
Fish Audio S2 TTS per ComfyUI: TTS di alta qualità, clonazione vocale e dialoghi multi-locutore#
Fish Audio S2 TTS è un flusso di lavoro ComfyUI pronto all'uso che trasforma il testo in parlato naturale, clona una voce da un breve clip di riferimento e genera conversazioni multi-locutore. È alimentato dalla famiglia Fish Audio S2-Pro e supporta un ricco controllo dello stile tramite tag di emozione e prosodia come [excited], [whisper] e [laughing].
Questo flusso di lavoro è ideale per creatori, team di prodotto e sviluppatori che desiderano una sintesi vocale flessibile ed espressiva all'interno di ComfyUI. Include un'opzione di speech-to-text per la cattura rapida di trascrizioni, rilevamento automatico della lingua e scelte di precisione multiple tra cui fp8 e sage_attention per un'inferenza efficiente.
Nota: Esegui questo flusso di lavoro su una macchina 2X Large o più grande. Istanza più piccole potrebbero esaurire la memoria (OOM).
Modelli chiave nel flusso di lavoro Comfyui Fish Audio S2 TTS#
- Fish Audio S2-Pro — il modello generativo principale di text-to-speech utilizzato per TTS a singolo locutore, clonazione vocale e dialoghi multi-locutore. Supporta token di stile estesi e sintesi multilingue model card ed è parte del progetto Fish-Speech repo.
- Fish Audio S2-Pro FP8 — una variante efficiente in termini di memoria di S2-Pro che riduce le necessità di VRAM con compromessi di qualità minimi, consigliata per GPU vincolate model card.
- OpenAI Whisper large-v3 — un modello opzionale di speech-to-text usato per auto-trascrivere il tuo audio di riferimento quando prepari i prompt di clonazione vocale repo.
Come utilizzare il flusso di lavoro Comfyui Fish Audio S2 TTS#
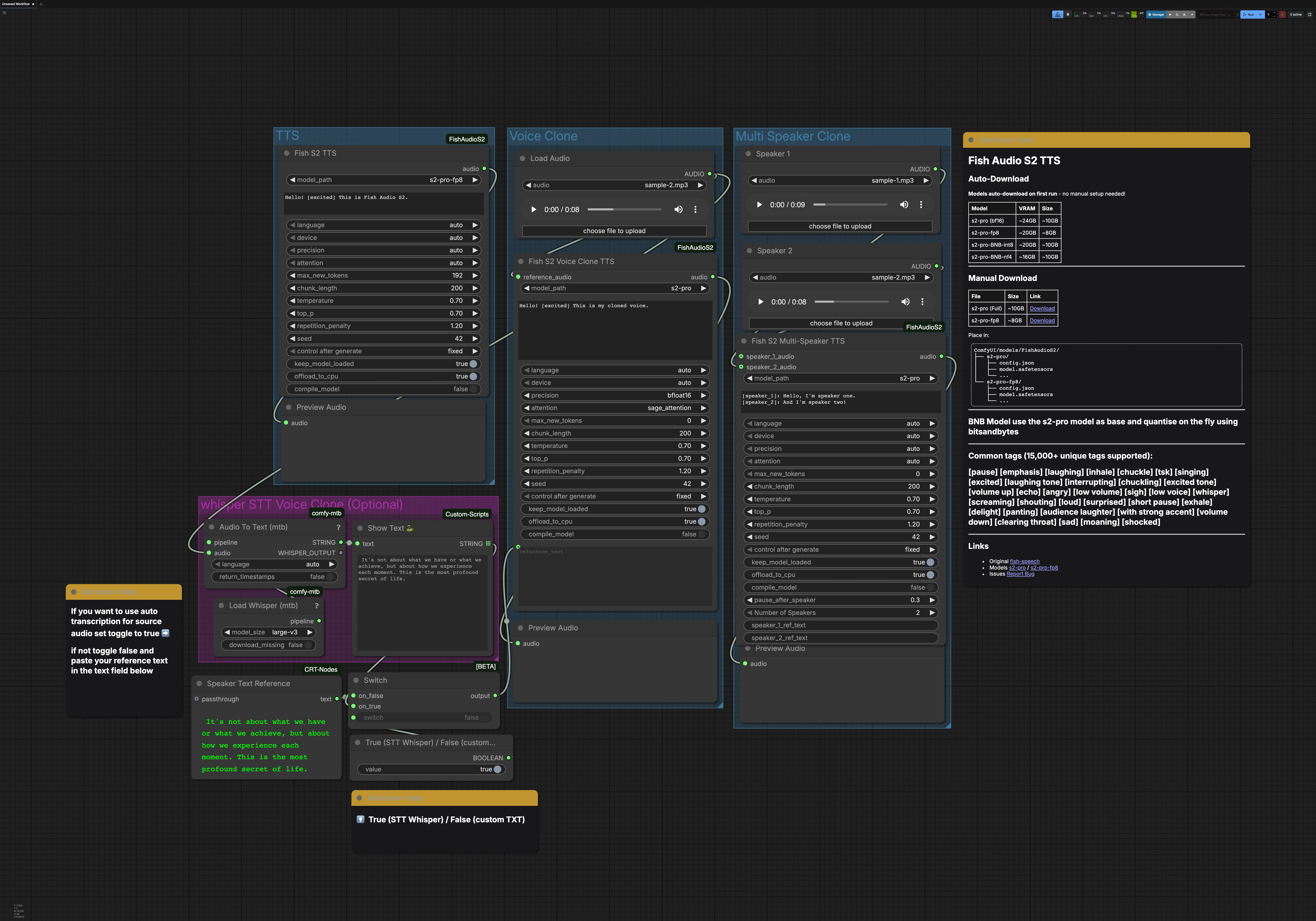
Questo flusso di lavoro contiene tre percorsi principali che possono essere eseguiti indipendentemente: TTS, Voice Clone e Multi Speaker Clone. Un gruppo Whisper STT opzionale può generare la trascrizione per la clonazione vocale. Ogni percorso termina con un'anteprima audio in modo da poter monitorare rapidamente i risultati.
Gruppo TTS#
Il nodo FishS2TTS (#42) esegue il text-to-speech diretto con Fish Audio S2 TTS. Inserisci il tuo script nella casella di testo del nodo e aggiungi tag di stile come [excited], [pause] o [whisper] per modellare emozioni e ritmo. Il rilevamento della lingua è automatico, quindi puoi scrivere nella lingua di destinazione e il modello si adatta. Scegli la variante S2-Pro che si adatta alla memoria della tua GPU, ad esempio fp8 per carichi più leggeri. L'output viene instradato a PreviewAudio per un ascolto istantaneo.
Gruppo Voice Clone#
Usa LoadAudio per fornire un breve clip di riferimento pulito della voce di destinazione, quindi instradalo in FishS2VoiceCloneTTS (#14). Fornisci la trascrizione che corrisponde allo stile di parlato che desideri; un testo accurato aiuta il modello a preservare il ritmo e l'accento. Puoi guidare il testo di riferimento dal gruppo STT o digitare il tuo, e puoi aggiungere tag di stile per affinare emozioni e consegna. Le scelte di precisione e attenzione bilanciano velocità, memoria e stabilità per linee lunghe. Il clone sintetizzato viene inviato a PreviewAudio in modo da poter iterare rapidamente.
Gruppo Multi Speaker Clone#
Carica un clip di riferimento per locutore utilizzando i nodi LoadAudio, quindi collegali a FishS2MultiSpeakerTTS (#41). Fornisci uno script di dialogo che etichetti ogni turno con [speaker_1], [speaker_2] e così via. Questo modello include due locutori per impostazione predefinita, e il nodo supporta la scalabilità fino a otto voci distinte quando configurato di conseguenza. Puoi mescolare prosa narrativa, tag e dialogo per controllare flusso ed emozione per ciascun personaggio. Il mix finale è visualizzato in anteprima in modo che il tempo e la chiarezza possano essere verificati.
Whisper STT per la clonazione vocale (opzionale)#
Load Whisper (mtb) (#6) con large-v3 alimenta Audio To Text (mtb) (#7) per trascrivere automaticamente un clip di riferimento. Il testo riconosciuto viene visualizzato da ShowText|pysssss (#8). Un piccolo interruttore costruito con ComfySwitchNode (#34) e un controllo booleano ti consente di scegliere tra l'output STT (vero) o il tuo testo digitato da Text Box line spot (#31) (falso). Questo è utile quando si desidera una trascrizione di base rapida o quando si crea un prompt preciso per la clonazione.
Nodi chiave nel flusso di lavoro Comfyui Fish Audio S2 TTS#
FishS2TTS (#42)#
Genera parlato a singolo locutore dal testo con tag di stile opzionali e rilevamento automatico della lingua. Regola la variante del modello per adattarla al tuo hardware, ad esempio scegliendo fp8 quando la VRAM è limitata. Usa il controllo del seme per ripetere le riprese e introduce piccoli cambiamenti quando esplori consegne alternative. Per script lunghi, seleziona un backend di attenzione ottimizzato per la stabilità.
FishS2VoiceCloneTTS (#14)#
Crea una voce clonata condizionando su reference_audio e reference_text. I migliori risultati provengono da discorsi puliti con tono coerente e una trascrizione che rispecchia il ritmo previsto. I tag di stile possono essere mescolati nel testo finale per guidare l'umore senza compromettere l'identità. Le impostazioni di precisione e attenzione aiutano a bilanciare qualità e memoria per linee estese.
FishS2MultiSpeakerTTS (#41)#
Sintetizza conversazioni multi-locutore abbinando l'audio di riferimento di ciascun locutore a un dialogo contrassegnato da etichette [speaker_n]. Aumenta il numero di locutori secondo necessità e assegna clip distinti per una separazione più forte. Mantieni il riferimento di ciascun locutore coerente nel tono per evitare mescolamenti. Usa il seme per un mix deterministico quando si rendono scene multi-take.
Extra opzionali#
- Usa i tag di stile con attenzione. Inizia con alcuni come [excited], [whisper], [emphasis], [pause], e costruisci solo se necessario per chiarezza.
- Per la clonazione vocale, taglia il silenzio dall'inizio e dalla fine del riferimento ed evita rumori di fondo per preservare il timbro.
- Se la memoria della GPU è limitata, preferisci S2-Pro fp8 o opzioni quantizzate a runtime. Per la massima fedeltà, usa una precisione più alta.
- La punteggiatura è importante. Virgole e punti migliorano la fraseggiatura, e i tag posizionati ai confini delle clausole tendono a suonare più naturali.
- Per script multi-locutore, mantieni un enunciato per riga e prefissa sempre con l'etichetta corretta [speaker_n] per mantenere la separazione.
Risorse:
- Model card di Fish Audio S2-Pro: Hugging Face
- Variante S2-Pro fp8: Hugging Face
- Progetto Fish-Speech: GitHub
- Nodi ComfyUI Fish Audio S2: GitHub
- Whisper large-v3: GitHub
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo sinceramente Saganaki22 per i ComfyUI-FishAudioS2 Custom Nodes, e Fish Audio per il modello S2-Pro per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
Nota: L'uso dei modelli, dataset e codice riferiti è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.