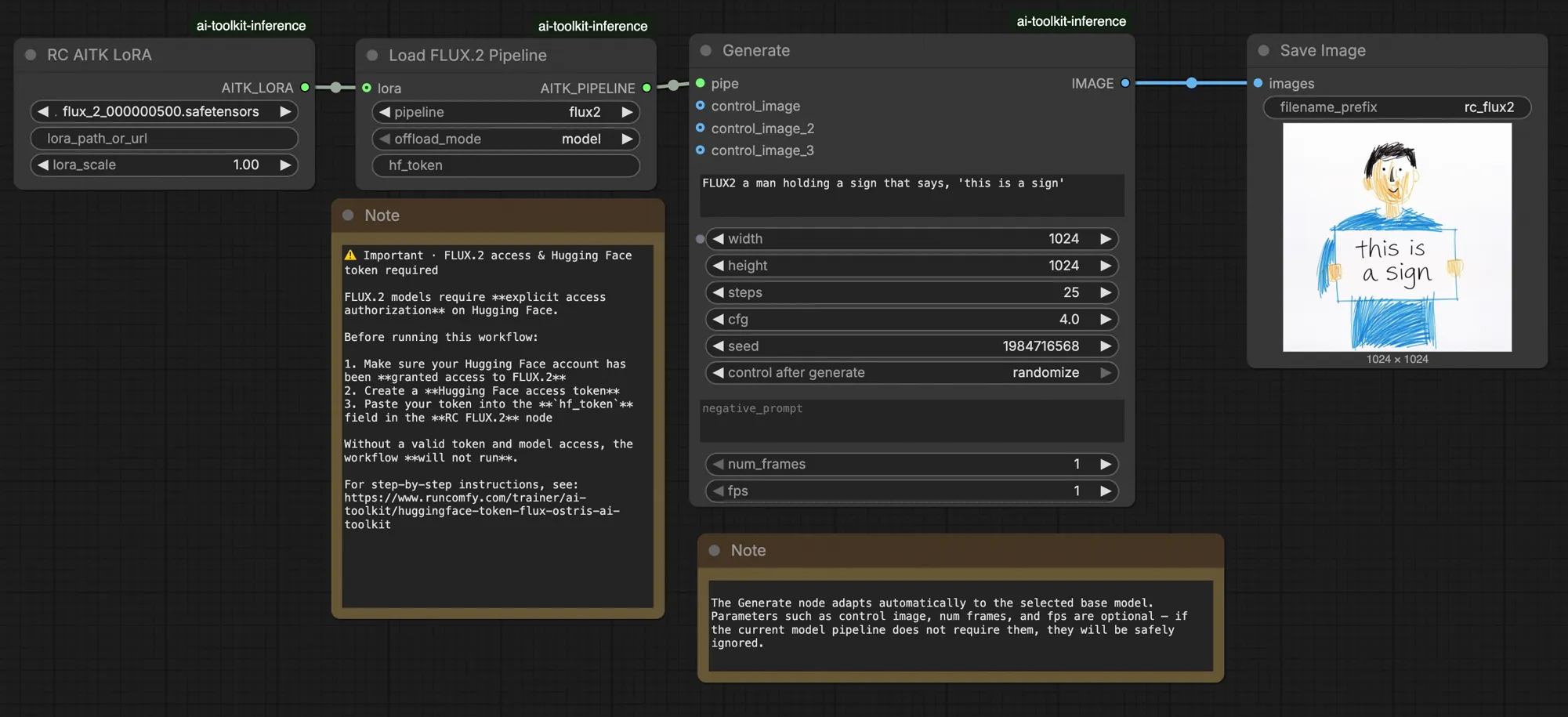
FLUX.2 LoRA ComfyUI Inferenza: output LoRA di AI Toolkit corrispondente all'addestramento con la pipeline FLUX.2 Dev#
Questo workflow RunComfy pronto alla produzione esegue l'inferenza FLUX.2 Dev LoRA in ComfyUI attraverso RC FLUX.2 Dev (Flux2Pipeline) (allineamento a livello di pipeline, non un grafo di campionamento generico). RunComfy ha costruito e reso open source questo nodo personalizzato—vedi i repository runcomfy-com—e controlli l'applicazione dell'adattatore con lora_path e lora_scale.
Nota: Questo workflow richiede una macchina 3XL per funzionare.
Perché FLUX.2 LoRA ComfyUI Inferenza spesso appare diversa in ComfyUI#
Le anteprime di addestramento di AI Toolkit sono renderizzate attraverso una pipeline FLUX.2 specifica del modello, dove codifica del testo, pianificazione e iniezione di LoRA sono progettati per funzionare insieme. In ComfyUI, ricostruire FLUX.2 con un grafo diverso (o un diverso percorso di caricamento di LoRA) può cambiare queste interazioni, quindi copiare lo stesso prompt, passaggi, CFG e seme produce comunque una deriva visibile. I nodi della pipeline RC RunComfy colmano quel divario eseguendo FLUX.2 dall'inizio alla fine in Flux2Pipeline e applicando il tuo LoRA all'interno di quella pipeline, mantenendo l'inferenza allineata con il comportamento di anteprima. Fonte: repository open-source RunComfy.
Come utilizzare il workflow FLUX.2 LoRA ComfyUI Inferenza#
Passo 1: Ottieni il percorso LoRA e caricalo nel workflow (2 opzioni)#
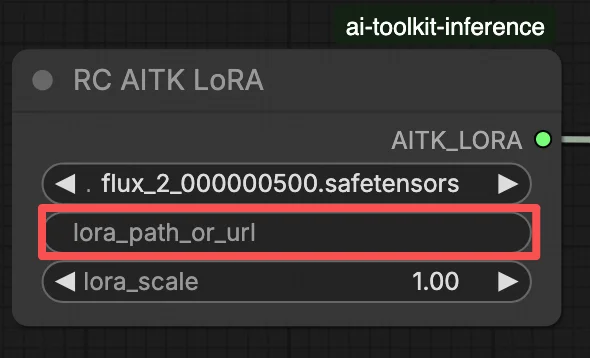
⚠️ Importante · Accesso FLUX.2 e token Hugging Face richiesti#
I modelli FLUX.2 Dev richiedono autorizzazione esplicita all'accesso su Hugging Face.
Prima di eseguire questo workflow:
- Assicurati che il tuo account Hugging Face abbia ottenuto l'accesso a FLUX.2 (Dev)
- Crea un token di accesso Hugging Face
- Incolla il tuo token nel campo
hf_tokensul nodo Load Pipeline
Senza un token valido e un accesso corretto al modello, il workflow non funzionerà. Per istruzioni passo-passo, vedi Hugging Face token per FLUX.2.
Opzione A — Risultato di addestramento RunComfy → scarica su ComfyUI locale:
- Vai a Trainer → LoRA Assets
- Trova il LoRA che vuoi utilizzare
- Clicca sul menu ⋮ (tre puntini) a destra → seleziona Copia Link LoRA
- Nella pagina del workflow ComfyUI, incolla il link copiato nel campo di input Download nell'angolo in alto a destra dell'interfaccia utente
- Prima di cliccare Download, assicurati che la cartella di destinazione sia impostata su ComfyUI > models > loras (questa cartella deve essere selezionata come destinazione del download)
- Clicca Download — questo assicura che il file LoRA sia salvato nella directory corretta
models/loras - Dopo che il download è terminato, aggiorna la pagina
- Il LoRA ora appare nel menu a tendina di selezione LoRA nel workflow — selezionalo

Opzione B — URL diretto LoRA (sovrascrive Opzione A):
- Incolla l'URL diretto di download
.safetensorsnel campo di inputpath / urldel nodo LoRA - Quando un URL è fornito qui, sovrascrive l'Opzione A — il workflow carica il LoRA direttamente dall'URL al momento dell'esecuzione
- Non è richiesto alcun download locale o posizionamento file
Suggerimento: conferma che l'URL risolva il file .safetensors effettivo (non una pagina di destinazione o reindirizzamento).
Passo 2: Abbina i parametri di inferenza con le impostazioni del tuo campione di addestramento#
Nel nodo LoRA, seleziona il tuo adattatore in lora_path (Opzione A), o incolla un link diretto .safetensors in path / url (Opzione B sovrascrive il menu a tendina). Quindi imposta lora_scale alla stessa intensità che hai usato durante le anteprime di addestramento e regola da lì.
I parametri rimanenti sono sul nodo Generate (e, a seconda del grafo, sul nodo Load Pipeline):
prompt: il tuo prompt di testo (includi le parole di attivazione se le hai usate durante l'addestramento)width/height: risoluzione di output; abbina la dimensione della tua anteprima di addestramento per il confronto più pulito (multipli di 16 sono raccomandati per FLUX.2)sample_steps: numero di passaggi di inferenza (25 è un valore predefinito comune)guidance_scale: valore di CFG/guidance (4.0 è un valore predefinito comune)seed: seme fisso per riprodurre; cambialo per esplorare variazioniseed_mode(solo se presente): sceglifixedorandomizenegative_prompt(solo se presente): FLUX.2 è guidance-distilled in questo workflow, quindi i prompt negativi sono ignoratihf_token: token di accesso Hugging Face; richiesto per il download del modello FLUX.2 Dev (incollalo sul nodo Load Pipeline)
Suggerimento per l'allineamento dell'addestramento: se hai personalizzato i valori di campionamento durante l'addestramento (seed, guidance_scale, sample_steps, parole di attivazione, risoluzione), rispecchia quegli stessi valori qui. Se hai addestrato su RunComfy, apri Trainer → LoRA Assets > Config per visualizzare lo YAML risolto e copiare le impostazioni di anteprima/campione nei nodi del workflow.

Passo 3: Esegui FLUX.2 LoRA ComfyUI Inferenza#
Clicca Queue/Run — il nodo SaveImage scrive i risultati nella tua cartella di output ComfyUI.
Lista di controllo rapida:
- ✓ LoRA è: scaricato in
ComfyUI/models/loras(Opzione A), o caricato tramite un URL diretto.safetensors(Opzione B) - ✓ Pagina aggiornata dopo il download locale (solo Opzione A)
- ✓ I parametri di inferenza corrispondono alla configurazione del
sampledi addestramento (se personalizzati)
Se tutto quanto sopra è corretto, i risultati dell'inferenza qui dovrebbero corrispondere da vicino alle tue anteprime di addestramento.
Risoluzione dei problemi FLUX.2 LoRA ComfyUI Inferenza#
La maggior parte delle differenze tra “anteprima di addestramento FLUX.2 vs inferenza ComfyUI” derivano da differenze a livello di pipeline (come viene caricato il modello, pianificato e come viene fuso il LoRA), non da un singolo parametro errato. Questo workflow RunComfy ripristina la base più vicina “corrispondente all'addestramento” eseguendo l'inferenza attraverso RC FLUX.2 Dev (Flux2Pipeline) dall'inizio alla fine e applicando il tuo LoRA all'interno di quella pipeline tramite lora_path / lora_scale (invece di impilare nodi di caricamento/campionamento generici).
(1) Errore Flux.2 con Lora: "mul_cuda" non implementato per 'Float8_e4m3fn'#
Perché accade Questo accade tipicamente quando FLUX.2 viene caricato con pesi Float8/FP8 (o quantizzazione a precisione mista) e il LoRA viene applicato tramite un percorso LoRA generico di ComfyUI. La fusione di LoRA può forzare operazioni Float8 non supportate (o promozioni miste Float8 + BF16), che attivano l'errore di runtime Float8 mul_cuda.
Come risolvere (consigliato)
- Esegui l'inferenza attraverso RC FLUX.2 Dev (Flux2Pipeline) e carica l'adattatore solo tramite
lora_path/lora_scalein modo che la fusione LoRA avvenga nella pipeline allineata con AI Toolkit, non tramite un caricatore LoRA generico impilato sopra. - Se stai debug in un grafo non-RC: evita di applicare un LoRA sopra pesi di diffusione Float8/FP8. Usa un percorso di caricamento BF16/FP16-compatibile per FLUX.2 prima di aggiungere il LoRA.
(2) Incongruenze di forma LoRA dovrebbero fallire rapidamente invece di corrompere lo stato della GPU e causare instabilità OOM/sistema#
Perché accade Questo è quasi sempre un mismatch di base: il LoRA è stato addestrato per una diversa famiglia di modelli (ad esempio FLUX.1) ma viene applicato a FLUX.2 Dev. Vedrai spesso molte righe lora key not loaded e poi incongruenze di forma; nel peggiore dei casi la sessione può diventare instabile e finire in OOM.
Come risolvere (consigliato)
- Assicurati che il LoRA sia stato addestrato specificamente per
black-forest-labs/FLUX.2-devcon AI Toolkit (le varianti FLUX.1 / FLUX.2 / Klein non sono intercambiabili). - Mantieni il grafo “single-path” per LoRA: carica l'adattatore solo tramite l'input
lora_pathdel workflow e lascia che Flux2Pipeline gestisca la fusione. Non impilare un ulteriore caricatore LoRA generico in parallelo. - Se hai già incontrato un mismatch e ComfyUI inizia a produrre errori CUDA/OOM non correlati successivamente, riavvia il processo ComfyUI per resettare completamente lo stato della GPU + modello, quindi riprova con un LoRA compatibile.
(3) Flux.2 Dev - L'uso di LoRA più che raddoppia il tempo di inferenza#
Perché accade Un LoRA può rendere FLUX.2 Dev molto più lento quando il percorso LoRA forza un lavoro di patching/dequantization extra o applica pesi in un percorso di codice più lento rispetto al solo modello base.
Come risolvere (consigliato)
- Usa il percorso RC FLUX.2 Dev (Flux2Pipeline) di questo workflow e passa il tuo adattatore tramite
lora_path/lora_scale. In questa configurazione, il LoRA è fuso una volta durante il caricamento della pipeline (stile AI Toolkit), quindi il costo di campionamento per passo rimane vicino al modello base. - Quando stai inseguendo un comportamento corrispondente all'anteprima, evita di impilare più caricatori LoRA o di mescolare percorsi di caricamento. Mantieni uno
lora_path+ unolora_scalefino a quando la base corrisponde.
Nota In questo workflow FLUX.2 Dev, FLUX.2 è guidance-distilled, quindi negative_prompt può essere ignorato dalla pipeline anche se esiste un campo UI—abbina le anteprime utilizzando le parole del prompt + guidance_scale + lora_scale prima.
Esegui FLUX.2 LoRA ComfyUI Inferenza ora#
Apri il workflow, imposta lora_path, e clicca Queue/Run per ottenere risultati FLUX.2 Dev LoRA che rimangono vicini alle tue anteprime di addestramento AI Toolkit.
