
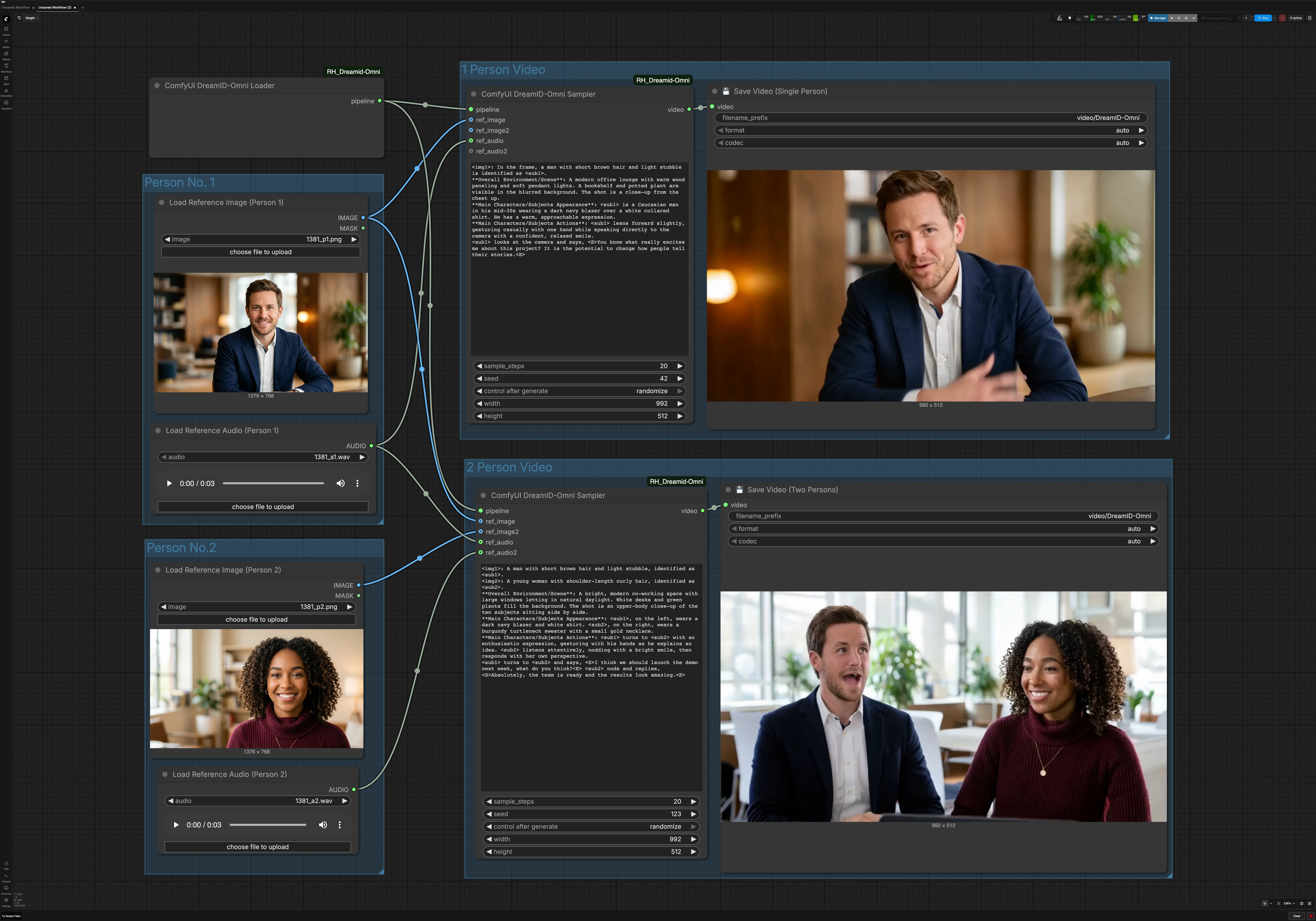
Workflow video parlante per personaggi singoli e doppi di DreamID-Omni per ComfyUI#
Questo workflow trasforma una singola foto di riferimento e una clip audio in un video parlante che preserva l'identità. Alimentato dal modello DreamID-Omni, mescola una moderna base video con un movimento delle labbra guidato da MMAudio in modo che il soggetto parli naturalmente mantenendo il volto della tua immagine. Supporta anche due personaggi, consentendo clip di conversazione affiancati guidati da due voci.
Progettato per creatori, team di prodotto e ricercatori, il workflow DreamID-Omni in ComfyUI è ideale per avatar digitali, annunci personalizzati, introduzioni di tutorial e scene di dialogo AI. Fornisci foto e audio, descrivi facoltativamente l'inquadratura in un breve prompt, e il grafico genera un video raffinato pronto per essere condiviso.
Modelli chiave nel workflow DreamID-Omni di ComfyUI#
- DreamID-Omni. Il modulo di identità centrale che preserva la persona nella tua immagine di riferimento attraverso i frame rispondendo all'audio per movimenti realistici delle labbra. Vedi il repository ufficiale e i pesi per i dettagli: DreamID-Omni e DreamID-Omni su Hugging Face.
- Wan 2.2 generazione video. Una base di diffusione video ad alta capacità che sintetizza movimento coerente, illuminazione e composizione dell'inquadratura mentre DreamID-Omni guida l'identità facciale.
- MMAudio. Un modello di rappresentazione audio che condiziona le forme della bocca e i sottili segnali facciali per allinearsi con il discorso fornito, migliorando il realismo della sincronizzazione labiale.
Come utilizzare il workflow DreamID-Omni di ComfyUI#
Questo grafico ha due percorsi paralleli. Il percorso per una persona utilizza un'immagine e un audio. Il percorso per due persone utilizza due immagini e due audio per produrre una clip di conversazione. Un caricatore DreamID-Omni condiviso inizializza la pipeline per entrambi.
Persona n. 1#
Usa Load Reference Image (Person 1) (#6) per selezionare un ritratto chiaro, frontale, con illuminazione uniforme e minima occlusione. Usa Load Reference Audio (Person 1) (#7) per fornire il discorso che vuoi che il personaggio dica. Un audio più pulito produce una migliore sincronizzazione labiale, quindi preferisci discorsi senza musica o rumori di fondo forti. Questo paio alimenta sia la modalità a una persona sia, quando abilitata, il soggetto a sinistra o il primo nella modalità a due persone.
Persona n. 2#
Usa Load Reference Image (Person 2) (#9) e Load Reference Audio (Person 2) (#11) quando crei un dialogo. Scegli una foto che corrisponda all'inquadratura della Persona 1 per mantenere la composizione equilibrata. Assicurati che il secondo audio sia simile in volume al primo per evitare bruschi cambiamenti percettivi. Se stai creando una clip per una sola persona, puoi ignorare questo gruppo.
Video per 1 Persona#
Il percorso per un singolo oratore è guidato da ComfyUI DreamID-Omni Sampler (#21). Fonduisce la pipeline DreamID-Omni con la foto e l'audio della Persona 1, quindi rende un'inquadratura coerente con la tua breve descrizione della scena nell'area del prompt del nodo. Mantieni il tuo prompt conciso e pratico, ad esempio descrivendo lo sfondo, la distanza della fotocamera e l'atteggiamento. Il risultato è scritto da 💾 Save Video (Single Person) (#4), che nomina ed esporta il file per te.
Video per 2 Persone#
Il percorso di dialogo utilizza ComfyUI DreamID-Omni Sampler (#22) per comporre due identità in un solo frame e guidare ciascuna bocca con il suo audio associato. Fornisci un breve prompt per impostare l'ambiente e lo stile di interazione, come uno spazio di co-working, tono informale o chi parla per primo. Questo aiuta a stabilizzare il posizionamento della fotocamera e i gesti mentre DreamID-Omni e MMAudio mantengono l'identità e l'allineamento delle labbra. La clip è esportata da 💾 Save Video (Two Persons) (#5).
Pipeline condivisa DreamID-Omni#
ComfyUI DreamID-Omni Loader (#23) inizializza i componenti DreamID-Omni utilizzati da entrambi i percorsi. Normalmente non è necessario regolare nulla qui. Finché i pesi e il nodo ComfyUI sono disponibili, il loader prepara la pipeline in modo che i campionatori possano rendere.
Nodi chiave nel workflow DreamID-Omni di ComfyUI#
ComfyUI DreamID-Omni Loader (#23)#
Inizializza la pipeline DreamID-Omni e rende disponibili i suoi pesi ai campionatori a valle. Non ci sono input tipici dell'utente qui. Se mantieni più varianti di modello, conferma che i pesi corretti sono installati prima di mettere in coda i rendering.
ComfyUI DreamID-Omni Sampler (#21)#
Rendering per una persona. Questo nodo combina la pipeline del loader con la prima immagine di riferimento e l'audio per sintetizzare una testa parlante che preserva l'identità. Il campo del prompt è dove definisci la scena e l'atteggiamento; il seed controlla la ripetibilità; la risoluzione determina l'inquadratura e i dettagli del volto; e i passi scambiano velocità per fedeltà. Per risultati coerenti tra i take, riutilizza lo stesso seed e mantieni i cambiamenti dei prompt minimi.
ComfyUI DreamID-Omni Sampler (#22)#
Rendering per due persone. Questa istanza accetta due foto e due audio, abbinando ogni voce al suo soggetto per un movimento delle labbra sincronizzato. Il prompt può inscenare la conversazione e il layout della fotocamera. Regola il seed e la risoluzione come faresti in modalità per una persona, e assicurati che entrambi gli audio siano tagliati al tempo desiderato prima del rendering.
💾 Save Video (Single Person) (#4)#
Scrive l'output dell'oratore singolo su disco. Imposta la cartella o il nome base per mantenere organizzate le versioni. Se disponibile, lascia le opzioni di codec e frame-rate su automatico quando non sei sicuro.
💾 Save Video (Two Persons) (#5)#
Scrive l'output del dialogo su disco. Usa un nome base distinto in modo che i clip a una e due persone siano facili da distinguere. Mantieni le impostazioni di esportazione automatiche per affidabilità a meno che tu non abbia un requisito di consegna specifico.
Extra opzionali#
- Mantieni i volti abbastanza grandi nelle immagini di riferimento per occupare una porzione significativa del frame per un blocco di identità più forte.
- Usa audio di discorso pulito e ben livellato. Taglia i silenzi all'inizio per evitare labbra congelate iniziali.
- Per un aspetto più stabile, riutilizza lo stesso seed quando iteri su prompt o outfit.
- Se lo spazio per due persone sembra stretto, riformula il prompt per allargare la fotocamera o aumentare lo spazio per le spalle piuttosto che ritagliare i volti.
- Per risorse e aggiornamenti, vedi il modello ufficiale e il nodo: DreamID-Omni, ComfyUI_RH_Dreamid-Omni, e DreamID-Omni weights.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Riconosciamo con gratitudine Guoxu1233 per il modello/workflow DreamID-Omni, HM-RunningHub per il nodo ComfyUI DreamID-Omni, e XuGuo699 per i pesi del modello DreamID-Omni per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Repository ufficiale DreamID-Omni - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- Nodo ComfyUI DreamID-Omni (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- Pesi del modello DreamID-Omni (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.